Podstawy#
Drzewo węzłów#
W ujęciu matematycznym drzewem (tree) [WikiEN|WikiPL], zgodnie z teorią grafów (graph theory) [WikiEN|WikiPL], jest graf nieskierowany (graph undirected) [WikiEN|WikiPL], który jest acykliczny i spójny, co oznacza, że z każdego wierzchołka drzewa można dotrzeć do każdego innego wierzchołka (spójność) i tylko jednym sposobem (acykliczność, brak możliwości chodzenia "w kółko").
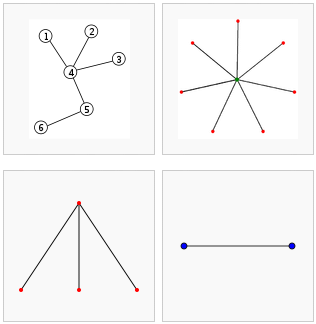
Rysunek. Różne warianty drzew
W kontekście informatycznym drzewa stanowią abstrakcyjny typ danych (abstract data type) [WikiEN|WikiPL] lub strukturę danych (data structure) [WikiEN|WikiPL], która implementuje ten abstrakcyjny typ danych. W naturalny sposób przedstawiają hierarchię danych (obiektów fizycznych i abstrakcyjnych, pojęć, itp.), są więc stosowane głównie do tego celu. Drzewa ułatwiają i przyspieszają wyszukiwanie, a także pozwalają w łatwy sposób operować na posortowanych danych. Znaczenie tych struktur jest bardzo duże i ze względu na swoje własności drzewa są stosowane praktycznie w każdej dziedzinie informatyki (np. bazy danych, grafika komputerowa, przetwarzanie tekstu, telekomunikacja).
W dalszej części skupimy się raczej na aspektach czysto webowych. Dla osób początkujących szersza analiza koncepcji drzewa nie jest niezbędna do swobodnego operowania poleceniami DOM. Przejdźmy zatem do konkretów.
Budowa drzewa#
Według W3C każdy dokument bazujący na językach znacznikowych (markup-based) można wyrazić za pomocą hierarchicznej struktury zwanej drzewem węzłów # (node tree). Składnikami takiego drzewa są węzły # (nodes). Aktualna specyfikacja DOM4 definiuje 7 rodzajów węzłów, przykładowo element, ciąg tekstowy, komentarz, itd. Każdy węzeł może mieć jednego rodzica (oprócz korzenia), dowolną ilość braci i, jeśli jest elementem, to dowolną ilość dzieci.
Zrozumienie budowy drzewa węzłów oraz zależności między węzłami będzie kluczowe przy dalszej pracy z takimi technologiami webowymi jak JavaScript, DOM i CSS. Najważniejszą kwestią jest relacja między węzłami # (relationship between nodes), ponieważ pozwala ona na swobodne poruszanie się po drzewie węzłów w celu wyboru konkretnego węzła lub węzłów. Całe zagadnienie omówione zostanie na bazie ogólnej reprezentacji drzewa węzłów zgodnego z modelem DOM, które przedstawia poniższa grafika: #
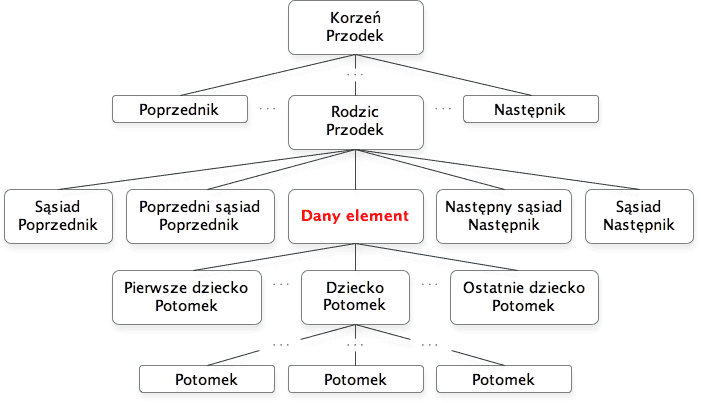
Rysunek. Przykładowe drzewo węzłów w modelu DOM
Należący (participates)
Rodzic (parent)
Każdy obiekt należący # (participates) do drzewa węzłów posiada rodzica # (parent), którym będzie inny obiekt lub wartość null, i który zawierać może uporządkowaną listę z zerem lub większą liczbą obiektów zwanych dziećmi.
Dziecko (child)
Dzieckiem # (child) będzie każdy obiekt, który posiada rodzica. Obiekt A, którego rodzicem jest obiekt B, jest dzieckiem dla B.
Korzeń (root)
Korzeniem # (root) dla danego obiektu będzie on sam, jeśli jego rodzicem jest wartość null, w przeciwnym razie jest nim korzeń jego rodzica. Korzeniem w drzewie węzłów jest obiekt należący do tego drzewa węzłów, którego rodzicem jest wartość null.
Potomek (descendant)
Obiekt A nazywany jest potomkiem # (descendant) obiektu B, jeśli A jest dzieckiem obiektu B lub jeśli A jest dzieckiem obiektu C, który jest potomkiem obiektu B. Upraszczając sprawę mówimy, że dziecko znajduje się zawsze o jeden poziom niżej w hierarchii drzewa węzłów i może być nazywane potomkiem. Jeśli potomek położony jest o dwa lub więcej poziomów niżej w hierarchii drzewa węzłów to nie może być już nazywany dzieckiem.
Potomek obejmujący (inclusive descendant)
Potomkiem obejmującym # (inclusive descendant) dla danego obiektu będzie on sam lub jeden z jego potomków.
Przodek (ancestor)
Obiekt A nazywany jest przodkiem # (ancestor) obiektu B, wtedy i tylko wtedy, gdy B jest potomkiem dla obiektu A. Upraszczając sprawę mówimy, że przodek będzie położony o jeden lub więcej szczebli wyżej w hierarchii drzewa węzłów.
Przodek obejmujący (inclusive ancestor)
Przodkiem obejmującym # (inclusive ancestor) dla danego obiektu będzie on sam lub jeden z jego przodków.
Brat (sibling)
Obiekt A nazywany jest bratem # (sibling) obiektu B, wtedy i tylko wtedy, gdy obiekty B i A mają tego samego rodzica, którym nie jest wartość null. Upraszczając sprawę mówimy, że bracia znajdują się na tym samym poziomie zagnieżdżenia w hierarchii drzewa węzłów.
Bratem obejmującym (inclusive ancestor)
Bratem obejmującym # (inclusive sibling) dla danego obiektu będzie on sam lub jeden z jego braci.
W zastępstwie "brata" bardzo często stosuje się analogiczne określenia typu "rodzeństwo", "sąsiad" czy "rówieśnik".
Poprzednik (preceding)
Obiekt A nazywany jest poprzednikiem # (preceding) obiektu B jeśli obiekty A i B należą do tego samego drzewa węzłów i obiekt A znajduje się, zgodnie z porządkiem drzewa, przed obiektem B.
Następnik (following)
Obiekt A nazywany jest następnikiem # (following) obiektu B jeśli obiekty A i B należą do tego samego drzewa węzłów i obiekt A znajduje się, zgodnie z porządkiem drzewa, za obiektem B.
Pierwsze dziecko (first child)
Pierwszym dzieckiem # (first child) dla danego obiektu będzie jego pierwsze dziecko lub, jeśli obiekt nie ma dzieci, to wartość null.
Ostatnie dziecko (last child)
Ostatnim dzieckiem # (last child) dla danego obiektu będzie jego ostatnie dziecko lub, jeśli obiekt nie ma dzieci, to wartość null.
Brat poprzedzający (previous sibling)
Bratem poprzedzającym # (previous sibling) dla danego obiektu będzie jego pierwszy poprzednik bratowy # (preceding sibling), czyli obiekt spełniający wymagania poprzednika i brata lub, jeśli obiekt nie ma poprzednika bratowego, to wartość null.
Brat następujący (next sibling)
Bratem następującym # (next sibling) dla danego obiektu będzie jego pierwszy następnik bratowy # (following sibling), czyli obiekt spełniający wymagania następnika i brata lub, jeśli obiekt nie ma następnika bratowego, to wartość null.
Indeks (index)
Indeksem # (index) w danym obiekcie będzie liczba jego poprzedników bratowych.
Rodzaje węzłów#
Każdy węzeł w drzewie węzłów jest reprezentowany przez ogólny interfejs Node. Na przestrzeni lat różne specyfikacje DOM zdefiniowały w sumie 12 dodatkowych, bardziej wyspecjalizowanych interfejsów węzłowych dziedziczących po Node, co skutkuje podziałem węzłów na poszczególne rodzaje|typy # (type). Od typu węzła uzależnione są następujące kwestie:
- Dostęp do specyficznych poleceń definiowanych wyłącznie dla danego rodzaju węzła.
- Ściśle scharakteryzowana dopuszczalna zawartość dla danego rodzaju węzła.
- Ściśle scharakteryzowane zachowanie dla każdego polecenia operującego na różnych rodzajach węzłów.
Istnieje kilka sposobów pozwalających ustalić rodzaj danego węzła:
- Poprzez właściwość
Node.nodeType, która przechowuje liczbę całkowitą zależną od typu węzła (wartości od1do12). - Poprzez właściwość
Node.nodeName, która dla pięciu typów węzłów przechowuje niezmienny łańcuch znakowy, tj. "#text", "#cdata-section", "#comment", "#document" oraz "#document fragment". - Poprzez sprawdzenie konstruktora tworzącego dany węzeł.
- Poprzez sprawdzenie obecności jakiegoś specyficznego polecenia występującego tylko w danym węźle.
Wraz z upływem lat okazało się jednak, że tak duża liczba różnych węzłów jest zbyteczna. Mało która przeglądarka internetowa wdrożyła wszystkie ich rodzaje (chyba tylko Opera na Presto), co w rzeczywistości umożliwiło przeprowadzenie pewnych korekt w aktualnych implementacjach, bez obawy o kompatybilność wsteczną. W ramach uproszczenia platformy webowej obecna specyfikacja DOM4 pozostawiła jedynie 7 rodzajów węzłów # reprezentowanych przez następujące interfejsy (z ewentualnym uwzględnieniem interfejsów dziedziczących po nich): Element, Text, ProcessingInstruction, Comment, Document, DocumentType oraz DocumentFragment.
Wciąż nierozstrzygniętą kwestią pozostają plany zerwania z węzłowym charakterem w przypadku atrybutów oraz sekcji CDATA.
W poniższej tabeli zebrałem najważniejsze informacje charakteryzujące każdy rodzaj węzła. W dalszej części kursu wszystkie przestarzałe węzły oznaczyłem za pomocą znaku gwiazdki *, a informacje na ich temat mają charakter wyłącznie historyczny.
| Typ węzła | nodeType | nodeName | nodeValue | Odpowiadająca stała |
|---|---|---|---|---|
Element | 1 | Nazwa kwalifikowana | null | ELEMENT_NODE |
Attr* | 2 | Nazwa kwalifikowana | Wartość | ATTRIBUTE_NODE |
Text | 3 | "#text" | Dane tekstowe | TEXT_NODE |
CDATASection* | 4 | "#cdata-section" | Dane tekstowe | CDATA_SECTION_NODE |
EntityReference* | 5 | Nazwa | null | ENTITY_REFERENCE_NODE |
Entity* | 6 | Nazwa | null | ENTITY_NODE |
ProcessingInstruction | 7 | Cel | Dane tekstowe | PROCESSING_INSTRUCTION_NODE |
Comment | 8 | "#comment" | Dane tekstowe | COMMENT_NODE |
Document | 9 | "#document" | null | DOCUMENT_NODE |
DocumentType | 10 | Nazwa | null | DOCUMENT_TYPE_NODE |
DocumentFragment | 11 | "#document fragment" | null | DOCUMENT_FRAGMENT_NODE |
Notation* | 12 | Nazwa | null | NOTATION_NODE |
Właściwości Node.nodeType, Node.nodeName oraz Node.nodeValue są dziedziczone przez poszczególne węzły z ogólnego interfejsu Node, ale zwracają wartości zależne od danego rodzaju węzła. Z węzłów można odczytać dowolną stałą, chociaż one również znajdują się w interfejsie Node. Mamy więc klasyczny schemat dziedziczenia.
Prosty przykład:
<script>
var doc = document; // referencja do dokumentu
var elHTML = doc.documentElement; // referencja do elementu
doc.write(doc.nodeType + " | " + doc.nodeName + " | " + doc.nodeValue); // 9 | #document | null
doc.write("<br>");
doc.write(elHTML.nodeType + " | " + elHTML.nodeName + " | " + elHTML.nodeValue); // 1 | HTML | null
doc.write("<br>");
doc.write(doc.DOCUMENT_NODE + " | " + doc.ELEMENT_NODE); // 9 | 1
doc.write("<br>");
doc.write(Node.DOCUMENT_NODE + " | " + Node.ELEMENT_NODE); // 9 | 1
</script>Dopuszczalna zawartość węzłów#
Typ węzła determinuje jego dopuszczalną zawartość w postaci innych węzłów, które z perspektywy drzewa węzłów stanowią jego dzieci. Jest to szczególnie istotne dla parsera XML oraz niektórych metod modyfikujących drzewo węzłów, np. Node.appendChild() czy Node.insertBefore(), ponieważ są one wyczulone na wszelkie nieprawidłowości i w razie niespełnienia określonych warunków z algorytmu gwarantującego poprawność przed wstawieniem zawsze zrzucają błąd. Inaczej wygląda sytuacja w przypadku parsera HTML, który w ten czy inny sposób potrafi skorygować wszelkie napotkane błędy.
W poniższej tabeli umieściłem dopuszczalną zawartość dla wszystkich do tej pory zdefiniowanych rodzajów węzłów, co jest zgodne z aktualną specyfikacją DOM4, jak i poprzednimi wersjami specyfikacji DOM2 i DOM3.
| Typ węzła | Dopuszczalna zawartość (dzieci) |
|---|---|
Document | Zgodna z porządkiem drzewa:
|
DocumentFragment | Zero lub więcej węzłów typu Element, ProcessingInstruction, Comment, Text, CDATASection*, EntityReference* |
DocumentType | Brak |
Element | Zero lub więcej węzłów typu Element, ProcessingInstruction, Comment, Text, CDATASection*, EntityReference* |
ProcessingInstruction | Brak |
Comment | Brak |
Text | Brak |
Attr* | Zero lub więcej węzłów typu Text, EntityReference* |
CDATASection* | Brak |
Entity* | Zero lub więcej węzłów typu Element, ProcessingInstruction, Comment, Text, CDATASection*, EntityReference* |
EntityReference* | Zero lub więcej węzłów typu Element, ProcessingInstruction, Comment, Text, CDATASection*, EntityReference* |
Notation* | Brak |
Widać wyraźnie, że niektóre węzły nie posiadają żadnej zawartości (np. Comment czy Text), dozwolony jest pojedynczy DocumentType tylko i wyłącznie w określonym miejscu dokumentu, a DocumentFragment jest o tyle specyficzny, że nie zawiera się bezpośrednio w żadnym innym węźle.
Przechodzenie po drzewie#
Przechodzenie po drzewie # (tree traversal) [WikiEN|WikiPL] to w informatyce proces odwiedzania wszystkich węzłów w drzewie węzłów. Warto napisać kilka słów na jego temat ponieważ w różnych specyfikacjach W3C często pojawiają się zwroty typu: tree order, preorder czy depth-first traversal.
Chcąc odwiedzić wszystkie węzły w drzewie węzłów można zastosować kilka znanych algorytmów wywoływanych rekurencyjnie:
- Depth-first (przejście wzdłuż)
- Pre-order (
root, left, right)- Odwiedź korzeń
- Przejdź przez lewe poddrzewo
- Przejdź przez prawe poddrzewo
- In-order (
left, root, right)- Przejdź przez lewe poddrzewo
- Odwiedź korzeń
- Przejdź przez prawe poddrzewo
- Post-order (
left, right, root)- Przejdź przez lewe poddrzewo
- Przejdź przez prawe poddrzewo
- Odwiedź korzeń
- Pre-order (
- Breadth-first (przejście wszerz)
- Level-order
- Odwiedź każdy węzeł na poziomie zanim przejdziesz do niższego poziomu
- Level-order
Zamiast zawiłych regułek najlepiej przeanalizować wszystko na poniższym grafie drzewa binarnego # (binary tree) [WikiEN|WikiPL]:
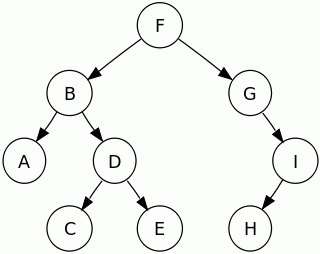
Rysunek. Przykładowe drzewo binarne
W tym drzewie binarnym podstawowe algorytmy odwiedzają węzły w następującej kolejności:
- Pre-order (
root, left, right): F, B, A, D, C, E, G, I, H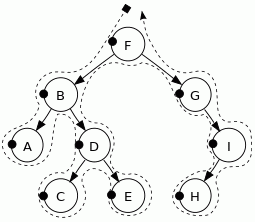
- In-order (
left, root, right): A, B, C, D, E, F, G, H, I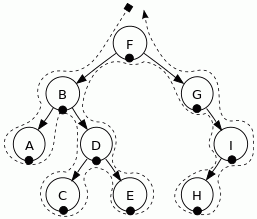
- Post-order (
left, right, root): A, C, E, D, B, H, I, G, F
- Level-order: F, B, G, A, D, I, C, E, H
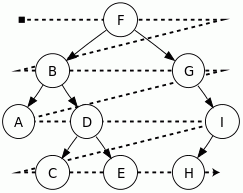
Porządek drzewa (tree order)
W przypadku wielu specyfikacji webowych (włącznie z DOM i HTML) stosowany jest termin porządek drzewa # (tree order) wykorzystujący przy przechodzeniu po drzewie węzłów algorytm pre-order typu depth-first. Wiedza taka będzie pomocna przy wyjaśnianiu wielu terminów oraz poleceń operujących na węzłach.
Praktyczne przełożenie#
Przeanalizujmy jeden rzeczywisty przykład drzewa węzłów, który powinien nieco rozjaśnić całe zagadnienie. Załóżmy, że mamy do czynienia z następującą strukturą znacznikową:
<div> <!-- Węzeł 1 (korzeń) -->
Pierwszy blok tekstowy w DIV <!-- Węzeł 2 -->
<p> <!-- Węzeł 3 -->
Pierwszy blok tekstowy w P <!-- Węzeł 4 -->
<strong> <!-- Węzeł 5 -->
Pierwszy blok tekstowy w STRONG <!-- Węzeł 6 -->
</strong>
<!-- Węzeł 7 (białe znaki) -->
<i> <!-- Węzeł 8 -->
Pierwszy blok tekstowy w I <!-- Węzeł 9 -->
</i>
Drugi blok tekstowy w P <!-- Węzeł 10 -->
</p>
Drugi blok tekstowy w DIV <!-- Węzeł 11 -->
<hr /> <!-- Węzeł 12 -->
<!-- Węzeł 13 (białe znaki) -->
</div>Jeśli zaczniemy przechodzić przez drzewo węzłów z korzeniem <div>, zgodnie z porządkiem drzewa, to otrzymamy kolejne węzły zgodnie z opisami zawartymi w komentarzach. W ramach uproszczenia komentarzy nie zaliczamy do węzłów i całkowicie pomijamy przy analizie tego przykładu, mają jedynie charakter informacyjny.
Do przechodzenia po kolejnych węzłach w drzewie węzłów najprościej zastosować iteratora węzłowego. Przejdźmy po naszym przykładowym drzewie węzłów i sprawdźmy, czy oznaczona w nim kolejność węzłów się zgadza:
<!DOCTYPE html>
<html>
<head>
<script>
function iterate(direct){
var info = document.getElementById("info");
var root = document.getElementById("box");
var dir = "";
var node = "";
var nodeText = "";
if (typeof iterator != "object"){
iterator = document.createNodeIterator(root, NodeFilter.SHOW_ALL, null);
}
if (direct == "next"){
node = iterator.nextNode();
dir = "nextNode()";
}
if (direct == "previous"){
node = iterator.previousNode();
dir = "previousNode()";
}
if (node){
nodeText = node.textContent;
}
var result = "pointerBeforeReferenceNode: " + iterator.pointerBeforeReferenceNode
+ "<br><br>" + "referenceNode: " + iterator.referenceNode
+ "<br>" + "referenceNode.textContent: " + iterator.referenceNode.textContent
+ "<br><br>" + dir + ": " + node
+ "<br>" + dir + ".textContent: " + nodeText;
info.innerHTML = result;
}
</script>
</head>
<body>
<div id="box">
Pierwszy blok tekstowy w DIV.
<p>
Pierwszy blok tekstowy w P.
<strong>
Pierwszy blok tekstowy w STRONG.
</strong>
<i>
Pierwszy blok tekstowy w I.
</i>
Drugi blok tekstowy w P.
</p>
Drugi blok tekstowy w DIV.
<hr />
</div>
<p>Kliknij konkretny przycisk by iterować przez kolejne węzły w kontenerze DIV.</p>
<input type="button" value="nextNode()" onclick="iterate('next')">
<input type="button" value="previousNode()" onclick="iterate('previous')">
<p style="color: blue;">Szczegółowe informacje dla kolejnych przejść iteratora:</p>
<p id="info"></p>
</body>
</html>Przechodząc przez kolejne węzły widzimy, że maksymalnie mamy dostęp do 13 węzłów, zwracanych w tej samej kolejności, jaka opisana została w komentarzach naszej pierwotnej struktury znacznikowej.
W razie konieczności można zaimplementować swój własny algorytm przechodzenia po drzewie węzłów. Można w tym celu zastosować kod bazujący na iteracjach (pętle) lub rekurencjach (funkcje) w połączeniu z właściwościami dostępnymi dla każdego rodzaj węzła.
Implementacja w przeglądarkach#
Zanim przejdę dalej wypadałoby wyjaśnić kilka podstawowych kwestii z pogranicza ECMAScript i DOM, które się zazębiają, a które mogą być trudne do zrozumienia przez początkujących.
Każde środowisko uruchomieniowe ECMAScript (określane jako gospodarz lub host) musi zapewnić obiekt globalny pod zmienną this, dostępną poza jakąkolwiek funkcją. W obiekcie tym znajdują się wszystkie właściwości oraz metody globalne (pochodzące z samego rdzenia języka ECMAScript oraz od gospodarza) jak i nasze zmienne i metody globalne pochodzące ze wszystkich jednostek kompilacji (czyli znaczników <script>). Niestety, JavaScript nie ma narzędzia linkującego, dlatego wszystko to trafia do jednego obiektu globalnego, co jest niedobrą cechą języka, no ale tak już jest.
W przeglądarkach internetowych obiekt globalny posiada właściwość window, która tak naprawdę wskazuje na niego samego, czyli this.window = this. W różnych środowiskach właściwość ta może mieć inną nazwę, a nawet może w ogóle nie występować, dlatego należy ostrożnie podchodzić do wskazywania obiektu globalnego przy użyciu konkretnej nazwy.
Dla rozjaśnienia tematu zadeklarujmy funkcję wypisz() w przestrzeni globalnej. Można się później do niej odwołać na kilka sposobów:
<script>
function wypisz(){
document.write("Cześć" + "<br>");
}
wypisz(); // Cześć
this.wypisz(); // Cześć
this.window.wypisz(); // Cześć
window.wypisz(); // Cześć
document.write(window); // [object Window]
document.write("<br>");
document.write(this == window); // true
document.write("<br>");
document.write(this.window == window); // true
</script>Z początku może wydawać się to skomplikowane, ale w praktyce pozwala pominąć poprzedzające odwołania do wszystkiego, co umieszczone w globalnej przestrzeni, gdyż są one zbędne i niepotrzebnie rozwlekają kod. Mogą też mieć wpływ na wydajność (w starszych przeglądarkach), ponieważ każde dookreślenie (kropka) odpowiada za przeszukiwanie zagnieżdżonych obiektów. Reasumując, wystarczy sama nazwa globalnej właściwości, funkcji, zmiennej itd.
Obiekt window możemy potraktować jak całe okno przeglądarki. Dopiero w nim znajduje się obiekt document, który reprezentuje każdy dokument XML oraz HTML. W obiekcie document zawarte będą informacje na temat każdego węzła, a jeśli tworzony będzie w przeglądarce może też posiadać inne cechy (np. adres, ciasteczka, tytuł itp.). W obiekcie document znajdować się będzie korzeń dokumentu. W przypadku dokumentów (X)HTML korzeniem będzie obiekt html. Warto zauważyć, że można swobodnie przejść z html do document (gdyż obydwa obiekty są częścią tego samego drzewa węzłów). Przejście z document do window nie jest już możliwe.
Kilka przypadków testowych:
<script>
document.write(window + "<br>"); // [object Window]
document.write(document + "<br>"); // [object HTMLDocument]
document.write(document.documentElement + "<br>"); // [object HTMLHtmlElement]
document.write(document.documentElement.parentNode + "<br>"); // [object HTMLDocument]
document.write(document.parentNode + "<br>"); // null
</script>Dla jeszcze lepszego zobrazowania całości najlepiej przeanalizować następującą strukturę znacznikową:
<!DOCTYPE html>
<html>
<head>
<title>Przykład</title>
</head>
<body>
<p>Treść akapitu.</p>
<div><strong>Wyróżniona treść</strong> wewnątrz kontenera.</div>
</body>
</html>Struktura DOM (wygenerowana za pomocą świetnego narzędzia Live DOM Viewer) dla naszego przykładu będzie postaci:
- DOCTYPE:
html HTMLHEAD#text: *TITLE#text: Przykład
#text: *
#text: *BODY#text: *P#text: Treść akapitu.
#text: *DIVSTRONG#text: Wyróżniona treść
#text: wewnątrz kontenera.
#text: *
#Trzeba zwracać uwagę na fakt, że w drzewie DOM pojawiają się węzły tekstowe, które mogą być wstawiane bez naszej zamierzonej/świadomej ingerencji. Oznaczyłem je poprzez gwiazdkę (*). Pisałem już o tym we wstępie do HTML5. Przy iteracji po kolekcjach (zawierających wszystkie rodzaje węzłów) zazwyczaj będziemy chcieli/musieli pomijać takie domyślne wstawki.
Każdy węzeł w drzewie DOM jest reprezentowany w JavaScript przez obiekt. Wszystkie obiekty mają zdefiniowane API (zgodne z tymi opisanymi przez specyfikację DOM), dzięki którym można je modyfikować. Trzeba tutaj odróżniać samo drzewo węzłów (jako coś teoretycznego, obrazującego relację między węzłami drzewa) oraz przełożenie/implementację tego drzewa w danym środowisku (np. struktura obiektowa w JavaScript).
O samym JavaScripcie jako języku programowania można napisać dwie kluczowe definicje: #
- jest to język obiektowy
- jest to język zorientowany obiektowo
Pierwsze określenie jest dyskusyjne. Co prawda JavaScript ma obiekty, możemy je tworzyć/zmieniać itd., ale brakuje mu wielu rzeczy wywodzących się z prawdziwych języków obiektowych (np. klas, metod prywatnych, publicznych, uprzywilejowanych itp.). Ze względu na dużą elastyczność i ekspresyjność języka wiele z tych braków można uzyskać w inny sposób, stosując jedynie pierwotne elementy składowe języka. Kolejne wersje ECMAScript na bieżąco starają się uzupełniać różne braki - spore zmiany szykują się w szóstym wydaniu standardu. Prawdę powiedziawszy prosta składnia języka oferująca możliwość jego samodzielnego rozszerzania jest lepsza niż stosy gotowych poleceń.
Druga sprawa jest bezdyskusyjna, co można zaobserwować po opisach i przykładach umieszczonych w kursie. W zasadzie wszystko, co zauważysz w kodzie języka JS, ma sporą szansę być obiektem. Jedynie pięć typów podstawowych nie jest obiektami: liczba, ciąg znaków, wartość logiczna, null i undefined. Dodatkowo pierwsze trzy mają swoje obiektowe reprezentacje i mogą zostać łatwo zamienione w obiekt przez programistę - metody Number(), String(), Boolean() - a czasem są nawet zamieniane automatycznie przez interpreter języka. Obiekty są umieszczane w innych obiektach tworząc zwięzłą strukturę danych.
Wszystkie obiekty w JavaScripcie można podzielić na dwie główne grupy: #
- rdzenne - zdefiniowane w standardzie ECMAScript. Są one niezależne od środowiska uruchomieniowego.
Dzielą się na:
- wbudowane - konkretne obiekty opisane w ECMAScript, np.
Object,Array,Dateitd. - własne - dowolne obiekty tworzone przez nas samych, np. za pomocą literału
var o = {};.
- wbudowane - konkretne obiekty opisane w ECMAScript, np.
- gospodarza - zdefiniowane w środowisku uruchomieniowym, np. w przeglądarce internetowej będą to obiekty BOM, DOM i inne.
Obiekty gospodarza będą specyficzne. Co prawda umożliwiają one rozszerzanie ich w pewnym zakresie, ale nie jest to w żaden sposób standaryzowane przez jakąkolwiek specyfikację i może być w różny sposób udostępniane przez każdy program. W praktyce możliwości ich zmiany będą obwarowane wieloma ograniczeniami i "dziwnymi" zachowaniami, różniącymi się nieco od standaryzowanych rozwiązań ECMAScript.
Praca z wieloma dokumentami i drzewami węzłów jednocześnie#
Programując w środowisku jakim jest przeglądarka internetowa będziemy mieli do czynienia z wieloma rodzajami drzew węzłów. Jest to pojęcie zbyt ogólne, dlatego warto wprowadzić kilka konkretyzujących terminów.
Podział na wiele rodzajów drzew węzłów został wprowadzony przeze mnie osobiście w celu uproszczenia opisów różnych poleceń DOM w dalszej części kursu. Chociaż może nie być w 100% prawidłowy, z praktycznego punktu widzenia pozwala połączyć ze sobą wiele pojęć, takich jak:
- Drzewo węzłów - czyli wszystko to, co tworzy hierarchiczną strukturę węzłów.
- Drzewo węzłów z tym samym właścicielem - czyli wszystko to, co bezpośrednio lub pośrednio należy do tego samego obiektu reprezentującego dokument.
- Drzewo węzłów poza drzewem dokument - czyli wszystko to, co bezpośrednio nie należy do obiektu reprezentującego dokument.
- Drzewo dokument - czyli wszystko to, co bezpośrednio należy do obiektu reprezentującego dokument.
- Aktywne drzewo dokumentu - czyli drzewo dokumentu, które umieszczone jest w bieżącym oknie lub ramkach.
- Drzewo renderowania - czyli wszystko to, co zostanie wyświetlone z aktualnego drzewa dokumentu.
- metody i właściwości - specyficzne polecenia dostępne dla danego węzła w drzewie węzłów.
Drzewo węzłów
Drzewem węzłów # będzie każde drzewo, którego elementami są węzły opisywane w specyfikacji DOM. Może być to drzewo dokumentu, aktualne drzewo dokumentu, drzewo węzłów poza dokumentem itd. Nawet pojedynczy węzeł może stanowić drzewo węzłów, w takim wypadku jest jego jedynym elementem. Każdy z poniższych rodzajów będzie przynależał do drzewa węzłów.
Drzewo węzłów z tym samym właścicielem
Drzewo węzłów z tym samym właścicielem # to drzewo z węzłami, których właścicielem jest ten sam obiekt typu Document, co w przypadku innego drzewa węzłów. Mogą to być drzewa węzłów poza drzewem dokumentu, poddrzewa węzłów z drzewa dokumentu lub aktywnego drzewa dokumentu.
Drzewo węzłów poza drzewem dokument
Drzewo węzłów poza drzewem dokument # to drzewo z węzłami, które nie należy bezpośrednio do drzewa dokumentu (obiektu typu Document). Mogą to być drzewa z węzłami utworzonymi przez nas samych za pomocą odpowiednich poleceń, np. Document.createElement(). Węzły mogą być przenoszone/kopiowane między dokumentami, mogą być też z nich usuwane, w takich przypadkach zawsze najpierw znajdują się poza drzewem dokumentu, do którego zostały dodane lub z którego zostały usunięte. Do tej grupy zalicza się także kolejne drzewa dokumentów utworzone przez nas samych lub wczytane za pomocą Ajaxa.
Drzewo dokumentu
Drzewo dokumentu # (inaczej zwane drzewem DOM), to drzewo z węzłami, które należą bezpośrednio do obiektu typu Document. Będą to aktywne drzewa dokumentów, drzewa dokumentów utworzone przez nas samych lub dokumenty załadowane i sparsowane przy użyciu Ajaxa. Między różnymi drzewami dokumentów można przenosić dowolne węzły, służą do tego celu metody Document.adoptNode() lub Document.importNode().
Aktywne drzewo dokumentu
Aktywne drzewo dokumentu #, to drzewo dokumentu, które umieszczone jest w bieżącym oknie lub ramkach.
Przeglądarka internetowa wczytując stronę spod wskazanego adresu URL tworzy jej obiektową reprezentację w pamięci operacyjnej maszyny. Strona ta będzie reprezentowana przez obiekt typu Document, który domyślnie występuje pod globalną właściwością document. W aktywnym dokumencie mogą znajdować się znaczniki, które pozwalają na jednoczesne wczytywanie kolejnych dokumentów, przykładem będzie ramka lokalna <iframe>. Z głównej strony WWW (obiekt document) możemy odwołać się do podrzędnego aktywnego dokumentu w ramce lokalnej, wystarczy wywołać następujące polecenie document.getElementById("ramka").contentDocument.
Oczywiście z poziomu skryptu można tworzyć kolejne dokumenty HTML czy XML, które na początku zawsze będą nieaktywnymi drzewami dokumentów i jednocześnie drzewami węzłów poza drzewem dokumentu. Każdy z tych nowych dokumentów może zostać umieszczony w zmiennej/właściwości o dowolnej nazwie.
Drzewo renderowania
Drzewo renderowania # jest drzewem istotnym z punktu widzenia CSS. Znajduje się w nim wszystko to, co zostanie wyświetlone z aktywnego drzewa dokumentu. Niektóre węzły mogą należeć do aktywnego drzewa dokumentu, ale nie będą wyświetlane, przykładowo komentarze lub znacznik <head> z całą swoją zawartością.
Zasadniczo podział na drzewo węzłów i aktywne drzewo dokumentu jest najistotniejszy z punktu widzenia programisty. Drzewo węzłów (w tym drzewo dokumentu), które ma być wyświetlone, musi zostać dołączone do odpowiedniej części aktywnego drzewa dokumentu, czyli takiej, która będzie miała pudełkowe odpowiedniki w drzewie CSS, np. do obiektu body. Ewentualnie fragmenty drzewa węzłów mogą być dodawane także do odpowiedniej części aktywnego drzewa dokumentu w obiektach reprezentujących zawartość ramek.
Można przyjąć, że każdy obiekt reprezentujący aktywny dokument ma tylko jedno drzewo renderowania. Nawet jeśli będzie on posiadał kolejne dokumenty w ramkach, tak naprawdę będziemy mieli do czynienia z pojedynczymi drzewami renderowania w każdym z nich.
Liczba drzew węzłów poza aktywnym drzewem dokumentu jest w zasadzie nieograniczona. Można tworzyć lub wczytywać dowolną ilość nowych dokumentów, pojedynczych węzłów, lub niewielkich drzew węzłów. Należy pamiętać, że każdy węzeł ma jakiegoś właściciela w postaci obiektu typu Document, nawet jeśli nie jest on aktualnie wyświetlany lub znajduje się poza drzewem dokumentu. W niektórych przypadkach węzły takie mogą być automatycznie usuwane w procesie oczyszczania pamięci.
Przykładowe polecenia CSS i DOM#
W poniższej tabeli zamieszczam kilka selektorów oraz metod i właściwości DOM przydatnych przy poruszaniu się po drzewie dokumentu. Punktem odniesienia będzie węzeł Dany element widoczny na pierwszej grafice w tym rozdziale.
| Węzeł (PL) | Węzeł (EN) | Selektor CSS | Metoda/Właściwość DOM |
|---|---|---|---|
| Korzeń | Root | :root, html | element.ownerDocument.documentElement |
| Rodzic | Parent | brak | element.parentNode |
| Przodek | Ancestor | brak | element.parentNode.parentNode |
| Poprzedni sąsiad | Previous sibling | brak | element.previousSibling |
| Następny sąsiad | Next sibling | element + sąsiad | element.nextSibling |
| Pierwsze dziecko | First child | element > dziecko:first-child | element.firstChild |
| Ostatnie dziecko | Last child | element > dziecko:last-child | element.lastChild |
| Wszystkie dzieci | Children | element > * | element.childNodes |
| Potomkowie | Descendants | element * | element.getElementsByTagName('*') |
Selektory CSS nie dają możliwości wybrania przodków, ani poprzedników, aby ułatwić przeglądarkom wyświetlanie progresywne (element występujący później w dokumencie nie powinien mieć wpływu na wcześniejsze) oraz uniemożliwić zrobienie kombinacji selektorów dających błędne koło. Nie wykluczone, że przyszłe specyfikacje CSS uzupełnią braki nowymi mechanizmami odpornymi na problematyczne zachowania.