Zdarzenia#
Wstęp#
Zdarzenia # (events) to najważniejszy mechanizm dynamicznych stron internetowych oraz każdej aplikacji JavaScript, ponieważ są motorem napędowym do ich działania i stanowią początkowy etap interakcji użytkownika z danym serwisem. Dlatego też tworzę osobny dział w całości poświęcony zdarzeniom, gdzie w razie potrzeby będę dopisywał istotne kwestie pochodzące z następujących ogólnych specyfikacji przeznaczonych dla zdarzeń:
- "DOM Living Standard" (skrót DOM4) #
- "DOM Level 3 Events" (skrót D3E) #
- "DOM Level 3 KeyboardEvent code Values" (skrót D3E-code) #
- "DOM Level 3 KeyboardEvent key Values" (skrót D3E-key) #
- "UI Events" (skrót UIE) #
Przy nawiązywaniu do konkretnej specyfikacji zastosowany zostanie jej skrót.
Raczej nie przetłumaczę w całości wszystkich specyfikacji, ale najistotniejsze sprawy przydatne w codziennym programowaniu powinny pojawić się w moim kursie. Nie należy zapominać także o wielu innych pomniejszych specyfikacjach towarzyszących ciągłemu rozwojowi HTML5, gdzie definiowanie kolejnych przydatnych zdarzeń dla danej funkcjonalności jest powszechne i wykorzystywane w późniejszej pracy każdego programisty.
Istota zdarzeń#
Zdarzenia są tak naprawdę obiektami, co nie powinno już nikogo dziwić w przypadku języka ECMAScript (gdzie większość danych stanowią obiekty). Ale są to obiekty specyficzne, mają ściśle scharakteryzowane cechy oraz mogą być wywoływane przez określone zachowania urządzeń zewnętrznych (jak np. kliknięcie, przesuwanie, dotyk) lub na skutek wykonania określonych czynności programistycznych (np. zakończenie wczytywania zasobu, zmiany w bazie danych, zmiany stanu właściwości). Czyli zdarzenia pozwalają zasygnalizować, że wystąpiły jakieś konkretne sytuacje podczas pracy z aplikacją.
Predefiniowanych zdarzeń zostało scharakteryzowanych bardzo wiele, praktycznie większość nowoczesnych rozszerzeń HTML5 ma w swoich definicjach jakieś dedykowane zdarzenie ułatwiające późniejszą pracę z owym mechanizmem. Większość zdarzeń należy do zaufanych zdarzeń, aczkolwiek w niektórych przypadkach istnieje możliwość tworzenia analogicznych niezaufanych zdarzeń (tzw. zdarzeń syntetycznych).
Same obiekty zdarzeń nie byłyby niczym szczególnym, gdyby nie ich propagacja definiowana w przepływie zdarzeń z jednoczesną możliwością chwytania. Całość jest na tyle uniwersalna, że powinna zaspokoić potrzeby większości projektów internetowych. Dzięki możliwości chwytaniu zdarzeń możemy dynamicznie reagować na działania użytkowników, przez co tworzenie wygodnych i funkcjonalnych aplikacji nie nastręcza wielu trudności.
Wszystkie praktyczne aspekty związane ze zdarzeniami pojawią się w kolejnych częściach kursu. Nim to nastąpi umieszczę troszkę teoretycznej wiedzy, która będzie pomocna w lepszym zrozumieniu zagadnienia.
Nieblokujące operacje wejścia-wyjścia i wywołania zwrotne#
W tradycyjnych językach programowania (bez obsługi zdarzeń) operacje wejścia-wyjścia blokują wątek programu i czekają na rezultat operacji, zanim zezwolą na dalsze wykonywanie kodu. Przeanalizujmy następujący przykład utworzony w języku PHP:
function getFromDatabase(){
$db = getDatabase();
$query = "SELECT name FROM countries";
$result = $db->getAll($query);
return result;
}Wiersz &db->getAll(&query); wymaga uzyskania przez bazę danych dostępu do dysku. A zatem w porównaniu z resztą funkcji wykonanie tej części kodu zajmie czas większy o rzędy wielkości. Gdy program czeka na wykonanie przez serwer, instrukcja zapytania jest zablokowana. W efekcie program nie przeprowadza żadnej innej operacji. W językach służących do tworzenia kodu po stronie serwera, takim jak PHP, który umożliwia jednoczesne wykonywanie wielu wątków lub procesów, zwykle nie stanowi to problemu.
Jednakże w środowisku JavaScript występuje tylko jeden główny wątek wykonawczy. A zatem, jeśli funkcja zablokowałaby ten wątek, to nic innego nie mogłoby zostać wykonane, co wiąże się także z blokadą interfejsu użytkownika. Oznacza to, że w przypadku interpreterów języka JavaScript należało znaleźć inny sposób obsługi operacji wejścia-wyjścia (z uwzględnieniem wszystkich operacji sieciowych). Tym rozwiązaniem są właśnie zdarzenia oraz mechanizmy ich obsługi, które są zazwyczaj operacjami asynchronicznymi. Czyli operacje te są konfigurowane w jednym miejscu i później wykonywane po wystąpieniu określonego zewnętrznego zdarzenia.
Idealnym przykładem tego zachowania będzie utworzenie i wysłanie zapytania Ajax do serwera. W takim wypadku interpreter JS aktywuje żądanie, a następnie zajmuje się innymi operacjami. Interpreter oferuje funkcję zwrotną wywoływaną po zakończeniu przetwarzania wywołania serwera. Jest ona wywoływana z danymi zwracanymi przez serwer po ich przygotowaniu. W ramach analogii można rozważyć dwie metody kupowania produktu w sklepie spożywczym. W niektórych sklepach produkty znajdują się za ladą, dlatego konieczne jest poproszenie sprzedawcy o dany artykuł i poczekanie na otrzymanie go. Przypomina to zaprezentowany wcześniej kod PHP. W innych sklepach można złożyć zamówienie i otrzymać numer. Później można kupić inne produkty i odebrać zamówiony artykuł. Ta sytuacja przypomina działanie wywołania zwrotnego.
Z kilkoma wyjątkami, które prawdopodobnie nie wystąpią, operacje wejścia-wyjścia języka JavaScript nie powodują zablokowania głównego wątku wykonawczego. Trzy najważniejsze odstępstwa od tej reguły to następujące metody okien: alert(), confirm() i prompt(). Te trzy metody blokują cały kod JS na stronie od chwili ich wywołania do momentu, gdy użytkownik zamknie okno dialogowe. Ponadto obiekt XMLHttpRequest może wygenerować żądanie Ajax dla serwera w trybie synchronicznym. Choć jest to bezpieczne w przypadku wątków roboczych # (Web Workers), to uruchamianie tego trybu w głównym wątku może spowodować zablokowanie interfejsu użytkownika przeglądarki. Z tego powodu należy tego unikać.
Kolejka zdarzeń i pętla zdarzeń#
Gdy użytkownik pracuje z dowolną aplikacją, to system operacyjny otrzymuje sygnały wejściowe z różnych urządzeń podłączonych do komputera, takich jak klawiatura lub mysz. System rozdziela te sygnały na aplikacje, do których powinny one trafić, pakietuje je jako pojedyncze zdarzenia i umieszcza w kolejce, zwanej kolejką zdarzeń.
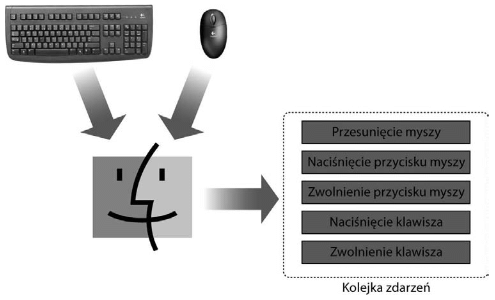
Rysunek. Kierowanie przez system operacyjny wszystkich sygnałów wejściowych użytkownika do kolejki zdarzeń
W systemach z rodziny Windows aplikacje są pisane zgodnie z paradygmatem zdarzeń pochodzących od urządzeń. Wszystkie wiadomości są umieszczane w systemowej kolejce zdarzeń. Programy użytkowe przeglądają okresowo tę kolejkę za pomocą pętli, która przez deweloperów potocznie nazywana jest pompą wiadomości (message pump). Pompa filtruje i wybiera określone wiadomości i wykonuje na nich jakieś akcje. Przykładowo, wiadomości systemowe zwracają specjalne kody jak WM_CLOSE w odpowiedzi na zamknięcie okna; WM_SIZE dla zmiany rozmiaru okna, WM_MOUSEMOVE dla przesunięcia myszki, czy WM_KEYDOWN i WM_KEYUP dla wciśnięcia przycisku klawiatury.

Rysunek. Przetwarzanie systemowej kolejki zdarzeń przez przeglądarki internetowe
Ważne jest, aby zrozumieć ten model, gdyż większość przeglądarek jest pisana pod różne platformy i działa w oparciu o różne systemy operacyjne. Przeglądarki wprowadzają abstrakcję dla przetwarzania zdarzeń z każdego systemu operacyjnego do swojego własnego modelu. Asynchroniczne zdarzenia specyficzne dla platformy (myszki, klawiatury, timery) przepływają najpierw przez system operacyjny, i następnie są filtrowane przez przeglądarkę. Przeglądarka musi podjąć pewne decyzje, w jaki sposób chce zoptymalizować doświadczenia dla użytkownika. W idealnym przypadku większość wiadomości Windows jest obsługiwana w zwykłym znaczeniu, ale są też wiadomości obsługiwane w sposób unikatowy.
Dla przykładu, jeśli używamy przeglądarki i przesuniemy myszkę nad oknem przeglądarki, to systemowe zdarzenia myszy są umieszczane w systemowej kolejce zdarzeń. Przeglądarka filtruje takie zdarzenia przy użyciu pompy wiadomości. Ta chwyta jedno z nich, którym jest najbardziej zainteresowane, a następnie umieszcza je w swojej wewnętrznej kolejce. Wybrane zdarzenia są ściśle zbliżone do JavaScriptowych zdarzeń myszki, jak np. mousemove, mousedown lub mouseup (i pozostałych definiowanych przez różne standardy).
Następnie rzeglądarka, podobnie jak każda inna aplikacja GUI, przetwarza poszczególne zdarzenia umieszczone w swojej wewnętrznej kolejce i na ich podstawie wykonuje na ogół jedną z dwóch rzeczy:
- Sama obsługuje dane zdarzenie (np. przez wyświetlenie menu, przeglądanie WWW, wyświetlenie okna preferencji itp.).
- Wykonuje umieszczony na stronie kod JavaScript, który przypisany został do danego zdarzenia (np. kod JavaScript umieszczony w uchwycie atrybutowym
onclick).
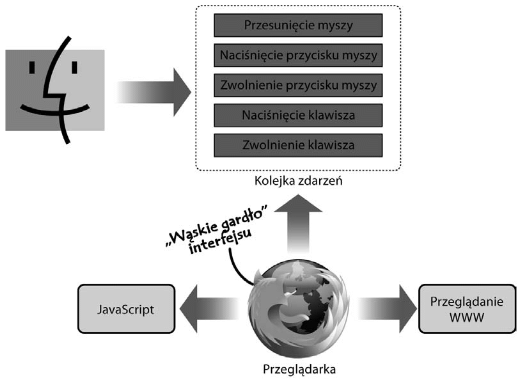
Rysunek. Przetwarzanie przez przeglądarkę zdarzeń z kolejki zdarzeń i wykonywanie kodu użytkownika
Jak wspomniałem nieco wcześniej, przeglądarka jest w zasadzie jednowątkowa, dlatego proces obsługi zdarzeń wykonywany jest przez główny wątek wykonawczy. Przeglądarka używa głównego wątku, aby pobrać zdarzenie z kolejki, i albo robi coś sama, albo wykonuje kod JavaScript wstawiany przez użytkownika. Wskutek tego przeglądarka może wykonać tylko jedno z tych zadań naraz, a każde z nich może zapobiec wystąpieniu innego zdarzenia.
Kiedy przeglądarka nie robi niczego sensownego, tzn. znajduje się w stanie bezczynności, to tak naprawdę przechodzi do obsługi pętli zdarzeń. Jeśli jakieś nowe zdarzenia zostaną dodane do kolejki zdarzeń, a przeglądarka będzie w stanie bezczynności, to z poziomu pętli zdarzeń zacznie ona uruchamiać kod obsługi pierwszego zdarzenia pobierając go z kolejki zdarzeń. Wątek główny oraz wątki robocze utrzymują własną niezależną pętlę zdarzeń i kolejkę zdarzeń, dlatego w przypadku "cięższych" obliczeń wątki robocze mogą być niezwykle pomocne do ogólnej poprawy wydajności aplikacji.
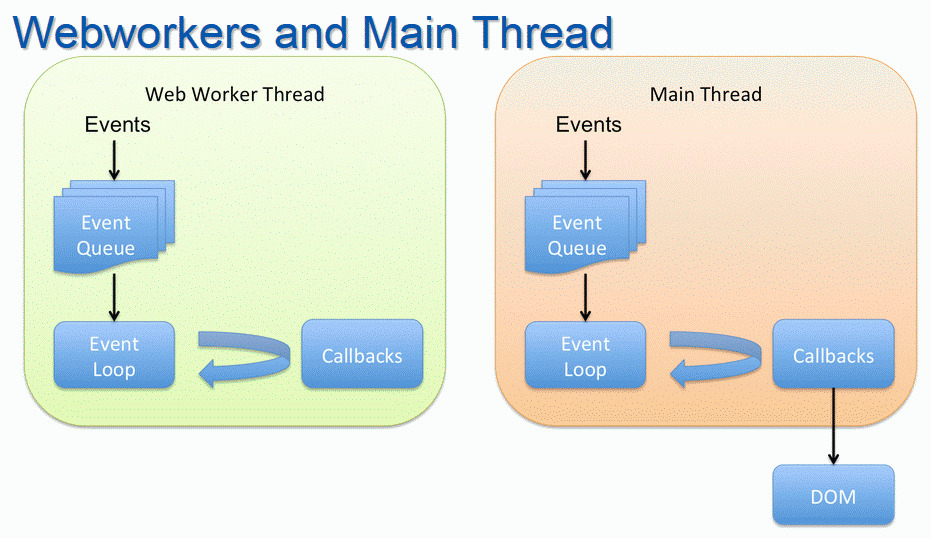
Rysunek. Kolejka zdarzeń i pętla zdarzeń dla wątku roboczego i wątku głównego
Każda chwila spędzona przez przeglądarkę na wykonywaniu kodu JS w głównym wątku to okres, w ciągu którego nie może ona odpowiadać na inne zdarzenia użytkownika. Dlatego też niezwykle istotne jest, aby kod JS umieszczony na stronie był wykonywany jak najszybciej. W przeciwnym razie strona WWW i sama przeglądarka mogą reagować z opóźnieniem lub całkowicie zaprzestać działania.
Na szczęście większość rzeczy, które muszą zostać wykonane przez kod JavaScript, to szybkie operacje. Zwykle mają one na celu przetworzenie określonych danych i przekazanie ich do modelu DOM lub utworzenie żądania Ajax. A zatem model oparty na kolejce zdarzeń i pętli zdarzeń sprawdza się naprawdę dobrze. W przypadku rzeczy, których obliczenie zajęłoby więcej niż ułamek sekundy, zastosowanie kilku zabiegów może wyeliminować wąskie gardła, mające wpływ na komfort obsługi użytkownika. Umiejętne tworzenie nieblokującego kodu JS jest tematem, który powinien znaleźć się w każdym solidnym kursie o JavaScripcie.
Trzeba jednak zaznaczyć, że cały ten wykład o działaniu przeglądarek oraz systemów operacyjnych pod względem obsługi sygnałów wejściowych i zdarzeń jest tylko uogólnieniem obejmującym szeroki zakres przypadków, które w szczegółach mogą się różnić.
Możliwy obszar występowania#
Trzy najważniejsze interfejsy zdarzeń definiowane w DOM4, czyli Event, CustomEvent i EventTarget, mają w swoich definicjach Web IDL identyczny atrybut rozszerzający typu [Exposed]:
[Exposed=Window,Worker]
Oznacza to, że wspomniane interfejsy (i w konsekwencji obiekty zdarzeń je implementujące) mogą występować zarówno w wątku głównym jak i wątkach roboczych przeglądarki internetowej.
Na chwilę obecną jedynie przeglądarka Firefox eksponuje wymienione interfejsy w wątkach roboczych (chociaż dalej pomija CustomEvent).
Kompatybilność#
Zdarzenia i sposoby ich obsługi są tym obszarem, które wprowadzały największe rozbieżności w przypadku przeglądarek internetowych. Początkowo przeglądarki IE i Netscape implementowały (z powodu braku ustalonych standardów) odmienne rozwiązania, np. dla sposobu propagacji, przerywania propagacji, przerywania domyślnego zachowania, dołączania i odłączania obserwatorów zdarzeń, we właściwościach udostępnianych przez zdarzenie itd. Tych różnic było naprawdę sporo i dla początkujących programistów stanowiły nie lada wyzwanie. Między innymi dlatego powstało tak wiele bibliotek poświęconych modelowi DOM, których podstawowym zadaniem, oprócz wprowadzania wielu usprawnień w postaci nowych poleceń, było również zapewnienie kompatybilności kodu między różnymi programami (głównie dla zdarzeń).
Dopiero opracowanie standardu "DOM Level 2 Events Specification" z 2000 roku miało uporządkować cały ten bałagan z przeszłości. Nowoczesne przeglądarki (takie jak Firefox, Opera, Safari czy późniejsze Chrome) bardzo szybko dostosowały się do nowych wymagań W3C. Niestety, w Internet Explorerze odmienna implementacja mechanizmów obsługi zdarzeń utrzymywał się aż do opublikowania przeglądarki IE9.
Na dzień dzisiejszy (tj. 31.07.2013) zapowiadana jest już 11 wersja przeglądarki Microsoftu, która udostępniona zostanie także pod systemem Windows 7. Nie przepadam za niestandardowymi rozwiązaniami, dlatego w moich kursach bardzo mało miejsca poświęcam na opisy prywatnych poleceń poszczególnych przeglądarek. Nie inaczej będzie w przypadku zdarzeń, w zasadzie to nie zaprezentuję żadnego przykładu obsługującego archaiczne przeglądarki. Mamy wiele nowoczesnych i fajnych przeglądarek, dlatego też każdy powinien wybrać coś aktualnego dla siebie. Agresywne utrzymywanie kompatybilności stron i aplikacji ze "starociami" powoduje zastój w całej branży, blokuje szybszy dostęp do wygodnych rozwiązań, a także doprowadza do bardzo powolnego wymierania reliktów przeszłości (przypadek IE6), dlatego ja do tego ręki przykładał nie będą i innych też zachęcam do takiej postawy.
Ze względu na kompletność kursu wymieniam jedynie najważniejsze różnice występujące w starszych wersjach Internet Explorera, z którymi musieliśmy się męczyć ładny kawałek czasu:
- W IE nie ma metody
addEventListener(), chociaż od wersji 5 istnieje odpowiadająca jej metodaattachEvent()z obsługą bąbelkowania, która pobiera tylko dwa argumenty (zdarzenie i funkcję zwrotną). We wcześniejszych wersjach dostępne są jedynie uchwyty przez właściwość lub atrybut. - W celu usunięcia uchwytu zdarzenia należy wywołać metodę
detachEvent(). - Metodom
attachEvent()idetachEvent()należy przekazać nazwę zdarzenia poprzedzoną prefiksemon-, np.onclick. - W czasie wywołania funkcji zwrotnej nie zostaje jej przekazany obiekt zdarzenia. Niezależnie od sposobu przypisania obserwatora, w IE można pobrać zdarzenie z obiektu globalnego za pomocą polecenia
window.event. - W IE obiekt zdarzenia nie posiada właściwości
targetz informacją o elemencie, do którego obiekt zdarzenia zmierza. Zamiast tego posiada analogiczną właściwośćsrcElement. - Przechwytywanie zdarzeń jest możliwe tylko dla niektórych typów zdarzeń (np. zdarzeń myszki), ale robimy to za pomocą dedykowanych metod
setCapture()ireleaseCapture(). - Nie istnieje metoda
stopPropagation(). Odpowiadające jej zachowanie można wymusić, ustawiając właściwośćcancelBubblena boolowską wartośćtrue. - Zamiast wywołania metody
preventDefault()należy ustawić właściwośćreturnValuena boolowską wartośćfalse.