Typ MIME#
Wstęp#
MIME (Multipurpose Internet Mail Extensions - Uniwersalne Internetowe Rozszerzenia Poczty) jest standardem opisu różnego rodzaju informacji. Początkowo był sposobem na wysyłanie e-mailem danych innych, niż czysty tekst (czyli binarnych) - pliki dołączane były w postaci załączników. Z czasem rozwinął się on jednak na tyle, że aktualnie jest niekwestionowanym standardem do określania rodzaju wszystkich plików umieszczonych w Internecie.
Typy MIME są istotne w protokołach komunikacyjnych, w szczególności HTTP. Protokół HTTP wymaga, by dane były transmitowane w kontekście podobnym do wiadomości e-mail, chociaż dane te same w sobie nie stanowią wiadomości e-mail. Przed każdym plikiem czy dokumentem przesyłanym przez sieć WWW, dołączane są specjalne dane w nagłówku HTTP, w którym znajduje się m.in. typ MIME. To właśnie dzięki niemu, przeglądarka użytkownika potrafi rozpoznać każdy zasób i podjąć względem niego określone czynności. Przykładowo, pliki (X)HTML powinny zostać odpowiednio przetworzone i wyświetlone, pliki graficzne mogą być wyświetlone natychmiastowo.
Dlaczego akurat MIME?#
Podstawową zaletą MIME jest to, że jest to standard. Niemal wszystkie narzędzia pracujące w Internecie potrafią ten standard obsłużyć. Jest to bardzo ważne w strukturze tak rozległej i zróżnicowanej jak Internet, w której pracują krańcowo różne typy komputerów.
Dzięki MIME list zawierający zdjęcie i nagrany głos nadawcy może zostać wysłany z komputera typu Macintosh, a następnie odebrany na komputerze Amiga, przy czym zarówno nadawca listu jak i odbiorca w ogóle nie zauważą faktu, że np. dane zawierające obrazek zostaną po drodze zamienione na ciąg literek wyglądających np. tak:
M YP.?4)W0DI38Y0+E:JKK)50K:J2 *R$E*P0E'R5?!0^4CBH#+:PJU##Q*XP MOST"2A7+SS,1EM-Q#]05GE$SKVD O J[5K!*8^*_R1"J4IIES>@/.VWRG=+A M:>"I[+JK3_KCK/RYV#'J@C4G]B@0G#1%5A9OUPY2D!AH2I*%#: YT/'^28'&
...a do tego jeszcze plik zawierający dźwięk został zmieniony w "międzyczasie" z formatu stosowanego na jednym komputerze na format stosowany na drugim.
Budowa typu MIME#
MIME składa się z wielu nagłówków (np. MIME-Version, Content-ID, Content-Type, Content-Disposition, Content-Transfer-Encoding) i innych, które są istotne w przypadku pisania e-mail (np. From:..., Subject:..., Date:...). Przy tworzeniu stron szczególnie istotny jest typ MIME (Content-Type) dlatego też, tylko jemu poświęcę nieco uwagi.
Typ MIME jest dwuczęściowym identyfikatorem formatu plików w Internecie (mogą pojawić się również opcjonalne parametry). Każdy rodzaj danych (dokumenty xHTML, arkusze stylów, obrazy, pliki audio, wideo i inne) posiada swój własny typ MIME. Przykładowy zapis dla czystego tekstu:
Content-Type: text/plain
Powyższy zapis określa zawartość pliku, oraz - co bardzo ważne - zestaw znaków stosowanych w tym pliku (jeżeli jest to plik tekstowy). Pierwsza wartość (u nas "text") definiuje typ, czyli np. tekst, grafikę, dźwięk. Drugie słowo (u nas "plain") podaje konkretny format (np. "plain" - zwykły tekst, "html" - dokument HTML, "jpg" - obrazek w formacie JPEG, itp...).
RFC 2045 i RFC 2046 definiują 5 podstawowych i 2 dodatkowe (złożone) typy mediów:
text- dane tekstoweimage- obrazyaudio- dane audiovideo- dane wideoapplication- inne rodzaje danychmultipart- dane zawierające wiele niezależnych typów danychmessage- część innej wiadomości (załącznik maila) albo pofragmentowana wiadomość (dzielone maile)
Dla niektórych typów możliwe jest podanie opcjonalnych parametrów. Na przykład dla podtypów typu "text" można określić dodatkowo parametr "charset" używany do wskazania kodowania znaków, a podtypy typu "multipart" często definiują parametr "boundary" jako separator poszczególnych części. Prosty przykład:
Content-Type: text/plain; charset=utf-8
Typy lub podtypy rozpoczynające się od "x-" określane są jako niestandardowe - nie mogą być zarejestrowane w IANA. Podtypy zaczynające się od "vnd." należą do rozszerzeń poszczególnych dostawców.
Organizacja W3C termin "typ MIME" zastąpiła nowszym określeniem Internetowy Typ Mediów (Internet Media Type). Udostępniono specjalny dokument, w którym określono najważniejsze aspekty dla Internetowego Typu Mediów (rejestrację, spójność oraz kodowanie).
Osoby uważnie czytające kurs pewnie skojarzą domyślny typ kodowania danych wysyłanych przez formularz (application/x-www-form-urlencoded), który jest niestandardowym formatem.
Jak sprawdzić typ MIME#
Jeśli chodzi o pliki (X)HTML najłatwiej skorzystać z przeglądarki Firefox. Wystarczy na dowolnej stronie kliknąć prawym przyciskiem myszki, a następnie wybrać z menu podręcznego opcję "Pokaż informacje o stronie". W zakładce "Ogólne" pojawi się sporo informacji dla danej witryny. Zasadniczo typ pliku odczytujemy w górnej części (zaraz za adresem URL). W źródle strony można określić typ za pomocą znaczników <meta>. Przykładowo dla mojej strony będzie to deklaracja:
<meta http-equiv="content-type" content="application/xhtml+xml; charset=utf-8" />Wszystkie definicje metadanych zostaną wyszczególnione w oknie Firefoksa.
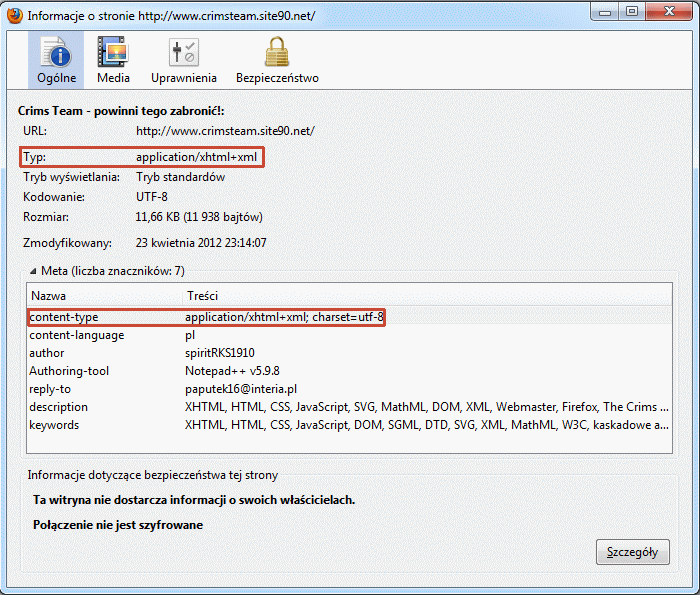
Rysunek. Firefox - informacje o stronie (w tym także typ MIME)
W analogiczny sposób można odczytać typ dla dowolnej grafiki umieszczonej na stronie.
Zdecydowanie lepsze możliwości analizy nagłówków wysyłanych i odbieranych danych posiadają dedykowane narzędzia. Jednym z najpopularniejszych będzie Firebug, posiadający największe możliwości pod przeglądarką Firefox. Jeśli ktoś nie znał, lub słyszał ale nie stosował owego narzędzia, powinien jak najszybciej poznać jego podstawy. W zakładce "Sieć" można przeanalizować każde żądanie oraz odpowiedź dla danej strony (i wszystkich jej zasobów).

Rysunek. Firebug - analiza nagłówków odpowiedzi (w tym także typ MIME)
Każda nowoczesna przeglądarka ma narzędzie pokroju Firebuga. Istnieją także zewnętrzne programy, które pozwalają analizować przepływ danych w różnych przeglądarkach (np. HttpWath, IBM Page Detailer, Fiddler). Są to narzędzia nasłuchujące pakiety (packet sniffers) na wysokim poziomie (analiza plików jako całości). Jeśli interesowałby nas podgląd przepływu danych w danym pakiecie można skorzystać z niskopoziomowych analizatorów, np. Wireshark. Nie operuje on pojęciem strony WWW, więc użytkownik musi samodzielnie rozpoznać, gdzie zaczyna się i kończy pakiet strony WWW.
Typ MIME dla plików (X)HTML#
Kurs dotyczy HTML-a (zahacza także o XHTML-a), dlatego zamieszczam spis typów MIME, z którymi mogą być przesyłane owe dokumenty:
| Typ MIME | HTML 4.01 | XHTML 1.0 (kompatybilność wstecz) | XHTML 1.0 | XHTML 1.1 |
|---|---|---|---|---|
text/html | powinien | może | nie powinien | nie powinien |
application/xhtml+xml | nie może | powinien | powinien | powinien |
application/xml | nie może | może | może | może |
text/xml | nie może | może | może | może |
Dane pochodzą z pierwszej wersji specyfikacji dla typów MIME w przypadku dokumentów (X)HTML. Jak widać, przewidziano w niej cztery różne typy mediów. W drugiej wersji wprowadzono trochę korekt, pozostawiając jako poprawne tylko "text/html" (dla HTML-a) lub application/xhtml+xml (dla XHTML-a).
HTML#
W praktyce najłatwiejsza sytuacja była i jest w przypadku plików HTML. Do ich wyświetlania służy typ MIME text/html. Ten typ mówi przeglądarce, że ma do czynienia nie ze zwykłym tekstem, ale ze sformatowanym dokumentem, który trzeba odpowiednio zinterpretować. Rodzaj interpretacji powinien zależeć od definicji typu dokumentu, ale przeglądarki stosują w tym celu własne (wbudowane) definicje - DTD tak naprawdę wykorzystywany jest do innych celów.
Jeśli serwer będzie niepoprawnie skonfigurowany i będzie wysyłał dokument HTML jako text/plain, a nie jako text/html, to nowoczesne przeglądarki zachowają się poprawnie i wyświetlą źródło strony (czyli czysty tekst), a nie wynik w postaci sformatowanego dokumentu. Jedynie IE zdoła wyświetlić taką stronę internetową. Czyni to dlatego, że błędnie rozpoznaje rodzaj dokumentu nie przez typ MIME, a przez rozszerzenie pliku.
XHTML#
W przypadku XHTML-a sytuacja była zawsze skomplikowana, co w ostateczności doprowadziło do "upadku" tego standardu na rynku masowym. Postanowiono dalej rozwijać HTML-a, nazywając go po prostu HTML5.
Standardy (zbiór teoretyczny) żyły własnym życiem, a faktyczne implementacje w przeglądarce odbiegały od idealistycznych wizji. Wymuszenie na przeglądarce serializacji plików za pomocą parsera XML (XHTML) wymagało przesłania tych plików z właściwym dla nich typem (żadna deklaracja DTD tego nie zapewniała). Dokumenty XHTML mogą być serwowane jako application/xml albo text/xml, ale należy zauważyć, że w różnych programach przetwarzających XML (m.in. przeglądarkach) dokument może być nieprawidłowo przetworzony (np. odnośniki mogą zostać nierozpoznane). Dlatego dokumenty powinny być serwowane jako application/xhtml+xml. Ten typ mediów jest przejściowym typem MIME między dokumentami HTML a XML, przeznaczonym specjalnie dla dokumentów XHTML.
Samo wymuszenie typu application/xhtml+xml można przeprowadzić na wiele sposobów. Jest to ciekawy temat, który znajdzie swoje miejsce w osobnym kursie poświęconym językowi XHTML. Serwowanie dokumentów XHTML jako application/xhtml+xml wymaga pisania poprawnego kodu. W przypadku popełnienia jakiegokolwiek błędu (np. złe osadzenie znacznika, niedomknięty znacznik), przeglądarka nie przetworzy strony i nie wyświetli jej prawidłowo. XHTML podany jako text/html nie będzie przetworzony jak XML i błędy w dokumencie mogą nie zostać wykryte.
Dlaczego XHTML się nie przyjął? Bo większość, jak nie wszyscy, i tak wysyłali pliki z typem text/html. W źródle stosowali składnię XHTML-a, ale prawdę mówiąc przeglądarki serializowały taki dokument za pomocą parsera HTML. Wszystkie cechy ze składni XHTML były wewnętrznie uznawane za błędy i poprawiane. Na domiar złego, nie wszystkie przeglądarki potrafiły poradzić sobie z dokumentem XHTML serwowanym jako application/xhtml+xml. Wśród nich znajdowała się ta najpopularniejsza - Microsoft Internet Explorer. Żadna z wersji IE nie potrafi prawidłowo poradzić sobie z poprawnie podanym dokumentem XHTML.
Dopiero w IE9 pliki z typem application/xhtml+xml są rozpoznawane, ale przeglądarka przetwarza je w ten sam sposób co pliki text/html. Prawidłowa obsługa powinna pojawić się w 10 wersji przeglądarki.
Problem z IE można było rozwiązać podając przeglądarkom taki typ MIME, z jakim potrafiły sobie one poradzić. Wystarczyło przeprowadzić negocjację zawartości (content negotiation) po stronie serwera. Niestety, wszystkie rozwiązania wymagały albo dostępu do konfiguracji serwera, albo obsługi jakiegoś języka serwerowego (np. PHP). Wszystko to było ponad możliwości przeciętnego programisty, czyli dotyczyło lwiej części segmentu WWW, dlatego XHTML upadł. Nie było sensu drążyć i rozwijać standardu, który miałby mieć takie problemy z poprawnym wykorzystaniem w przyszłości.
Podsumowanie#
Na dzień dzisiejszy nie ma potrzeby używania XHTML-a. Nowy HTML5 oferuje wszystko to, czego potrzebuje większość twórców WWW. Zaczynając przygodę z językami znacznikowymi (2007 rok), sam byłem w rozterce - toczyły się przepychanki odnośnie dalszego rozwoju języka (XHTML2 vs HTML5). Termin XHTML był wówczas bardzo modny, jako "szczypior" od razu rzuciłem się na XHTML 1.1, jednocześnie postanowiłem wysyłać pliki z odpowiednim MIME dla tych przeglądarek, które sobie z nim poradzą. Nie było to trudne, prawdę mówiąc nawet mi odpowiadało, każdy błąd miałem wyłuszczony w oknie przeglądarki - a błędów przy pisaniu plików xHTML popełnia się wiele. Jest to szczególnie wygodne w przypadku pisania skryptów - można analizować błędnie działając kod JavaScript wiele godzin, a źródłem problemów może być po prostu błędnie napisany dokument xHTML.
Minęło trochę czasu, w chwili kiedy to piszę mamy 2012 rok, tym razem na topie jest termin HTML5, który może być serializowany w postaci HTML lub XML (określa się go mianem XHTML5). Mimo upływu lat nie planuję przepisania strony, może w przyszłości przerobię nagłówki tak, żeby całość była interpretowana jako XHTML5.