Podstawy#
Składnia#
Język CSS jest językiem statycznym, ale w tym sensie, że nie istnieją w nim fundamentalne konstrukcje znane z klasycznych języków programowania (np. pętle). Dzięki temu składnia CSS jest bardzo prosta, bazuje jedynie na angielskich słowa kluczowych, które przede wszystkim wskazują na nazwy różnych właściwości stylów. Osoby bardziej wymagające mogą skorzystać z preprocesorów CSS.
Aktualna składnia CSS i jej przetwarzanie opisywane są w module "CSS Syntax Module Level 3". Znajdziemy tu wszystkie istotne informacje, takie jak diagramy szynowe czy algorytmy konwersji strumienia punktów kodowych Unicode (tekstu) do strumienia słów CSS, a następnie dalej do obiektów CSS (arkuszy stylów, reguł i deklaracji). Wszystko to jest bardzo szczegółowe i w zasadzie kierowane jest dla implementatorów. Postaram się zaprezentować jedynie najważniejsze aspekty składni CSS.
W pigułce#
Style CSS mogą pochodzić z różnych źródeł. Zazwyczaj stosuje się style zewnętrzne lub osadzone, dlatego też poniższa grafika w należyty sposób zobrazuje uproszczone stosowanie poleceń CSS:
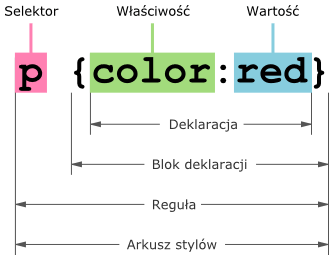
Rysunek. Składani CSS
Znaczenie poszczególnych części w powyższym arkuszu CSS wygląda następująco:
- Selektor # - wybiera konkretny element lub elementy HTML (z punktu widzenia DOM są to obiekty implementujące interfejs Element). W tym przykładzie będą to wszystkie akapity, ale możliwe jest stosowanie bardziej rozbudowanych selektorów (np.
body div.content > p + pre.example). - Blok deklaracji # - reprezentowany przez parę nawiasów klamrowych
{}. Zawiera jedną lub wiele deklaracji (separatorem między deklaracjami jest średnik ";"). - Deklaracja # - odpowiada za formatowanie elementów wskazywanych przez selektor (nadawanie im wyglądu). Każda deklaracja składa się z właściwości i wartości.
- Właściwość - słowo kluczowe wskazujące na jakąś cechę selektora (np. kolor, tło, cień itd.), którą chcemy ustawić. Właściwość tak naprawdę stanowi nazwę deklaracji.
- Wartość - liczba, tekst lub inny typ danych, które podaje się zaraz po właściwości (separatorem między nimi jest dwukropek "
:"). - Reguła - stanowi ją selektor oraz blok deklaracji. W tym przykładzie mamy do czynienia z regułą wykwalifikowaną # (qualified rule), ale istnieje także reguła małpy # (at-rule).
- Arkusz stylów - zbiór reguł. Z punktu widzenia DOM będzie on reprezentowany przez specjalny obiekt, z poziomu którego możliwe będzie dynamiczne manipulowanie regułami (ich odczyt lub zmiana) za pomocą JS.
Nazwy właściwości oraz nazwy reguł małp są zawsze identyfikatorami CSS (identifiers), dlatego muszą się zaczynać od litery lub myślnika, następnie mogą zawierać litery, liczby, myślniki lub podkreślniki. Można zastosować dowolne punkty kodowe Unicode, nawet te, które CSS wykorzystuje w swojej składni (za pomocą ucieczki).
Tak to wygląda w dużym uproszczeniu. Składnia jest elastyczna, najlepiej stosować białe znaki (głównie spacje) w taki sposób, by tworzony arkusz był jak najbardziej czytelny. Poniżej zamieszczam kilka prawidłowych sposobów zapisu różnych reguł:
/* Reguły wykwalifikowane */
p{color:red;text-align:center}
p { color: red; text-align: center; }
p {
color: red;
text-align: center;
}
/* Reguły małpy */
@import "style.css";
@page :left {
margin-left: 4cm;
margin-right: 3cm;
}
@media print {
body {font-size: 10pt;}
}Każdy z pewnością wypracuje swój własny styl kodowania. Nie ma się co przejmować wynikowym rozmiarem plików, liczy się przede wszystkim wygoda przy tworzeniu i późniejszym rozwijaniu kodu CSS. Przed umieszczeniem plików na serwerze produkcyjnym można je poddać minifikacji (ręcznej lub dynamicznej), można także włączyć kompresję plików CSS (jak również HTML i JS) po stronie serwera, i problem z nadmiernym wstawianiem białych znaków przestanie istnieć.
Ucieczka#
W składni CSS następujące znaki są zastrzeżone:
| ! | " | # | $ | % | & | ' | ( | ) | * | + | - | . | / | : | ; | < | = | > | ? | @ | [ | \ | ] | ^ | ` | { | | | } | ~ | . | ” |
Znaki te nie mogą występować w jawnej postać zarówno w identyfikatorach CSS (np. nazwach właściwości lub selektorach) jak i łańcuchach znakowych CSS (np. treści generowanej). W razie potrzeby należy skorzystać z sekwencji uniku. Znakiem uniku w przypadku CSS jest backslash "\". Wystarczy umieścić go przed problematycznym znakiem:
CSS
.base\+ext {color: blue;}
HTML
<div class="base+ext"></div>Wstawienie backslasha przed zastrzeżonym znakiem może nie działać w starszych przeglądarkach (np. IE6 czy IE7). Alternatywnie można wstawić punkt kodowy Unicode w postaci numerycznej:
<nocode class="hljs-comment">Selektor identyfikatora "#&B"</nocode>
#\26 B {color: blue;} <nocode class="hljs-comment">/* krótszy zapis ze spacją */</nocode>
#\000026B {color: blue;} <nocode class="hljs-comment">/* pełny zapis */</nocode>
Selektor klasy ".émotion"
.\E9 dition {color: blue;} <nocode class="hljs-comment">/* krótszy zapis ze spacją */</nocode>
.\0000E9dition {color: blue;} <nocode class="hljs-comment">/* pełny zapis</nocode>Czyli po znaku uniku podajemy od jednej do sześciu cyfr heksadecymalnych, które przypisano danemu znakowi w standardzie Unicode. Po szesnastkowym numerze można umieścić opcjonalny znak spacji. Ta opcjonalna spacja pozwala oddzielić sekwencję uniku od "prawdziwych" cyfr heksadecymalnych (zakresy A–F, a–f lub 0–9), które mogą po niej występować, co jest równoważne z wprowadzeniem kompletnego sześciocyfrowego numeru szesnastkowego bez dodatkowej spacji.
"Prawdziwy" znak spacji po sekwencji uniku musi zostać zdublowany.
Oczywiście znaki niezastrzeżone można wprowadzać bezpośrednio z klawiatury (nawet te bardzo egzotyczne). Jeśli nie będą cyframi heksadecymalnymi lub znakiem nowej linii (U+000A LINE FEED), to można przed nimi umieszczać znak uniku, ale nie będzie to miało żadnych realnych konsekwencji:
<nocode class="hljs-comment">/* Znak uniku nie wpływa na selektor, "r" nie jest traktowane jak cyfra heksadecymalna. */</nocode>
.heade\r {color: blue;}
<nocode class="hljs-comment">/* Znak uniku wpływa na selektor, "e" jest traktowane jak cyfra heksadecymalna. */</nocode>
.head\er {color: blue;}Kilka dodatkowych przykładów (większy zbiór):
.\3A \`\( {color: blue;} /* dopasuje element z atrybutem class=":`(" */
.\31 a2b3c {color: blue;} /* dopasuje element z atrybutem class="1a2b3c" */
#\#fake-id {color: blue;} /* dopasuje element z atrybutem id="#fake-id" */
#\--- {color: blue;} /* dopasuje element z atrybutem id="---" */
#-a-b-c- {color: blue;} /* dopasuje element z atrybutem id="-a-b-c-" */
#© {color: blue;} /* dopasuje element z atrybutem id="©" */Zależności z innymi językami#
Polecenia CSS można osadzać bezpośrednio w innych językach, np. za pomocą elementu <style> (HTML + CSS) lub <script> (HTML + JS + CSS). Każdy z tych języków ma własne wytyczne odnośnie stosowania znaków zastrzeżonych, których należy bezwzględnie przestrzegać. Mogą zatem występować sytuacje, gdzie koniecznym będzie użycie zwielokrotnionych sekwencji uniku właściwych dla każdego języka.
Z praktycznego punktu widzenia najciekawsze są przypadki połączenia CSS i JS, dla których przewidziano identyczny znak uniku ("\"). Zasada postępowania jest prosta; najpierw tworzymy kod zgodny z wytycznymi CSS, po czym dostosowujemy go do wymagań JS.
Prosty przykład:
<div id="foo\bar">Pierwszy DIV.</div>
<div id="foo\\bar">Drugi DIV.</div>
<div id="foo:bar">Trzeci DIV.</div>
<p style="color: blue;">Rezultat:</p>
<script>
// Tylko JS
document.write("#foo\bar"); // "#fooar" (między "o" i "a" jest niedrukowany znak)
document.write("<br>");
document.write("#foo\\bar"); // "#foo\bar"
document.write("<br>");
document.write("#foo\\\\bar"); // "#foo\\bar"
document.write("<br>");
document.write("#foo:bar"); // "#foo:bar"
document.write("<br><br>");
// Tylko JS
document.write(document.getElementById("foo\bar")); // null
document.write("<br>");
document.write(document.getElementById("foo\\bar").textContent); // "Pierwszy DIV."
document.write("<br>");
document.write(document.getElementById("foo\\\\bar").textContent); // "Drugi DIV."
document.write("<br>");
document.write(document.getElementById("foo:bar").textContent); // "Trzeci DIV."
document.write("<br><br>");
// JS + selektory CSS
document.write(document.querySelector("#foo\\bar")); // null
document.write("<br>");
document.write(document.querySelector("#foo\\\\bar").textContent); // "Pierwszy DIV."
document.write("<br>");
document.write(document.querySelector("#foo\\\\\\\\bar").textContent); // "Drugi DIV."
document.write("<br>");
document.write(document.querySelector("#foo\\:bar").textContent); // "Trzeci DIV."
document.write("<br><br>");
document.write(document.querySelector("#foo\bar")); // błąd SyntaxError (dotyczy poprawności selektora)
document.write(document.querySelector("#foo:bar")); // błąd SyntaxError (dotyczy poprawności selektora)
</script>Widać wyraźnie, że największe zaciemnienie czytelności kodu generuje jawny znak backslasha. Języki CSS i JS wymagają jego odpowiedniej konwersji; w razie konieczności osobno dla CSS i JS (jak w metodach API selektorów), kiedy w HTML-u backslash nie ma specjalnego znaczenia i może być stosowany jawnie.
W ramach uzupełnienia warto przeanalizować artykuł "CSS character escape sequences". Autor udostępnił także proste narzędzie online, za pomocą którego przeprowadzimy konwersję zastrzeżonych znaków w obrębie CSS i JS.
Komentarze#
W CSS występują jedynie komentarze blokowe, które rozpoczynają się sekwencją znaków "/*" i kończą sekwencją znaków "*/". Między nimi mogą występować dowolne znaki, ale z wykluczeniem sekwencji znaków "*/", chociaż stosowanie znaków "*" i "/" rozdzielonych innymi znakami (nawet spacją) jest dozwolone. Spacje między ramami początkowymi/końcowymi komentarza a jego zawartością nie są obowiązkowe. Mamy więc do czynienia z rozwiązaniem podobnym do języków bazujących na składni C/C++.
Prosty przykład:
/*Komentarz blokowy CSS umieszczony w jednej linii*/
p {color:red;} /* Komentarz blokowy CSS umieszczony w jednej linii */
/*Komentarz blokowy CSS
może być długi na kilka wierszy
bez jakichkolwiek problemów. */Niestety, w CSS nie ma klasycznych komentarzy liniowych, dlatego nawet najkrótszy komentarz wymaga wprowadzenia zamykającej sekwencji "*/". Jeśli komentarz umieszczamy w tym samym wierszu co kod, trzeba bardzo uważać na to, w jaki sposób się go umieszcza:
h1 {color:red;} /* Ten komentarz jest długi na kilka wierszy, */
h2 {color:gren;} /* ale skoro położony jest obok */
div {color:blue;} /* właściwych stylów, każdy wiersz */
p {color:white;} /* musi być ujęty w ramy komentarza. */
h1 {color:red;} /* Ten komentarz jest długi na kilka wierszy,
h2 {color:gren;} ale ponieważ nie jest ograniczony
div {color:blue;} ramami komentarza, ostatnie trzy
p {color:white;} style są częścią komentarza. */Powyższy przykład jest poprawny składniowo, nie generuje żadnego błędu CSS. Chociaż wariant drugi z pewnością nie jest tym, co chcielibyśmy uzyskać (niektóre reguły - jako część komentarza - zostaną zignorowane przez silnik przeglądarki).
Komentarzy CSS nie wolno zagnieżdżać, poniższy przykład jest nieprawidłowy:
/* To jest komentarz blokowy CSS, w którym znajduje się drugi komentarz, co jest BŁĘDEM! /* Drugi komentarz */ i z powrotem pierwszy komentarz. */
Obsługa błędów#
Parser CSS wyposażono w mechanizm obsługi błędów # (error handling). Kiedy w kodzie CSS wystąpi błąd, to parser próbuje odzyskać sprawność opuszczając tylko minimalną ilość błędnej treści, przed powrotem do prawidłowego parsowania. Jest tak dlatego, że błędy nie zawszę są pomyłkami - dla starszych parserów nowa składnia wygląda jak błąd, i jest to przydatne, kiedy trzeba dodać nową składnie do języka, nie martwiąc się o arkusze stylów z nowymi poleceniami, które stałyby się kompletnie zepsute w starszych programach.
Cecha ta może być przydatna w codziennej pracy. Zamiast umieszczać niechcianą regułę w komentarzu, można po prostu dostawić/usunąć jeden zbędny znak, przez co reguła stanie się błędna i zostanie pominięta przez parser. W przypadku kodu roboczego jest to wygodne rozwiązanie, aczkolwiek należy pamiętać, że w kodzie produkcyjnym wszystkie elementy niezgodne ze składnią CSS należy z powrotem poprawić.