Szkielet dokumentu#
Indeksowanie strony#
Tekst w przeważającej części pochodzi z kursu Sławomira Kokłowskiego, minimalnie go odchudziłem.
<head> <meta name="robots" content="dyrektywy"> </head>
Polecenie jest wskazówką dla robotów-indekserów, czy strona i jej pochodne mają być indeksowane. Domyślnie stosowane jest indeksowanie, ale możemy podać dyrektywy, wybierając odpowiednią kombinację aby to zmienić. Oto dostępne dyrektywy:
- index - ustawienie domyślne, strona, na której wstawiono polecenie będzie indeksowana przez roboty sieciowe (indeksery)
- noindex - strona, na której wstawiono polecenie nie będzie indeksowana
- follow - ustawienie domyślne, przechodzenie do stron, do których odnoszą się odsyłacze, znajdujące się w dokumencie
- nofollow - robot nie przechodzi do stron wskazywanych przez odsyłacze wstawione na stronie, ale może je zaindeksować, jeżeli istnieją inne linki umieszczone na stronach bez tego zakazu
- index, nofollow - indeksuje stronę, nie przechodzi do stron wskazywanych przez odsyłacze
- noindex, follow - nie indeksuje strony, na której wstawiono polecenie, przechodzi do stron wskazywanych przez odsyłacze.
- all = "index, follow" - ustawienie domyślne, indeksuje wszystko
- none = "noindex, nofollow" - nie indeksuje nic
Jak widać znacznie szybciej będzie, jeśli zamiast pisać "index, follow" podamy all. Podobnie w przypadku "noindex, nofollow" możemy użyć none.
Specyfikacja HTML 4.01 wskazuje tylko następujące wartości tego elementu: all, index, nofollow, noindex. Choć inne specyfikacje jasno wskazują na dodatkowe wartości, to jeśli chcesz mieć największą pewność, że dyrektywy zostaną uwzględnione, zamiast "none" możesz użyć "noindex, nofollow".
Przykładowa deklaracja zakazująca robotom jakiegokolwiek indeksowania:
<meta name="robots" content="noindex, nofollow">Niestandardowe dyrektywy robotów#
Roboty mogą interpretować dodatkowe, niestandardowe dyrektywy (wszystkie poniższe są rozpoznawane przez robota wyszukiwarki Google):
- noarchive - blokada archiwizowania kopii strony w pamięci podręcznej wyszukiwarki
- nosnippet - blokada wyświetlania opisu strony w wynikach wyszukiwania
- noodp - opis strony nie zostanie pobrany z katalogu Open Directory Project
Dyrektywa "noarchive" blokuje archiwizowanie dokumentu. Wyszukiwarki sieciowe często zapisują kopię indeksowanych stron w swojej pamięci podręcznej. Użytkownicy korzystający z wyszukiwarki mogą otworzyć taką kopię strony np. kiedy oryginalna witryna jest chwilowo niedostępna. Aby otworzyć stronę z pamięci podręcznej wyszukiwarki Google, należy na liście wyników wyszukiwania kliknąć link "Kopia":
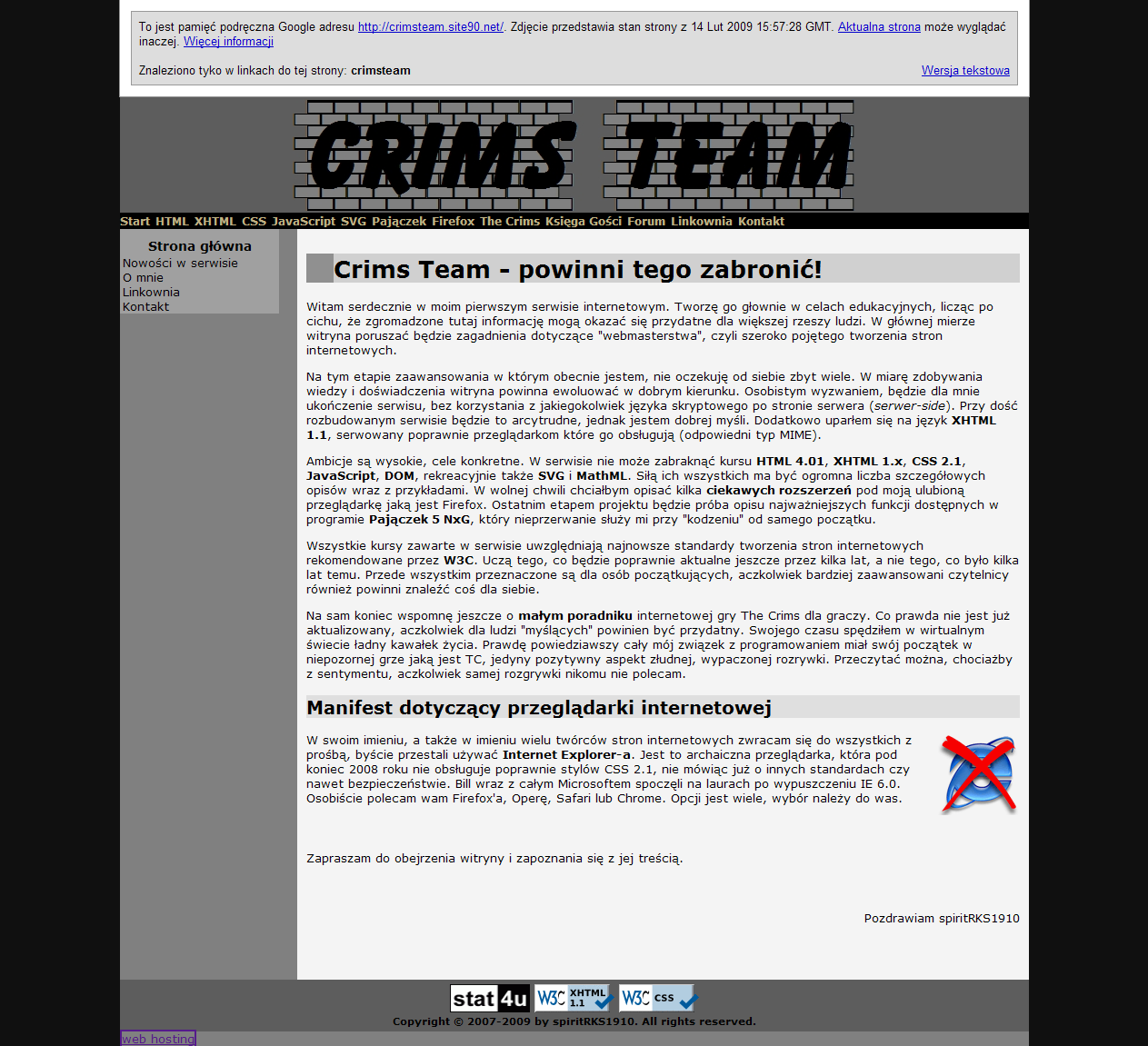
Rysunek. Kopia strony przechowywana na serwerach Google
Aby połączyć dyrektywy standardowe z niestandardowymi, nie należy wpisywać kilku osobnych znaczników <meta>, ale podać pełną listę po przecinku, np.:
<meta name="robots" content="nofollow, noarchive">Googlebot#
Wyszukiwarka Google wprowadziła specjalny znacznik, który pozwala wydać dyrektywy tylko dla robota Googlebot. Na przykład aby zablokować robotowi Google dostęp do strony, ale jednocześnie pozwolić na to robotom innych wyszukiwarek, można wpisać:
<meta name="googlebot" content="noindex, nofollow">Blokada indeksowania wybranych odsyłaczy#
Element <meta name="robots" content="nofollow"> powoduje, że roboty sieciowe nie będą podążać za żadnymi linkami umieszczonymi w dokumencie.
Czasami jednak chcielibyśmy zablokować uwzględnianie tylko wybranych odsyłaczy. Taka sytuacja najczęściej ma miejsce, kiedy wstawiamy na swojej stronie system komentarzy. Spammerzy lub spamboty (automaty spamujące) często wpisują komentarze bez żadnej konkretnej treści, ale za to przeładowane linkami do stron, które chcą zareklamować. Aby uczynić takie linki nieistotnymi dla robota wyszukiwarki Google, należy dopisać do wszystkich odsyłaczy np. z komentarzy dodatkowy atrybut:
<a href="http://<var>adres strony</var>" rel="nofollow">...</a>Plik robots.txt#
Znacznik <meta name="robots"> jest przydatny w celu określania dostępu przez roboty do pojedynczych dokumentów HTML. Okazuje się jednak mało praktyczny, jeśli chcielibyśmy zablokować dostęp np. do wszystkich dokumentów z określonego katalogu serwisu albo wręcz hurtowo do wszystkich plików witryny. Znacznik ten okazuje się wręcz zupełnie nieprzydatny, jeśli zależy nam na zablokowaniu indeksowania np. zdjęć z naszego serwisu (większość wyszukiwarek posiada osobne formularze do wyszukiwania plików graficznych).
Istnieje jednak możliwość określenia globalnego dostępu do wszystkich plików serwisu - nosi on nazwę: Standard Wykluczania Robotów (A Standard for Robot Exclusion - Robots Exclusion Protocol). W głównym katalogu konta WWW - czyli tam, gdzie znajduje się dokument strony głównej serwisu (index.html) - należy umieścić specjalny plik pod nazwą robots.txt. W pliku tym umieszcza się tzw. rekordy - każdy zawiera grupę linijek w postaci:
Pole: wartość
Wielkość liter w nazwach pól nie ma znaczenia, natomiast zwykle ma znaczenie w wartościach pola. Oprócz typowych linijek możliwe jest również umieszczanie komentarzy, czyli tekstu, który nie zostanie wzięty pod uwagę przez roboty. Komentarz rozpoczyna się znakiem "#", a kończy na końcu linijki.
User-Agent#
W jednym pliku robots.txt może się znajdować dowolna liczba rekordów rozdzielonych pustymi linijkami - każdy musi się rozpoczynać linią User-Agent, wskazującą do których robotów odnoszą się dalsze linijki danego rekordu:
# Ten rekord odnosi się tylko do robota "Googlebot": User-agent: Googlebot
Pojedynczy rekord może zawierać więcej niż jedną linię User-Agent:
# Ten rekord odnosi się tylko do robotów "Googlebot" i "MSNBot": User-agent: Googlebot User-agent: MSNBot
Specyfikacja HTML 4.01 wyraźnie zabrania umieszczania kilku linii User-Agent jednej pod drugą, jednak standard (nieopracowany przez W3C) mówi na ten temat zupełnie co innego. Googlebot interpretuje wielokrotne linijki tego typu.
Wielkość liter w nazwach robotów nie ma znaczenia. Lista istniejących robotów wyszukiwarek sieciowych znajduje się na stronach:
- The Web Robots Database - wersja angielska
- Spiders.pl - wersja polska
Zamiast nazwy robota można wpisać również znak gwiazdki ("*"), co wskazuje każdego istniejącego robota. Kiedy robot danej wyszukiwarki odwiedza witrynę, najpierw sprawdza czy istnieje plik robots.txt. Jeśli tak, szuka w nim rekordu (grupy linii), który pasuje do jego nazwy. Jeśli taki znajdzie, odczytuje linie z wybranego rekordu i pomija wszystkie inne. Jeżeli nie znajdzie, szuka rekordu z linią User-Agent: *. Jeżeli takiego nie znajdzie, indeksuje bez ograniczeń wszystkie dokumenty serwisu. Zwracam uwagę, że jeśli robot znajdzie przeznaczony specjalnie dla niego rekord, to w ogóle nie zajmuje się rekordem User-Agent: *.
Disallow#
W rekordach poniżej User-Agent musi się znajdować jedna lub więcej linii Disallow, wskazujących ścieżki do plików, do których robot nie ma dostępu. Każda ścieżka musi rozpoczynać się od znaku ukośnika ("/") i powstaje poprzez wycięcie pierwszego członu adresu URL. Na przykład aby zablokować dostęp do pliku http://www.example.org/index.html, należy wpisać:
User-Agent: *
Disallow: /index.htmlPusta wartość Disallow oznacza brak ograniczeń w indeksowaniu dokumentów:
User-Agent: * # Wszystkie dokumenty serwisu będą normalnie indeksowane: Disallow:
Aby zablokować dostęp do wszystkich plików z jakiegoś katalogu i ewentualnie wszystkich jego podkatalogów, wystarczy wpisać samą nazwę tego katalogu, która koniecznie musi kończyć się znakiem ukośnika ("/"):
User-Agent: * # Żaden plik z katalogu "prywatne" nie zostanie zaindeksowany: Disallow: /prywatne/
Aby zablokować dostęp do wszystkich plików całego serwisu, jako ścieżkę należy podać sam ukośnik:
# Ten serwis w ogóle nie będzie indeksowany przez roboty: User-Agent: * Disallow: /
Allow#
Standard Wykluczania Robotów został rozszerzony o dodatkową dyrektywę - Allow, której działanie jest przeciwne do Disallow, czyli wskazuje ścieżki, które robot może indeksować:
# Tylko strona główna tego serwisu zostanie zaindeksowana:
User-Agent: *
Disallow: /
Allow: /index.htmlDyrektywa Allow może nie być interpretowana przez niektóre roboty wyszukiwarek (jest rozpoznawana przez robota Google).
Wzorce dopasowania#
Co zrobić, jeśli chcemy zablokować indeksowanie wszystkich zdjęć serwisu, ale jednocześnie zezwolić na indeksowanie samych dokumentów HTML? Najlepiej byłoby umieścić wszystkie zdjęcia w osobnym katalogu:
User-Agent: *
Disallow: /zdjecia/Czasem jednak jest to niemożliwe. W takim przypadku pomocne są tzn. wzorce dopasowania, czyli znaki specjalne, które pozwalają dopasować ścieżki na podstawie ogólnych warunków. Googlebot rozpoznaje następujące znaki specjalne w ścieżkach dyrektyw Disallow oraz Allow:
- * - zastępuję dowolny ciąg znaków (również pusty)
- $ - jeżeli zostanie postawiony na końcu ścieżki, oznacza dopasowanie do końca nazwy, dzięki temu nadaje się szczególnie do określania ścieżek do plików określonego typu, czyli o wybranym rozszerzeniu nazwy
Poniższy przykład umożliwia blokowanie indeksowania plików graficznych o konkretnych rozszerzeniach:
User-Agent: Googlebot # Nie indeksuj plików graficznych: Disallow: /*.jpg$ Disallow: /*.jpeg$ Disallow: /*.gif$ Disallow: /*.png$ # Nie indeksuj dokumentów z identyfikatorami sesji: Allow: /*?$ Disallow: /*?
Różnica pomiędzy /*.gif$ a /*.gif jest taka, że w drugim przypadku zablokowane zostaną również pliki: /nazwa.gift, /nazwa.gif/nazwa.html, co raczej nie było naszym zamiarem.
Wzorce dopasowania są rozszerzeniem standardu i mogą być nieobsługiwane przez wiele robotów sieciowych (są interpretowane przez robota Google), dlatego zaleca się nie umieszczać ich w rekordzie User-Agent: *.
Swój plik robots.txt możesz przetestować w specjalnym generatorze napisanym przez Sławomira Kokłowskiego.
Strona kanoniczna#
W niemal każdym serwisie internetowym zdarza się, że ta sama treść jest prezentowana na kilka sposobów, tzn. pod różnymi adresami URL:
- specjalna wersja serwisu przystosowana dla urządzeń mobilnych (telefony komórkowe, palmtopy itp.)
- osobne wersje artykułów przeznaczone do wydruku
- dokumenty zawierające tę samą listę pozycji (produktów, wyników wyszukiwania, artykułów itp.), a jedynie posortowanych w inny sposób - np.
artykuly.php&sortuj=dataiartykuly.php&sortuj=alfabet - obszary witryny wymagające zalogowania użytkownika, kiedy w adresie jest przekazywany identyfikator sesji - np.
index.php?PHPSESSID=0123456789abcdef0123456789abcdeflubindex.php?sid=0123456789abcdef0123456789abcdef - linki prowadzące do tej samej strony mają różną postać:
- jeśli domyślnym numerem strony artykułu będzie 1, to adres
artykul.php&strona=1może być równoważny zartykul.php - podobnie kolejność parametrów adresu URL, podawanych po pytajniku i rozdzielonych znakami
"&", zwykle nie ma znaczenia, tzn. adresartykul.php?id=1&strona=1zwykle jest równoważny zartykul.php?strona=1&id=1 - nazwę pliku
"index.htm","index.html"czy"index.php"zwykle można pominąć podając adres strony, dlategohttp://www.example.com/index.htmljest równoważny zhttp://www.example.com/
- jeśli domyślnym numerem strony artykułu będzie 1, to adres
Teoretycznie nie powinno to przeszkadzać czytelnikom naszej witryny, jednak może stać się problemem w przypadku wyszukiwarek internetowych - takich jak np. Google.
Roboty wyszukiwarek starają się eliminować duplikujące się treści ze swojej bazy zaindeksowanych stron. Oznacza to, że jeśli ta sama lub bardzo podobna treść występuje w Twoim serwisie pod kilkoma różnymi adresami URL, w wynikach wyszukiwania pojawi się tylko jedna jej wersja. Która? To zależy, którą robot indeksujący uzna za podstawową. Niestety to tyko automat dlatego może się mylić, uznając za wersję podstawową adres URL z wieloma niepotrzebnymi parametrami po pytajniku lub wersję artykułu przeznaczoną do wydruku. Może to potencjalnie obniżyć pozycję Twojej witryny w wynikach wyszukiwania oraz wywołać pewną dezorientację czytelnika, który trafił z wyszukiwarki do Twojego serwisu na niewłaściwą wersję dokumentu.
Istnieje jednak możliwość jasnego wskazania robotowi wyszukiwarki, która wersja strony jest tą podstawową - stroną kanoniczną. Aby to zrobić, na każdej wersji takiej strony, która różni się adresem URL od wersji podstawowej, należy podać bezpośredni adres prowadzący do wersji kanonicznej:
<head> <link rel="canonical" href="adres strony podstawowej"> </head>
Jako adres strony podstawowej można podać zarówno adres bezwzględny (rozpoczynający się od http://) jak i względną ścieżkę dostępu do strony, która ma być prezentowana w wynikach wyszukiwania.
Warto zwrócić uwagę, że nie należy w ten sposób oznaczać dokumentów, które nie stanowią jedynie innej wersji strony kanonicznej (podstawowej), ponieważ wywoła to tylko ich niepotrzebną eliminację z wyników wyszukiwania. Trzeba również mieć świadomość, że znacznik ten stanowi jedynie sugestię dla robota wyszukiwarki i może nie być wzięty pod uwagę, jeśli robot z innego powodu uzna, że w danej sytuacji takie oznaczenie strony kanonicznej nie będzie pożądane dla użytkownika korzystającego z wyszukiwarki.