Podstawy#
Obsługa błędów#
Błędy # (errors) są naturalną konsekwencją robienia czegoś pożytecznego (niestety bezproduktywnego też). Nie da się całkowicie wyeliminować błędów, dlatego potrzebny jest mechanizm ich wykrywania. Dzięki niemu program będzie mógł ustalić, że coś poszło nie tak, i w elegancki sposób odzyskać sprawność.
W ujęciu programistycznym błędy to obiekty, które będą implementowały określone definicje Web IDL. Specyfikacja DOM4 przewiduje dwie takie bazowe definicje: wyjątek DOMException (dla konkretnych błędów określonych przez standard) oraz interfejs DOMError (dla rozszerzeń w implementacjach). Szczegóły każdego z nich opiszę osobno w dalszej części kursu.
W przyszłości cała sekcja opisująca błędy w specyfikacji DOM4 zostanie przeniesiona do specyfikacji Web IDL. Planuje się także całkowite usunięcie interfejsu DOMError i zastąpienie go interfejsem DOMException.
Mechanizm obsługi błędów będzie zależny od danego środowiska. W przypadku przeglądarek internetowych mamy do czynienia z ECMAScriptem, dlatego najlepiej omówić kilka jego podstaw.
Typy błędów JavaScript#
JavaScript jest językiem interpretowanym, to też informacje zwrotne ograniczają się głównie do ostrzeżeń o problemach ze składnią naszych skryptów. Gdy się z tym uporamy, nieliczne komunikaty diagnostyczne czasu wykonania przekładają się w zasadzie na "Próbowałem to zrobić, ale coś, czego potrzebowałem, nie istnieje".
JS w założeniach ma być językiem szybkim, łatwo interpretowanym i interaktywnym, często wymagającym jedynie kilku instrukcji. Żaden kompilator nie sprawdza rygorystycznie skryptów zanim pozwoli ich użyć. Na skutek tego bardzo łatwo nabrać przyzwyczajeń do niedbałego programowania. Wiele problemów, takich jak błąd pominięcia testu obiektu przed użyciem, brak obsługi wyjątków lub zapominanie o zamykaniu nawiasów z uwagi na niewłaściwe wcięcia, bierze się z braku dobrych nawyków programistycznych.
Prawdę mówiąc obecne przeglądarki internetowe wyposażone są w maszyny kompilacyjne typu JIT, które w czasie rzeczywistym tworzą kod maszynowy na podstawie kodu JavaScript, wprowadzając jednocześnie mikrooptymalizacje, a dopiero potem go wykonują. Mimo takiego usprawnienia ogólna natura języka jest niezmienna, czyli bardzo łatwo wprowadzić do środowiska produkcyjnego niedziałający kod z drobnym błędem składniowym. Brak kompilatorów można zniwelować poprzez stosowanie dedykowanych narzędzi sprawdzających jakość i poprawność kodu JavaScript, np. za pomocą narzędzi JSLint/JSHint.
Błędy w JavaScripcie można podzielić na trzy główne kategorie:
Błędy składni
Błędy składni (zwane inaczej błędami czasu ładowania) występują jako pierwsze. Instrukcje JS są analizowane po załadowaniu przez interpreter programu gospodarza (gospodarzem może być np. przeglądarka WWW). Podczas ładowania skryptu przeprowadzana jest kontrola składni. Błędy składni są powodowane przez poważne pomyłki w składni skryptu. Skrypty, które zawierają błędy składni generują komunikaty o błędach podczas ładowania skryptu i nie zostają uruchomione. Tego typu błędy najłatwiej chyba wychwycić i naprawić, ponieważ pojawiają się przy każdym ładowaniu skryptu, w przeciwieństwie do błędów czasu wykonania i błędów logicznych, które generowane są tylko po wywołaniu funkcji lub spełnieniu określonych warunków. Brakujące cudzysłowy, nawiasy okrągłe i klamrowe należą do najczęstszych przyczyn tych błędów.
Prosty przykład:
<script>
document.write("aaaa"; // brak zamykającego ')'
</script>Błędy czasu wykonania
Błędy czasu wykonania są wychwytywane po załadowaniu skryptu, czyli po zakończeniu kontroli składni. Wówczas wykonywane są wszystkie polecenia globalne (nie zawarte w funkcjach), takie jak deklaracje zmiennych. Na tym etapie może wystąpić błąd czasu wykonania, spowodowany przez cokolwiek, począwszy od niezdefiniowanej zmiennej, aż po przekroczenie zakresu przez indeks tablicy. Funkcje są rozpoznawane przy ładowaniu skryptu, lecz nie będą wykonane, dopóki nie zostaną wywołane przez inne funkcje lub zdarzenia. Podczas wykonywania tych funkcji mogą zostać wygenerowane błędy wykonania lub błędy logiczne. Gdy w skrypcie pojawi się błąd czasu wykonania, zostaje wyświetlony komunikat o błędzie i wykonanie skryptu ustaje. Do powszechnie spotykanych przyczyn występowania błędów czasu wykonania należą odwołania do niezdefiniowanych zmiennych, niewłaściwe zastosowanie obiektów, wstawianie niezgodnych typów i tworzenie pętli nieskończonych.
Prosty przykład:
<script>
document.write(test); // odwołanie do niezadeklarowanej zmiennej 'test'
</script>Błędy logiczne
Błędy logiczne są wolne od błędów składni i czasu wykonania, lecz prowadzą do niepoprawnych wyników. Błędy logiczne nie powodują zatrzymania wykonywania skryptu, chyba że niezamierzone wyniki błędu logicznego w połączeniu z innym poleceniem lub skryptem powodują błąd czasu wykonania. Usuwanie błędów logicznych jest często najtrudniejsze i może od programisty wymagać prześledzenia wartości wszystkich zmiennych w każdym kroku skryptu. Do częstych przyczyn błędów logicznych należą: użycie = zamiast == i niezgodne typy danych.
Prosty przykład:
<script>
var test = "warunek";
if (test = "warunek"){ // zawsze prawdziwy warunek, '=' zamiast '=='
// kod do wykonania
}
</script>Wyjątki JavaScript#
Do obsługi błędów w JavaScripcie służą instrukcje try...catch, throw oraz finally. Zazwyczaj pracują one w połączeniu dwóch pierwszych, aczkolwiek możliwa jest też kombinacja wszystkich na raz.
Kiedy w kodzie skryptu pojawia się błąd, to automatycznie zrzucany (throw) jest obiekt błędu. Z perspektywy JS całe zajście nazywane jest mechanizmem obsługi wyjątków #. Wyjątki (exceptions) są nadzwyczajnym (choć nie zupełnie niespodziewanym), niepożądanym zdarzeniem, które zakłóca normalne wykonywanie programu. Kiedy takie zdarzenie nastąpi, program powinien zgłosić wyjątek.
Podstawowym błędem # jest typ Error, po którym dziedziczą bardziej konkretyzujące typy błędów: EvalError (błąd wykonania), RangeError (błąd zakresu), ReferenceError (błąd referencji), SyntaxError (błąd składniowy), TypeError (błąd typu) i URIError (błąd adresu URI).
Wszystkie wymienione rodzaje błędów mają swoje odpowiedniki w postaci funkcji (konstruktorów), dlatego umożliwiają samodzielne tworzenie błędów dowolnego typu.
Obiekty błędów posiadają także następujące właściwości:
name- nazwa konstruktora tworzącego obiekt błędu.message- tekst przekazany do konstruktora w momencie tworzenia obiektu.
Obiekty błędów mają również dodatkowe właściwości informujące o pliku i numerze wiersza, w którym błąd wystąpił, ale te informacje to rozszerzenia wprowadzone niejednolicie przez różne przeglądarki, więc nie można na nich polegać.
W większości przypadków automatyczne zrzucanie błędów następuje do przeglądarkowej konsoli, z której można odczytać szczegółowe informacje o błędzie. Wygenerujmy prosty błąd:
<script>
test(); // wywołanie nieistniejącej funkcji 'test'
</script>W konsoli błędów Firefoksa (skrót Ctrl+Shift+J) komunikat wygląda następująco:
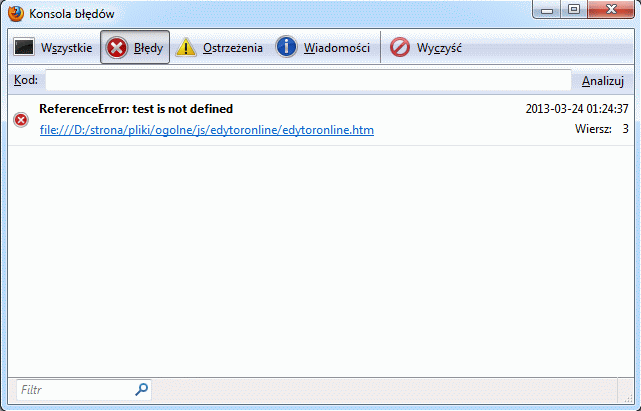
Rysunek. Konsola błędów w przeglądarce Firefox
Sposób wyświetlania informacji o błędach jest różny w różnych przeglądarkach. W Internet Eksplorerze komunikaty o błędach dodatkowo wyprowadzane są w lewym dolnym rogu Paska stanu. Po dwukrotnym kliknięciu na komunikacie otrzymujemy nowe okno ze szczegółowymi informacjami.
try...catch#
W zależności od konfiguracji przeglądarki można nawet nie zauważyć, że wystąpił błąd. Większość użytkowników nie programuje w JavaScripcie, zazwyczaj w ogóle nie zajmuje się programowaniem, dlatego komunikaty o błędach niewiele dla nich znaczą. Uwolnienie czytelników od konieczności oglądania komunikatów o błędach zależy od nas samych. Błąd z pierwszego przykładu został wyświetlony, ponieważ kod nie próbował go przechwycić i nie był przygotowany na jego obsługę.
Na szczęście łapanie błędów jest banalnie proste. Potrzeba do tego wyrażenia try...catch:
try{
// kod do przetestowania
}
catch(e){
// kod obsługi błędu
// obiekt błędu znajduje się w zmiennej 'e'
}Instrukcja try (próbuj) ma pojedynczy blok catch (przechwyć), który przechwytuje wszystkie obiekty błędów. Jeśli wyjątek zostanie zgłoszony wewnątrz bloku try (automatycznie lub przez nas samych), to sterowanie przechodzi do bloku catch.
Obsługa błędu z pierwszego przykładu może wyglądać następująco:
<script>
try{
test(); // wywołanie nieistniejącej funkcji 'test'
}
catch(e){
document.write(e); // ReferenceError: test is not defined
document.write("<br><br>");
document.write(e.name); // ReferenceError
document.write("<br>");
document.write(e.message); // test is not defined
document.write("<br>");
document.write(e.fileName);
document.write("<br>");
document.write(e.lineNumber); // 4
document.write("<br><br>");
document.write(e.constructor); // function ReferenceError() { [native code] }
document.write("<br>");
document.write(e.__proto__); // ReferenceError
document.write("<br>");
document.write(e.__proto__.__proto__); // Error
document.write("<br>");
document.write(e.__proto__.__proto__.__proto__); // [object Object]
}
</script>Zasadniczo nowoczesne przeglądarki stosują identyczne konstruktory do tworzenia błędów określonego rodzaju, ale zwracane komunikaty (wiadomości) będą różne. Ogólnie rzecz biorąc opieranie obsługi błędów na podstawie domyślnych komunikatów zwracanych przez programy nie jest dobrym pomysłem, nigdy nie ma gwarancji utworzenia tego samego obiektu błędu w każdej aplikacji.
throw#
O wiele przydatniejsza jest dedykowana instrukcja throw, która służy do samodzielnego zrzucania błędu. Polecenie działa prawidłowo nie tylko dla obiektów utworzonych za pomocą wbudowanych konstruktorów błędów, ale pozwala także na zgłoszenie dowolnego obiektu. Taki obiekt może zawierać właściwości name, message lub dowolne inne, które powinny trafić do bloku catch. Okazuje się, że można to wykorzystać w bardzo kreatywny sposób i nierzadko przywrócić po błędzie aplikację do stanu początkowego.
Prosty przykład:
<script>
try{
var a = 10;
var b = 0;
if (b == 0){
throw{
name: "Błąd wartości",
message: "Nie dziel cholero przez zero!",
repair: function(){
document.write("<br><br>Naprawiłem kod!");
}
}
}
}
catch(e){
document.write(e); // [object Object]
document.write("<br><br>");
document.write(e.name); // Błąd wartości
document.write("<br>");
document.write(e.message); // Nie dziel cholero przez zero!
document.write("<br><br>");
document.write(e.constructor); // function Object() { [native code] }}
e.repair(); // Naprawiłem kod!
}
</script>Błędy w DOM#
Jak już wspomniałem na samym początku, DOM ma swoje własne obiekty błędów, które wykorzystują mechanizm obsługi wyjątków JavaScriptu. Ich dokładny opis zaprezentowany zostanie w dalszej części kursu. Teraz jedynie wygenerujmy prosty błąd związany z jakąś instrukcją DOM:
<script>
try{
document.appendChild(document);
}
catch(e){
document.write(e); // Opis zależny od przeglądarki
document.write("<br><br>");
document.write(e.code); // 3
document.write("<br>");
document.write(e.name); // HierarchyRequestError
document.write("<br>");
document.write(e.message); // Opis zależny od przeglądarki
document.write("<br><br>");
document.write(e.constructor); // [object DOMException]
}
</script>Nie wszystkie możliwe do popełnienia błędy zostaną określone w algorytmach DOM. Część z nich może pochodzić bezpośrednio z ECMAScript, Web IDL lub innych specyfikacji. Załóżmy, że mamy do czynienia z następującą definicją Web IDL z interfejsu ParentNode:
Element? getElementById(DOMString elementId);Widać wyraźnie, że przy wywołaniu metody ParentNode.getElementById() należy jej przekazać jeden argument w postaci łańcucha znakowego. Przekazanie argumentu o innym typie lub pominięcie go całkowicie zwróci nam błąd. Wynika to wprost z definicji Web IDL, dlatego też nie wymaga zdefiniowania dodatkowych kroków w algorytmach DOM.
Innym ciekawym przykładem mogą być następujące definicje Web IDL z interfejsu DOMTokenList:
void add(DOMString... tokens);
void remove(DOMString... tokens);Tym razem obydwie metody przyjmują zmienną liczbę argumentów, które dodatkowo można całkowicie pominąć, czyli wywołanie DOMTokenList.add() lub DOMTokenList.remove() - bez przekazania czegokolwiek - będzie jak najbardziej poprawne i nie zwróci żadnego błędu. Zachowanie to nie musi być opisywane bezpośrednio w algorytmach DOM i może być dobrym testem zgodności ze standardami przez różne implementacje.