Zestawy znaków#
Wstęp#
W rozdziale "Szkielet dokumentu - Kodowanie znaków" umieściłem wprowadzenie do uzyskania odpowiednich znaków na stronach WWW. Były to informacje podstawowe dla każdego początkującego webmastera. W tej części kursu zaprezentuję bardziej szczegółowe opisy, które mogą być przydatne nie tylko przy projektowaniu stron internetowych.
Ludzie i maszyny#
Komputer (i inne maszyny liczące) operują na binarnym systemie liczbowym (inaczej dwójkowym). W owym systemie występują tylko dwie cyfry: 0 i 1. Wszystkie polecenia i symbole, które wprowadzamy (jako programiści) są zamieniane na ciągi zero-jedynkowe a następnie wykonywane. Oto przykładowy strumień bitów:
1100010111110110100110111010101110010101 zapis binarnyPrzy analizie strumienia bitów najczęściej dzieli się je na części jednobajtowe (1 bajt = 8 bitów) i zapisuje w postaci heksadecymalnej, dzięki czemu całość ma bardziej przystępny i kompaktowy charakter:
11000101 11110110 10011011 10101011 10010101 zapis binarny (5 bajtów)
C5 F6 9B AB 95 zapis heksadecymalny (5 bajtów)Taką wizualizację zapisu binarnego do heksadecymalnego można przeprowadzić za pomocą dowolnego edytora heksadecymalnego (np. Notepada++ w połączeniu z pluginem HexEditor) lub innego konwertera (kalkulator kieszonkowy, narzędzie online, itp.).
Wydawanie komputerowi poleceń w postaci binarnej byłoby skrajnie trudne, wręcz niemożliwe do opanowania przez większość osób. W celu ułatwienia komunikacji z komputerem tworzy się odpowiednie języki programowania oraz zestawy znaków.
Zestaw znaków # (character set) to zestawienie znaków (pisanych, sterujących i innych specjalnego przeznaczenia) z odpowiadającymi im wskaźnikami (np. numerami). Wskaźniki opisujące znaki są unikatowe i nie mogą się powtarzać w obrębie danego zestawu, chociaż różne wskaźniki mogą kierować do tego samego znaku.
Jednym z najbardziej znanych zestawów znaków jest alfabet Morse’a, pozwalający przesyłać informacje za pomocą ciągów długich i krótkich sygnałów.
Poniżej prezentuję przykład fikcyjnego zestawu znaków z numerycznymi wskaźnikami:
wskaźnik znak
1 A
2 B
3 C
4 C
5 C
6 +
... ...Oto dwa podstawowe procesy, którym może być poddawany zestaw znaków w maszynie liczącej:
- kodowanie # (encoding)
Polega na przekształceniu znaków (tj. ich wskaźników) do postaci binarnej rozumianej przez maszynę liczącą. Istnieją różne sposoby kodowania i wynikające z tego konsekwencje (pozytywne jak i negatywne). Zakodowane dane będą przechowywane w formie plików na komputerze (np. na dyskach twardych), przesyłane w sieciach komputerowych lub trzymane i przetwarzane w pamięci operacyjnej.
Załóżmy, że wprowadzamy z klawiatury do edytora znaki "
AAB+". Edytor jest ustawiony tak, że stosuje powyższy zestaw znaków i kodowanie X. Niech kodowanie X polega po prostu na zamianie wskaźników do postaci binarnej o długości jednego bajta, co jest najprostszym sposobem kodowania, bo w zasadzie nie przeprowadza się żadnej szczególnej operacji:"AAB+" wprowadzany tekst 1 1 2 6 wskaźniki dla znaków (zapis dziesiętny) 01 01 02 06 zakodowane wskaźniki (zapis heksadecymalny) 00000001 00000001 00000010 00000110 zakodowane wskaźniki (zapis binarny)- dekodowanie # (decoding)
Polega na przekształceniu danych binarnych (uprzednio zakodowanych) do postaci wskaźników, z których można odczytać i wyświetlić właściwe znaki rozumiane przez ludzi.
Załóżmy, że w dowolnym edytorze tekstowym próbujemy odczytać plik, który otrzymaliśmy w powyższym procesie kodowania. Edytor musi wiedzieć jaki zestaw znaków i jakie kodowanie zostało użyte przy jego tworzeniu. Informacje te można uzyskać na kilka sposobów:
- Z nagłówka (metadanych) pliku.
- Bezpośrednio z danych binarnych pliku, gdzie kilka pierwszych bajtów może zawierać potrzebne informacje (np. znacznik BOM).
- Edytor może próbować sam odgadnąć stosowane kodowanie.
- W ostateczności użyte zostaną domyślne wartości (nawet jeśli wygenerują błędy).
W oparciu o uzyskane informacje przeprowadzany jest proces odwrotny względem kodowania:
00000001 00000001 00000010 00000110 dane binarne (zakodowane wskaźniki) 01 01 02 06 zapis heksadecymalny danych binarnych 1 1 2 6 wskaźniki dla znaków (zdekodowane z danych binarnych) "AAB+" wyświetlony tekst
Na przestrzeni lat powstało wiele różnych zestawów znaków. Większość z nich określała również odpowiednie kody liczbowe. Wszystkie jednak były ograniczone, najczęściej do znaków jednego (lub kilku pokrewnych) języków, lub też były zbyt nieporęczne by można ich było łatwo używać. Obecnie powszechny we wszystkich nowoczesnych aplikacjach i systemach operacyjnych jest międzynarodowy zestaw znaków Unicode (najczęściej w połączeniu z kodowaniem UTF-8 lub UTF-16), zdolny przedstawić wszystkie pisma świata.
Zanim przejdę do opisu aktualnych rozwiązań przeanalizujmy pokrótce wcześniejsze zestawy znaków.
Zestaw znaków obejmuje zwykle przydział przestrzeni numeracyjnej poszczególnym znakom, nie obejmuje zaś sposobów bajtowego zapisu tych znaków. Zestaw znaków to jeszcze nie kodowanie!
ASCII#
Jak wspomniałem na początku, komputery potrafią operować tylko na liczbach, a nie na literach, więc ważne stało się uzgodnienie jednolitego systemu, w którym poszczególne znaki będą reprezentowane za pomocą odpowiadających im liczb.
Jednym z pierwszych zestawów znaków zaprojektowanym we wczesnych latach 60 był ASCII (American Standard Code for Information Interchange). Jak sama nazwa wskazuje był to zestaw przewidziany głównie do użytku na terenie Stanów Zjednoczonych, a więc nie zawierał żadnych diakrytycznych znaków (czyli tych, które pisze się odmiennie, z różnymi akcentami jak ogonki, skreślenia, kropki, daszki).
ASCII jest 7-bitowym kodem przyporządkowującym liczby z zakresu 0-127 do: liter (alfabetu angielskiego), cyfr, znaków przestankowych, symboli oraz poleceń sterującym. Przykładowo litera "a" jest kodowana liczbą 97, a znak spacji jest kodowany liczbą 32.
Zestaw znaków ASCII można podzielić na dwie grupy:
- znaki drukowane - litery, cyfry oraz inne znaki drukowane (95 znaków o kodach
32-126). - znaki sterujące - specjalne polecenia (łącznie 32 o kodach
0-31i127), służące do sterowania urządzeniem odbierającym komunikat, np. drukarką czy terminalem.
7-bitowy kod umożliwia zdefiniowanie łącznej sumy 128 znaków (kody 0-127). Ówczesne procesory mogły bez problemu operować bezpośrednio na takich kodach (bez dodatkowych zabiegów). W 1970 roku opracowano i zaczęto upowszechniać 8-bitowe procesory. Dodatkowy bit początkowo stosowany był jako bit parzystości w transmisji danych. Komputery szybko dotarły jednak do krajów takich jak Polska, Niemcy, gdzie potrzebne było dodanie znaków diakrytycznych, czy też o zupełnie odmiennym piśmie jak cyrylica, czy alfabety z rodziny CJK (daleki wschód). Ze względu na zapotrzebowanie ósmy bit przeznaczono do powiększenia zbioru kodowanych znaków (dodatkowe kody 128 do 255 - łącznie 256 wszystkich możliwości).
Nawet ósmy bit nie wystarczał do zakodowania wszystkich znaków. W odróżnieniu od ASCII, dodatkowe znaki wyrażane kodami 128-255 nigdy nie zostały ustandaryzowane. Wiele firm zaczęło rywalizować i wprowadzać własne rozszerzenia. Przykładem mogą być rozwiązania firm IBM (Code page 437) lub Microsoft (Windows-1251). Mnogość rozszerzeń wymuszana była przez niewielką liczbę dostępnych kodów, dla wielu alfabetów koniecznym stało się tworzenie osobnych zestawów. Nie rzadko zdarzało się, że zestaw jednej firmy nie był kompatybilny z rozwiązaniami konkurencji.
ISO 8859#
W latach 1990 postanowiono rozwiązać problem z przenośnością. Utworzono odpowiedni standard ISO 8859, w którym określono piętnaście różnych zestawów znaków (tzw. stron kodowych # - Code Page) dla wielu alfabetów np. cyrylicy, arabskiego, hebrajskiego, tureckiego czy tajskiego. Są to osobne normy z nadanymi kolejno numerami od ISO-8859-1 do ISO-8859-16 (numer 12 porzucono).
W zależności od tego jaka strona kodowa jest używana, wprowadzane znaki będą zamieniane na odpowiadającą postać binarną, albo odwrotnie (tzn. z postaci binarnej odpowiednio prezentowane, np. na ekranie monitora). Obrazując zagadnienie dokładniej, bajt o wartości 0xA3 (zapis HEX) w stronie kodowej ISO-8859-1 zostanie zamieniony na £ (znak funta), natomiast w stronie kodowej ISO-8859-2 na wielką polską literę Ł. Jednak wszystkie te kodowania mają jedną wspólną część - pierwsze 128 znaków (te, które da się zapisać za pomocą 7 bitów) to podstawowe kodowanie ASCII.
Polskie litery są obecne w ISO-8859-2, ISO-8859-13 i ISO-8859-16. ISO-8859-13 i ISO-8859-16 zawierają prawidłowe cudzysłowy stosowane w języku polskim zgodnie z normą PN-83/P-55366[1] („ i ”), których brak jest w ISO-8859-2. Litery Ą, ą, Ę, i ę istnieją również w ISO-8859-4 i ISO-8859-10 (w tym ostatnim obecne są również Ó i ó).
W przeszłości najbardziej rozpowszechnioną i polecaną stroną kodową dla polskich znaków było ISO-8859-2.
Operowanie na plikach w dalszym ciągu było problematyczne. Otwierając dany zasób musieliśmy wiedzieć w jakim kodowaniu został utworzony. W przeciwnym razie mogliśmy otrzymać źle wyświetloną zawartość.
Sytuacja nie była aż tak tragiczna w przypadku przeglądania stron WWW - można było poinformować przeglądarkę w jakim kodowaniu utworzony został dokument. Niektóre przeglądarki potrafiły wykryć zestaw stosowanych znaków na podstawie analizy częstotliwości wystąpień i innych technik. Niestety było to fałszywe poczucie bezpieczeństwa - efekty mogły być różne.
Oprócz wyżej wymienionych istnieją też kodowania dla języków azjatyckich takie jak Big5 i inne z rodziny GB. Jednak ze względu na zupełnie inną specyfikę tamtejszych języków działają one inaczej.
Podsumowując, do około 1990 roku dokumenty mogły być zapisywane, przechowywane i wymieniane w wielu językach, ale należało wiedzieć, który zestaw znaków został użyty. Nie było również łatwego sposobu do korzystania z dwóch lub większej liczby różnych alfabetów w tym samym dokumencie, a także alfabetów składających się z więcej niż 256 znaków (np. chińskiego czy japońskiego). Ciągły rozwój techniki oraz globalizacja wymusiły utworzenie nowego, bardziej uniwersalnego rozwiązania.
Microsoft używał początkowo terminu "strony kodowe ANSI" (ANSI code page) na określenie 8-bitowych stron kodowych używanych przez interfejs graficzny Windows i w starszych aplikacjach. Określenie to jest mylące, gdyż te strony kodowe nie są normowane przez instytucję ANSI, w rzeczywistości niektóre z nich są częściowo (w różnym stopniu) zgodne z kodowaniami ISO 8859.
Unicode#
W 1987 roku Joe Becker (Xerox), Lee Collins (Apple) i Mark Davis (Apple) rozpoczęli pracę nad utworzeniem uniwersalnego zestawu znaków, który w zamierzeniu miał obejmować wszystkie pisma używane na świecie. Nadali mu nazwę Unicode (w polskim obiegu popularna jest też nazwa Unikod), co ma sugerować, że mamy do czynienia z unikalnym (unique) lub uniwersalnym (universal) kodowaniem (encoding).
Pierwszą propozycję standardu Unicode opublikowano w 1988 roku. Pracę kontynuowano, grupa robocza stale się poszerzała, dlatego też w styczniu 1991 roku powołano konsorcjum Unicode odpowiedzialne za jego dalszy rozwój. W skład konsorcjum Unicode wchodzą ważne firmy komputerowe, producenci oprogramowania, instytuty naukowe, agencje międzynarodowe oraz grupy zainteresowanych użytkowników. Konsorcjum współpracuje również z organizacją ISO, w związku z czym Unicode ma swój odpowiednik w postaci normy ISO 10646, gdzie dla odmiany nazwę zestawu określa skrót UCS (Universal Character Set). Znaki obu standardów są identyczne a różnice objawiają się jedynie w drobnych kwestiach. Pierwsza stabilna wersja Unicode 1.0 została opublikowana w październiku 1991 roku. Aktualnie (rok 2014) mamy do czynienia z wersją 7.0 (zobacz wykaz wszystkich wersji i dat ich publikacji).
Rysunek. Oficjalne logo standardu Unicode
Budowa#
Unicode jest rozbudowanym standardem. Całość składa się z rdzenia specyfikacji (core specification) oraz różnych załączników (appendices) i aneksów (annexes), co przekłada się na setki stron (spis treści PDF, spis treści WWW). Poniżej opiszę jedynie jego najważniejsze cechy.
Unicode każdemu definiowanemu przez siebie znakowi przypisuje unikatowy wskaźnik w postaci numeru, tzw. punkt kodowy # (code point), często nazywany po prostu kodem znaku. Przypisanie ma następującą postać:
U+HEX : NAZWA ANGIELSKA
gdzie HEX to liczba w zapisie szesnastkowym (4, 5 lub 6 cyfr), a cały zapis U+HEX reprezentuje punkt kodowy.
Standard rezerwuje dla punktów kodowych przestrzeń # (codespace) składającą się z 1114112 możliwości (zakres 0x0000 - 0x10FFFF, co można zapisać za pomocą 24 bitów). Olbrzymia przestrzeń biorąc pod uwagę fakt, że w wersji Unicode 7.0 zajęto raptem 113021 punktów kodowych (ok. 10% z dostępnej przestrzeni).
Pierwsza wersja standardu Unicode 1.0 rezerwowała dla punktów kodowych 16-bitową przestrzeń (65536 możliwości). Miała po prostu gromadzić najpopularniejsze znaki, które w owym czasie były w użyciu (w oparciu o analizę drukowanych gazet i czasopism). Dopiero po wprowadzeniu mechanizmu surogatów w wersji Unicode 2.0 przestrzeń dla punktów kodowych rozszerzono.
Tak duża liczba możliwości wymagała opracowania odpowiedniego podziału, który ułatwi tworzenie i zarządzanie standardem. Całą przestrzeń Unicode podzielono na plany # (planes), zwane też poziomami, numerowane od 0 do 16 (łącznie 17). Każdy plan obejmuje 65536 punktów kodowych, co daje łącznie 17 * 65536 = 1114112 możliwości.
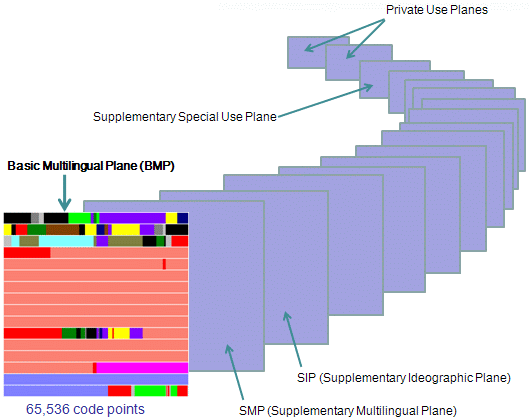
Rysunek. Graficzne zobrazowanie planów Unicode
Oto najważniejsze cechy każdego planu:
- Plane 0: Basic Multilingual Plane (BMP):
0x0000–0xFFFF - Plane 1: Supplementary Multilingual Plane (SMP):
0x10000–0x1FFFF - Plane 2: Supplementary Ideographic Plane (SIP):
0x20000–0x2FFFF - Planes 3–13: Unassigned
- Plane 14: Supplementary Special-Purpose Plane (SSP):
0xE0000–0xEFFFF - Plane 15: Supplementary Private Use Area (S PUA A):
0xF0000–0xFFFFF - Plane 16: Supplementary Private Use Area (S PUA B):
0x100000–0x10FFFF
W planie zerowym, czyli w Bazowym Planie Wielojęzyczny # (Basic Multilingual Plane, skrót BMP), zebrano większość powszechnie używanych znaków. Punkty kodowe z poziomu BMP zapisuje się za pomocą 4 cyfr HEX (np. U+0058). Poza poziomem BMP wymagane jest użycie 5 lub 6 cyfr HEX (np. U+E0001 lub U+10FFFD).
W obrębie każdego planu znaki są rozmieszczane w nazwanych blokach # (block), które w pewnym stopniu je charakteryzują. Ostatnio wszystkich bloków ze wszystkich planów było 249. Chociaż bloki mają różne rozmiary, to zawsze są wielokrotnością 16 punktów kodowych, i bardzo często wielokrotnością 128 punktów kodowych. Bloki mogą obejmować znaki podstawowe (Basic Latin) jak i wiele specyficznych symboli danego alfabetu (np. Armenian, Arabic) czy innego zagadnienia (np. Mathematical Operators, Geometric Shapes). Przy tworzeniu tekstu może zajść sytuacja, że będziemy musieli korzystać ze znaków różnych bloków (czasami nawet z różnych planów).
Dla przykładu znak dolara ("$") w Unicode będzie opisany jak na poniższej ilustracji:

Rysunek. Opis znaku dolara ("$") w standardzie Unicode
Każdy kod znaku ma właściwość określającą do jakiej głównej kategorii # (general category) przynależy (np. Litera, Liczba, Znak, Symbol, Separator lub Inne). W ramach tych kategorii istnieją dalsze podziały (np. małe czy duże litery). Przydaje się to do ewentualnego dalszego przetwarzania tekstu.
Jeśli masz kilka godzin możesz przejrzeć wszystkie możliwe znaki w trybie online za pomocą aplikacji Unicode Slide Show. Bardzo fajny skrypt z możliwością regulacji wielu parametrów.
Warto podkreślić, że pierwsze 128 punktów kodowych (zakres 0-127) są takie same jak w ASCII. Zakres 128-255 zawiera symbole walut i inne typowe znaki oraz litery akcentowane (wiele zaczerpnięto z ISO-8859-1). Po 256 znajduje się więcej znaków akcentowanych. Po 880 rozpoczynają się poszczególne alfabety oraz specyficzne zagadnienia.
To nie wszystko. Niektórym znakom przydzielono także właściwość kierunkowość # (directionality property), pozostałe mają charakter neutralny (mogą dziedziczyć kierunkowość). Wykorzystywana jest ona przez specjalny dwukierunkowy algorytm Unicode, który pozwala mieszać w jednej linii różne rodzaje pism (lewostronne lub prawostronne). Algorytm uruchamiany jest samoczynnie (z możliwością ręcznego sterowania), zatem daje spore możliwości przy tworzeniu wielojęzycznych dokumentów. Wewnętrzne mechanizmy rządzące algorytmem łatwe do zrozumienia nie są, niemniej jednak warto poznać jego najważniejsze cechy.
Unicode jest świetnym pomysłem, w jednym miejscu znajdują się oznaczenia numeryczne dla wszystkich możliwych znaków używanych na świecie (a nawet tych zapomnianych, jak w przypadku egipskich hieroglifów). Nie ma potrzeby stosowania odmiennych zestawów znaków dla różnych wersji plików. Problemy z poprawnym wyświetlaniem treści (głównie stron internetowych) powoli acz sukcesywnie odchodzą do przeszłości (jedyną bolączką pozostaje niewiedza autorów).
Kodowanie UTF/UCS#
Unicode jako standard jest tylko zestawem znaków, który został w dość jasny i precyzyjny sposób opisany (z możliwością dalszego rozszerzania). Następnie należało ów standard wdrożyć w już istniejących systemach informatycznych (tj. zapisać za pomocą bitów, tak jak robiliśmy to w pierwszym przykładzie teoretycznym).
I tu pojawia się problem - standard definiuje więcej niż 256 znaków, których nie da się zapisać za pomocą 8 bitów. Unicode (jako całość) nie pasuje wprost do 8 bitów, a nawet do 16. Chociaż obecnie zdefiniowano ponad 111 tysięcy punktów kodowych, można ich określić maksymalnie do 1114112, co wymagałoby aż 21 bitów.
Od 1970 roku minęło sporo czasu. 8-bitowe procesory stały się przestarzałe. Obecne komputery wyposażone są w 64-bitowe procesory, zatem dlaczego nie moglibyśmy wyjść poza 8-bitowe znaki przeskakując na 64-bitowe?
Prawdę mówiąc możemy. Wiele programów komputerowych napisanych np. w języku C lub C++ obsługuje dane tekstowe w postaci 32 bitów (typ wchar_t). Python od wersji 3.3 przechowuje łańcuchy znakowe w 32 bitach (aczkolwiek z optymalizacją wiodących 0). Można zatem powiedzieć, że nowoczesne programy (wliczając w to przeglądarki internetowe) stosują wewnętrznie szerszą prezentację i teoretycznie mogą rozpoznawać ponad 4 miliardy różnych znaków. To wystarczająco dla Unicode.
Skoro przeglądarki radzą sobie z Unicode nawet w 32 bitach, to gdzie leży problem? Problemem jest wysyłanie, odbieranie, odczytywanie i zapisywanie znaków. Oto powody:
- Wiele istniejących programów oraz protokołów wysyła/odbiera oraz odczytuje/zapisuje w 8-bitowych porcjach danych.
- Stosowanie 32-bitów przy wysyłaniu/odbieraniu tekstu czterokrotnie zwiększa ilość przesyłanych danych oraz miejsce wymagane do ich zapisu.
Mimo że przeglądarki mogą operować wewnętrznie na długich ciągach tekstowych, to nadal musimy pobierać dane z serwera do przeglądarki (i wysyłać z powrotem), a także zapisywać je w pliku lub bazie danych. Więc dalej potrzebny jest sposób prezentacji 111 tysięcy punktów kodowych za pomocą 8 bitów. Za to zadanie odpowiedzialne jest kodowanie i operacja odwrotna, czyli dekodowanie.
Można by się zastanawiać, w jaki sposób używać 8-bitowego (1-bajtowego) kodowania do zapisu punktu kodowego zajmującego więcej niż jeden bajt? Nic trudnego, w razie konieczności należy każdy punkt kodowy wyrazić za pomocą dwóch lub większej liczby bajtów.
Istnieje kilka metod kodowania, najpopularniejsze to UTF (Unicode Transformation Format) i UCS (Universal Character Set). Do najważniejszych należą:
- UTF-32/UCS-4 (4 bajty dla każdego punktu kodowego)
- UTF-16/UCS-2 (2 bajty dla każdego punktu kodowego z BMP i 4 bajty dla punktów kodowych z pozostałych planów)
- UTF-8 (1 bajt dla ASCII, 2 bajty dla popularnych punktów kodowych z BMP, 3 bajty dla reszty punktów kodowych z BMP i 4 bajty dla punktów kodowych z pozostałych planów)
Oczywiście jest ich więcej, przykładowo: UTF-18, UTF-9, UTF-7, UTF-6, UTF-5, UTF-1. Najbardziej popularne to UTF-16 (stosowane w systemach operacyjnych np. Windows lub Mac OS X) oraz UTF-8 (przy stronach WWW). Specyficzny jest UTF-7 wykorzystywany przy przesyłaniu maili - wykorzystuje tylko 7 bitów, czyli tablicę ASCII, a pozostałe znaki są kodowane w specjalny sposób.
Świadomie pomijam opisy dla wszystkich starszych jednobajtowych zestawy znaków (tj. różne warianty ISO 8859), bo w ich przypadku wskaźniki dla znaków zajmują przestrzeń jednego bajta i nie wymagają żadnych specyficznych zabiegów przy kodowaniu/dekodowaniu.
Kodowanie znaków najczęściej przeprowadzane jest automatycznie bez naszej ingerencji. W edytorach tekstowych ustawiamy w opcjach odpowiednie kodowanie, proces uruchamia się samoczynnie podczas zapisu i odczytu każdego pliku. Dla stron internetowych wprowadzamy znacznikiem <meta> odpowiednią stronę kodową wprost w plikach (X)HTML, która informuje przeglądarkę w jaki sposób ma zdekodować dany plik. Możliwe jest także ustawienie kodowania w nagłówkach serwerowych.
Można więc powiedzieć, że wiedza na temat algorytmów używanych w każdym kodowaniu nie jest niezbędna przy codziennej pracy z plikami tekstowymi. Warto jednak poznać podstawy, które wyjaśnią, dlaczego w danym segmencie jeden rodzaj kodowania sprawdza się lepiej niż inny.
Dalszy wywód będzie dotyczył trzech odmian kodowania Unicode (UTF-32, UTF-16 i UTF-8), bo w zasadzie stały się standardem, a wszystkie wcześniejsze rozwiązania pozostały w obiegu tylko i wyłącznie ze względów kompatybilnościowych.
W przypadku kodowania istotnym pojęciem będzie jednostka kodowa # (code unit), która informuje o minimalnej liczbie bitów, jaka jest wymagana do zakodowania punktu kodowego w danym kodowaniu. Numer w nazwie kodowania (ten za łańcuchem "UTF-" w nazwie) wskazuje na długość jednostki kodowej (w bitach). Jeśli punkt kodowy jest za duży, aby mógł być zapisany za pomocą pojedynczej jednostki kodowej, to musi zostać wyrażony większą liczbą jednostek kodowych. Oznacza to, że liczba jednostek kodowych potrzebna do zaprezentowania jednego punktu kodowego może się zmieniać (dotyczy tylko UTF-8 i UTF-16). Rzućmy okiem na poniższą tabelę:
| Punkt kodowy | Kodowanie | Jednostki kodowe (HEX) | Liczba jednostek kodowych |
|---|---|---|---|
| U+0041 (A) | UTF-32BE | 00 00 00 41 | 1 |
| UTF-16BE | 00 41 | 1 | |
| UTF-8 | 41 | 1 | |
| U+0141 (Ł) | UTF-32BE | 00 00 01 41 | 1 |
| UTF-16BE | 01 41 | 1 | |
| UTF-8 | C5 81 | 2 | |
| U+32B4 (∓) | UTF-32BE | 00 00 22 13 | 1 |
| UTF-16BE | 22 13 | 1 | |
| UTF-8 | E2 88 93 | 3 | |
| U+264FB (𦓻) | UTF-32BE | 00 02 64 FB | 1 |
| UTF-16BE | D8 59 DC FB | 2 | |
| UTF-8 | F0 A6 93 BB | 4 |
Z praktycznego punktu widzenia będzie to istotne przy przetwarzaniu łańcuchów znakowych np. w JavaScripcie lub DOM i może być źródłem wielu niepotrzebnych komplikacji (szczególnie bez uprzedniego zgłębienia tematu).
UTF-32#
Dlaczego akurat kodowanie UTF-8 stało się standardem w ekosystemie webowym przy przesyle danych? Żeby odpowiedzieć na to pytanie należałoby zacząć od wyjaśnienia "najobszerniejszego" sposób kodowania, tj. UTF-32.
W kodowaniu UTF-32 jednostka kodowa ma 32 bity (4 bajty), czyli sekwencja jednostek kodowych dla pojedynczego punktu kodowego będzie miała stałą długość (równą jeden). Wynika to z faktu, że 4 bajty na jedną jednostkę kodową mogą przyjąć wartość od 0x0 do 0xFFFFFFFF, a punkty kodowe zdefiniowane w Unicode zajmują jedynie przestrzeń od 0x0 do 0x10FFFF. Z tego względu jednostka kodowa w kodowaniu UTF-32 jest bezpośrednią reprezentacją punktu kodowego (żadne dodatkowe obliczenia nie są potrzebne).
Wadą kodowania UTF-32 jest to, że marnuje bardzo dużo miejsca. Większość punktów kodowych przypisana znakom europejskich języków zajmuje przestrzeń od 0x0 do 0xFFFF. W efekcie prawie zawsze przynajmniej połowa bitów w jednostce kodowej będzie zerowa.
Stała długość sekwencji jednostek kodowych dla pojedynczego punktu kodowego (w przeciwieństwie do m.in. UTF-8 czy UTF-16) jest dużą zaletą tego kodowania w przypadku wewnętrznego operowania na danych tekstowych. Kodowanie to jest jednak bardzo nieefektywne przy przesyle/zapisie - zakodowane ciągi znaków są od dwóch do czterech razy dłuższe niż ciągi tych samych znaków zapisanych w innych kodowaniach. Kodowanie to z tego powodu jest zwykle stosowane tylko w pamięci operacyjnej w celu ułatwienia przetwarzania (np. przy obliczaniu długości czy wycinaniu ciągu znaków), aczkolwiek na innych nośnikach (takich jak połączenia sieciowe czy dyski twarde) stosuje się zwykle bardziej efektywne (pod względem objętościowym) UTF-8 lub UTF-16.
Poniżej zamieszczam wynik kodowania UTF-8/UTF-16/UTF-32 dla łańcucha znakowego "Ćma" (postać binarna i heksadecymalna):
BIN
UTF-8 11000100 10000110 01101101 01100001
UTF-16 00000001 00000110 00000000 01101101 00000000 01100001
UTF-32 00000000 00000000 00000001 00000110 00000000 00000000 00000000 01101101 00000000 00000000 00000000 01100001
HEX
UTF-8 C4 86 6D 61
UTF-16 01 06 00 6D 00 61
UTF-32 00 00 01 06 00 00 00 6D 00 00 00 61Łatwo zauważyć, który format zajmuje najmniej miejsca, przez co najbardziej nadaje się do archiwizacji lub przesyłania plików.
UTF-16#
Kodowanie UTF-16 jest bardzo ciekawe i istotne z punktu widzenia programistycznego. Jest tak dlatego, że w wielu systemach i językach programowania jest ono wewnętrzną reprezentacją danych tekstowych. Żeby nie szukać daleko wystarczy że wymienię chociażby JavaScript i DOM (kluczowe języki Webu). Bez znajomości wszystkich aspektów technicznych swobodne operowanie na łańcuchach znakowych będzie utrudnione.
W kodowaniu UTF-16 jednostka kodowa ma 16 bitów (2 bajty), czyli sekwencja jednostek kodowych dla pojedynczego punktu kodowego będzie miała zmienną długość (jeden lub dwa). W przypadku planu BMP jednostka kodowa jest bezpośrednią reprezentacją punktu kodowego (żadne dodatkowe obliczenia nie są potrzebne).
Powyższe rozwiązanie to pierwowzór pochodzący z Unicode 1.0, który zakładał, że dwóbajtowa przestrzeń dla wszystkich punktów kodowych w zupełności wystarczy. Szybko okazało się to nieprawdą i kolejna wersja standardu poszerzyła przestrzeń dla punktów kodowych (ktoś dostrzega analogię z adresami IPv4?). Zanim to nastąpiło Unicode upowszechnił się na tyle, że gmeranie przy kodowaniu UTF-16 było wyjątkowo delikatnym procesem. Tak czy inaczej zaszła potrzeba zakodowania przy użyciu UTF-16 kolejnych punktów kodowych, ale bez negatywnego wpływu na już istniejące implementacje. Odbywa się to poprzez zastosowanie dwóch jednostek kodowych tworzonych w oparciu o surogaty.
Surogat # (surrogate) to punkt kodowy umieszczony w zakresie od U+D800 do U+DFFF. Zakres ten występuje w planie BMP i jest zastrzeżony. Nie można używać surogatów w innym celu, są przeznaczone tylko i wyłącznie dla kodowania UTF-16. Surogaty dzieli się na dwa rodzaje:
- surogat górny # (hight|leading surrogate) - zakres od
U+D800doU+DBFF(1024 punkty kodowe). - surogat dolny # (low|trailing surrogate) - zakres od
U+DC00doU+DFFF(1024 punkty kodowe).
Surogat górny po którym następuje surogat dolny tworzy parę surogatów # (surrogate pair), i para ta wyraża zakodowane 1048576 punkty kodowe spoza planu BMP. Ze względu na konieczność zdefiniowania surogatów faktyczna przestrzeń dla pozostałych znaków skurczyła się i można ją wyrazić przedziałami U+0000..U+D7FF oraz U+E000..U+10FFFF (1112064 punktów kodowych). Wartości punktów kodowych (z wykluczeniem surogatów) są często nazywane wartościami skalarnymi # (scalar value).
Algorytm kodowania z wykorzystaniem surogatów można wyjaśnić w kilku prostych krokach:
- Odejmujemy od punktu kodowego (zakres
0x10000do0x10FFFF) liczbę0x10000(czyli ilość punktów kodowych z planu BMP, których kodować nie trzeba). Zostaje nam wtedy zawsze 20-bitowa liczba w zakresie0x00000do0xFFFFF. - Górne 10 bitów (tworzące liczbę w zakresie
0x000do0x3FF) dodajemy do liczby0xD800(czyli do początkowego zakresu dla surogatów górnych). Tym sposobem otrzymamy konkretny surogat górny (zakres0xD800do0xDBFF). - Dolne 10 bitów (tworzące liczbę w zakresie
0x000do0x3FF) dodajemy do liczby0xDC00(czyli do początkowego zakresu dla surogatów dolnych). Tym sposobem otrzymamy konkretny surogat dolny (zakres0xDC00do0xDFFF). - Zakodowany punkt kodowy będzie składał się z dwóch jednostek kodowych: surogat górny surogat dolny.
Dekodowanie dwóch jednostek kodowych (surogatu górnego i surogatu dolnego) do punktu kodowego wyraża proste równanie:
punkt kodowy =0x10000+ (surogat górny -0xD800) *0x400+ (surogat dolny -0xDC00)
Taki sposób kodowania zapewni nam, że nigdy nie pomylimy górnego i dolnego surogatu. Zakazanie przedziału surogatów w Unicode zapewnia również to, że nigdy nie pomylimy surogatu z żadnym innym znakiem. Poniżej zamieszczam tabelę pomagającą w wyobrażeniu sobie, jakie zakresy punktów kodowych możemy zakodować za pomocą kombinacji surogatów.
| High \ Low | U+DC00 | U+DC01 | ... | U+DFFF |
|---|---|---|---|---|
| U+D800 | U+10000 | U+10001 | ... | U+103FF |
| U+D801 | U+10400 | U+10401 | ... | U+107FF |
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ |
| U+DBFF | U+10FC00 | U+10FC01 | ... | U+10FFFF |
Większy wykaz gotowych kombinacji dla surogatów można odczytać z tabeli onlie.
W ramach utrwalenia zakodujmy punkt kodowy U+1F4A9 (💩) przy użyciu UTF-16 zgodnie z powyższymi wytycznymi:
0001 1111 0100 1010 1001 = 0x1F4A9
- 0001 0000 0000 0000 0000 = 0x10000
---------------------------
0000 1111 0100 1010 1001 = 0xF4A9
górny surogat:
1101 1000 0000 0000 = 0xD800
+ 00 0011 1101 = 0x003D
----------------------
1101 1000 0011 1101 = 0xD83D
dolny surogat:
1101 1100 0000 0000 = 0xDC00
+ 00 1010 1001 = 0x00A9
----------------------
1101 1100 1010 1001 = 0xDCA9
dwie jednostki kodowe dla punktu kodowego U+1F4A9:
0xD83D 0xDCA9
Operacja odwrotna:
punkt kodowy = 0x10000 + (0xD83D - 0xD800) * 0x400 + (0xDCA9 - 0xDC00)
punkt kodowy = 0x10000 + 0x3D * 0x400 + 0xA9
punkt kodowy = 0x10000 + 0xF400 + 0xA9
punkt kodowy = 0x1F4A9UTF-8#
Kodowanie UTF-8 w porównaniu z poprzednio omawianymi UTF-32 i UTF-16 to jeszcze inna para kaloszy. Jednostka kodowa w UTF-8 ma 8 bitów (1 bajt) czyli sekwencja jednostek kodowych dla pojedynczego punktu kodowego będzie miała zmienną długość (od jednego do sześciu). Pierwsze punkty kodowe Unicode są kodowane jednym bajtem i tym samym są identyczne z kodem ASCII. Kolejne punkty kodowe są odpowiednio kodowane 2, 3, 4, 5 i 6 bajtami.
Zasada kodowania w UTF-8 jest taka: pierwsze bity pierwszego bajtu określają precyzyjnie z ilu jednostek kodowych składa się cała zakodowana sekwencja dla pojedynczego punktu kodowego. Kolejne bajty mają za to stały 2-bitowy prefiks (10). Pokazuje to poniższa tabelka:
| Bitów dla danych | Ostatni punkt kodowy | Bajt 1 | Bajt 2 | Bajt 3 | Bajt 4 | Bajt 5 | Bajt 6 |
|---|---|---|---|---|---|---|---|
| 7 | U+007F | 0xxxxxxx | |||||
| 11 | U+07FF | 110xxxxx | 10xxxxxx | ||||
| 16 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | U+1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 26 | U+3FFFFFF | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 31 | U+7FFFFFFF | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Przyjrzyjmy się dokładniej tej tabelce. W zapisie 0xxxxxxx dla bajtu pierwszego (wiersz pierwszy), cyfra 0 oznacza, że znak składa się z 0 bajtów (tylko 7 bitów, identycznych jak w ASCII). W ostatnim wierszu tabelki zapis 1111110x dla bajtu pierwszego oznacza, że znak składa się z 6 bajtów (ponieważ występuje sześć jedynek). Znaki x są zastępowane poszczególnymi bitami każdego punktu kodowego - czyli właściwe dane zawsze przechowywane są za pierwszym zerem w każdym bajcie.
Sam przebieg kodowania najlepiej wyjaśnić na prostym przykładzie. Weźmy na warsztat literę "ą", która w Unicode ma następującą postać punktu kodowego:
U+0105 // punkt kodowy UnicodeZ tabelki widać, że potrzebujemy do jego zakodowania w UTF-8 przynajmniej dwóch bajtów. Najpierw rozbijmy nasz punkt kodowy na dwa bajty, a następnie zamieńmy go na zapis binarny:
01 05 // HEX
00000001 00000101 // binarnieW zapisie binarnym wszystkie zera wiodące (z lewej strony) możemy pominąć, usuńmy więc siedem pierwszych:
00000001 00000101 // binarnie
_______1 00000101 // binarnieTeraz dla maski 2-bajtowej (drugi wiersz tabeli) wszystkie bity punktu kodowego umieszczamy w miejsca x zaczynając od prawej strony i kierując się w lewo, a pozostałe pola x wypełniamy po prostu zerami:
100 000101 // binarnie
110XXXXX 10XXXXXX // maska
11000100 10000101 // utf-8W omawianym przykładzie do zakodowania litery "ą" używaliśmy 2 bajtów. Była to minimalna wartość, możliwe jest jednak zastosowanie większej liczby bajtów:
11000100 10000101 // 2 bajty
11100000 10000100 10000101 // 3 bajty
11110000 10000000 10000100 10000101 // 4 bajty
itd.Wszystko odbywa się na tej samej zasadzie jak w przypadku zapisu dla dwóch bajtów. Oznacza to, że ten sam znak można zapisać na kilka sposobów. Stanowi to zagrożenie bezpieczeństwa m.in. dla serwerów. Z tego powodu standard UTF-8 przewiduje, że poprawny jest wyłącznie najkrótszy możliwy sposób zapisu, a każdy program musi odrzucać znaki zapisane dłuższymi sekwencjami niż minimalna.
Oryginalna specyfikacja obejmuje konwersję właściwych danych o rozmiarze 31 bitów, które zapisane zostaną za pomocą 6 bajtów (pierwotna granica z kodowania UCS). Oferuje zatem większą liczbę kombinacji (7FFFFFFF) niż sam Unicode (10FFFF). W listopadzie 2003 roku UTF-8 został ograniczony (RFC 3629) do identycznej przestrzeni (10FFFF). Usunięto zatem wszystkie sekwencje 5 i 6-bajtowe, oraz połowę sekwencji 4-bajtowych.
Dekodowanie najlepiej zaprezentować na poprzednio zakodowanej literze "ą". Załóżmy że mamy następujący strumień bitów:
110010010000101....... // "ą" w utf-8 + reszta danychOto przykładowy algorytm postępowania (bez wykrywania BOM i kroków obsługujących błędy):
- Pobieramy pierwszy bajt ze strumienia (
11001001). - Jeśli najbardziej znaczący bit jest zerem, to znaczy, że mamy do czynienia ze znakiem z ASCII. Wystarczy odczytać wartość z siedmiu kolejnych bitów.
W przeciwnym razie należy ustalić ilość zakodowanych bajtów przypadających na znak wprost z pierwszych najbardziej znaczących bitów, które mają wartość
1(u nas są dwie jedynki, co oznacza dwa bajty na znak). Następnie pobieramy kolejne brakujące bajty (pierwszy już mamy pobrany). Nasza zdekodowana wartość będzie składała się z kolejno odczytanych bitów w każdym pobranym bajcie, zaczynając zaraz za pierwszym najbardziej znaczącym bitem, którego wartością jest zero:11000100 10000101 // utf-8 00100000101 = 0x105 = U+0105 = "ą"- Cały proces powtarzamy dla kolejnych bajtów w strumieniu.
Popularność UTF-8 wynika przede wszystkim z tego, że większość treści w Internecie stosuje podstawowe symbole amerykańskie (po zakodowaniu zajmują tylko 1 bajt), a co za tym idzie dokumenty zapisane znakami ASCII są dokładnie identyczne w przypadku tego kodowania, jak i wszystkich starszych kodowań jednobajtowych zgodnych z ASCII. Również w przypadku znaków spoza ASCII wielkość takiego znaku dla języków europejskich wzrasta jedynie do 2 bajtów.
Wyjątkiem mogą być egzotyczne alfabety, jak np. arabski czy cyrylica, gdzie oszczędności wynikające ze stosowania UTF-8 okazują się gorsze niż przy użyciu UTF-16:
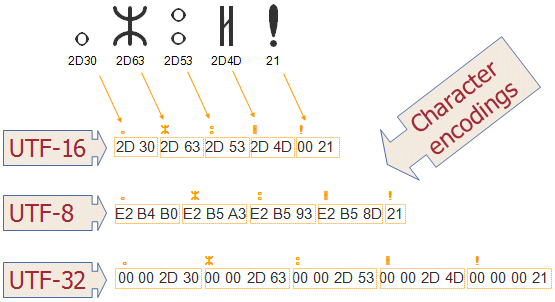
Rysunek. Egzotyczne znaki kodowane różnymi wariantami UTF
Ze względu na niewielkie rozmiary wynikowe (w większości przypadków) UTF-8 jest najodpowiedniejszy do zastosowań w nowoczesnych środowiskach, w których ma zachodzić wymiana informacji w sposób jak najbardziej oszczędny.
UTF-8 to domyślne kodowanie dokumentów XML i formatów opartych na nim (w tym XHTML).
Kolejność zapisu bajtów (endianness i BOM)#
Ostatni szczegół, który wypadałoby wyjaśnić to kolejność zapisu bajtów. Czasami jest to istotne w przypadku tworzenia i wymiany dokumentów, ponieważ może prowadzić do problematycznych zachowań.
W sytuacji, kiedy pewne dane zapisywane są przy użyciu wielu (przynajmniej dwóch) bajtów, nie istnieje jeden unikatowy sposób uporządkowania tych bajtów w pamięci lub w czasie transmisji przez dowolne medium. Żeby wszystko działało poprawnie musi być użyta jedna z konwencji ustalająca kolejność bajtów (tzw. endiannesss lub endian). Jest to analogiczne do zapisu pozycyjnego liczb lub kierunku pisma w różnych językach – ze strony lewej na prawą albo z prawej na lewo.
Weźmy kolejny raz na warsztat literę "ą", która w UTF-32 będzie miała następującą postać heksadecymalną dla jednostki kodowej:
00000105 // jednostka kodowa w UTF-32 dla litery "ą"Poszczególne bajty możemy zapisać w pamięci na dwa sposoby:
00 00 01 05
lub
05 01 00 00Pierwszy z nich to tzw. Big-Endian (skrót BE). Jest to forma zapisu danych, w której najbardziej znaczący bajt (high-order byte) umieszczany jest jako pierwszy. Jest ona analogiczna do używanego na co dzień sposobu zapisu liczb. Procesory, które używają formy Big-Endian, to między innymi SPARC, Motorola 68000, PowerPC 970, IBM System/360, Siemens SIMATIC S7.
Drugi sposób nosi nazwę Little-Endian (skrót LE). Jest to forma zapisu danych, w której najmniej znaczący bajt (low-order byte) umieszczony jest jako pierwszy. Jest ona odwrotna do używanego na co dzień sposobu zapisu liczb. Procesory, które używają formy Little-Endian, to między innymi wszystkie z rodziny x86, x86-64, Atmel AVR, DEC VAX.
Istnieją także procesory, w których można przełączyć tryb kolejności bajtów, należą do nich na przykład PowerPC (do serii PowerPC G4), SPARC, ARM, MIPS.
Istnieje sposób, który pozwala wprost określić jaka forma została użyta przy kodowaniu (BE czy LE). Ten sam sposób jest często używany, żeby w ogóle zaznaczyć, że tekst jest zakodowany za pomocą UTF. Tym sposobem jest BOM (Byte Order Mark - znacznik kolejności bajtów). Jest to specjalny ciąg bajtów podawany na samym początku strumienia bajtów (pliku), który informuje w jakiej kolejności należy ustawić bajty, aby odczytać punkt kodowy (w procesie dekodowania). Poniższa tabelka pokazuje różne warianty BOM w zależności od zastosowanego kodowania UTF:
| Kodowanie | BOM dla Little-Endian | BOM dla Big-Endian |
|---|---|---|
| UTF-16 | FF FE | FE FF |
| UTF-32 | FF FE 00 00 | 00 00 FE FF |
| UTF-8 | EF BB BF (ani Little-Endian ani Big-Endian) | |
Poniższa grafika prezentuje bajty stosowane w sekwencji dwóbajtowych jednostek kodowych (kodowanie UTF-16). Każdy dwucyfrowy numer heksadecymalny stanowi jeden bajt w strumieniu bajtów. Widać wyraźnie, że kolejność dwóch bajtów, które reprezentują jedną jednostkę kodową, jest odwrócona w zależności od zapisu BE czy LE:

Rysunek. Znacznik BOM w strumieniu bajtów z kodowaniem UTF-16
Kiedy dane są wymieniane między systemami, to bajty zapisane w jednym porządku (np. BE) są najpierw wysyłane przez pierwszy system, a następnie odbierane i przetwarzane przez inny system. Żeby cały proces przebiegał poprawnie między systemami stosującymi odmienne formaty, to system odbierający musi wiedzieć w jaki sposób przetworzyć dane. W tym celu stosuje się właśnie BOM, który np. w postać 0xFFFE poinformuje system odbierający, że przed przetworzeniem danych należy odwrócić bajty.
Przestawianie bajtów dotyczy tylko pojedynczej jednostki kodowej, która składa się z więcej niż jednego bajta (tj. występuje jedynie dla kodowania UTF-16 i UTF-32). Jeśli jeden punkt kodowy jest wyrażany przez kilka jednostek kodowych, to kolejność bajtów zamienia się tylko między bajtami w poszczególnych jednostkach kodowych. Kolejność między samymi jednostkami kodowymi nie ulega zmianie. W przypadku UTF-8 jednostka kodowa jest jednobajtowa i dlatego przestawianie bajtów nie zachodzi.
BOM powiększa rozmiar danych o kilka bajtów. Sygnatura nie jest zwykle stosowana w systemach, gdzie z góry jest ustalony sposób kodowania (np. protokoły sieciowe zwykle stosują UTF-8 albo UTF-16BE), albo mają oddzielne mechanizmy deklaracji kodowania (nagłówki MIME, nagłówki XML, znacznik <meta> w HTML).
Sygnatura BOM może powodować pewne problemy w edytorach tekstowych (głównie tych starszych). Przykładowo, narzędzia Microsoftu, w tym Notatnik (Notepad), dla rozpoznanego pliku kodowanego w UTF-8 dopisują znacznik kolejności bajtów. Sygnaturę BOM najłatwiej rozpoznać dla pustego dokumentu (w którym nie zapisaliśmy żadnego znaku). Plik taki zawsze będzie miał wielkość 3 bajtów (bez BOM rozmiar wynosi 0 bajtów).
Rysunek. Strony kodowe dostępne w Notatniku
Znak BOM uniemożliwia niektórym starszym przeglądarkom prawidłowe rozpoznanie DOCTYPE dokumentu, w konsekwencji przełączając go w tzw. Quirks Mode.
Sygnatura BOM pojawia się zawsze na początku pliku, więc problemy z wyświetlaniem pojawiają się najczęściej na górze strony. Jednak puste wiersze mogą pojawić się też w dalszej części strony, jeżeli dołączono do niej tekst z oddzielnego pliku, który rozpoczynał się sygnaturą BOM. W niektórych przeglądarkach BOM może być widoczny jako "ďťż".
W ramach uzupełnienia warto zapoznać się z następującymi wpisami: "UTF-8, UTF-16, UTF-32 & BOM" i "The byte-order mark (BOM) in HTML".
Co ciekawe, jeśli otworzymy w Notatniku plik zapisany za pomocą kodowania UTF-8, ale bez BOM, to Notatnik prawidłowo odczyta plik. Dopiero wybranie polecenia Zapisz jako spowoduje dodanie sygnatury BOM.
Kodowanie UTF-8 nie potrzebuje znacznika kolejności bajtów (BOM), ponieważ jednostka kodowa ma stałą długość (8 bitów) i kolejność bajtów jest jednoznaczna. Stąd też BOM dla UTF-8 jest nieobowiązkowy, ale wciąż dopuszczalny. W przypadku użycia często nazywany jest po prostu sygnaturą UTF-8 (UTF-8 signature).
Część edytorów próbuje wykryć kodowanie pliku, jeśli BOM nie jest dostępny (przez analizę dalszej zawartości pliku, czy analizę statystyczną), inne wyświetlą plik tak, jakby był zakodowany jednobajtowo. Starsze i mniej zaawansowane edytory mogą w ogóle nie reagować na znacznik BOM, lub pokazać go jako znaki niedrukowalne na początku pliku. Inne (np. wspomniany Notatnik) starają się wykryć kodowanie wielobajtowe. Jednak przy zapisie takiego pliku samoczynnie dodają znacznik wykrytego kodowania (co może powodować wiele problemów).
Pliki UTF-8 bez znaku BOM dobrze działają z większością przeglądarek (nawet tak archaicznych jak Netscape 4) i robotów sieciowych. Dlatego podczas pisania stron WWW wybierz "normalny" edytor tekstowy (osobiście polecam Notepada++), który wykrywa kodowanie, ale pozwala wybrać, czy dany plik zostanie zapisany z/bez znacznika BOM - zabytkowe wynalazki Microsoftu omijaj szerokim łukiem.
Fonty i prezentacja znaków#
Obsługa standardu Unicode w połączeniu z prawidłowym kodowaniem/dekodowaniem nie musi wcale oznaczać, że na każdym urządzeniu i w każdej aplikacji wyświetlony zostanie pożądany znak. Wszystko zależy od zastosowanego fontu, w którym umieszcza się graficzną prezentację punktów kodowych. Aplikacja dekoduje strumień bajtów do punktów kodowych po czym wyszukuje dla nich symbole graficzne w danym foncie, aby móc je wyświetlić na ekranie monitora lub przygotować do druku.
Trzeba mieć świadomość tego, że Unicode to ogromny zestaw znaków i utworzenie fontu, który pokrywałby wszystkie dotychczas zdefiniowane punkty kodowe, byłoby bardzo czasochłonne i niezwykle kosztowne. Font taki zajmowałby sporo megabajtów, i choć w przypadku systemów operacyjnych problem byłby znikomy, to ewentualne podczepianie takiego kolosa do strony WWW z pewnością odstraszyłoby niejednego czytelnika. W praktyce najczęściej tworzy się fonty, które pokrywają tylko pewne podzbiory punktów kodowych.
Jeśli dany font nie posiada symbolu dla konkretnego punktu kodowego, to niektóre aplikacje będą wyszukiwać brakującego znaku w innych fontach systemowych (oznacza to, że brakujący symbol może być w innym stylu niż otaczające go pozostałe symbole). W przypadku braku jakiegokolwiek dopasowania pojawi się jedynie mały prostokąt bez wypełnienia lub inny znak (np. U+FFFD Replacement Character). Z tego powodu należy podchodzić z dużym dystansem do wszelkich porównań prawidłowego wyświetlania znaków między różnymi programami.