Podstawy#
Zarządzanie pamięcią#
Pomimo niewielkich cen kości RAM, ich ilość nigdy nie będzie wystarczająca. Idealnym rozwiązaniem pod względem wydajnościowym byłoby posiadanie jedynie pamięci RAM. Niestety, RAM jest pamięcią ulotną i wciąż drogą, w porównaniu do klasycznych magazynów pamięci (np. dysków twardych). Biorąc to pod uwagę opracowano mechanizmy, które pozwalają współpracować między różnymi typami pamięci, jeśli tylko zajdzie taka konieczność.
W pewnych okolicznościach oszczędne gospodarowanie RAM-em może być istotne przy tworzeniu aplikacji webowych. Zanim przejdę do właściwego zagadnienia warto najpierw opisać podstawy zarządzania pamięcią w systemach operacyjnych.
System operacyjny#
W systemie operacyjnym występują dwa rodzaje pamięci fizycznej:
- pamięć operacyjna
- pamięć masowa
Współczesne systemy operacyjne obydwoma rodzajami pamięci zarządzają za pomocą mechanizmu pamięci wirtualnej. Poniższa grafika będzie punktem wyjścia dla dalszego opisu.
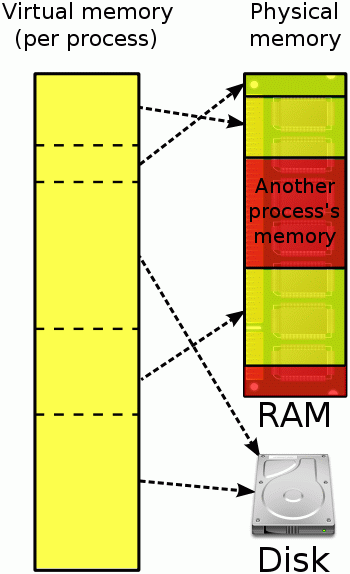
Rysunek. Pamięć wirtualna procesu i rozmieszczenie jej w pamięci fizycznej
Pamięć operacyjna to zazwyczaj niezwykle szybkie moduły RAM zamontowane w komputerze. W pamięci RAM przechowywane są aktualnie wykonywane programy i dane dla tych programów oraz wyniki ich pracy. Z RAM-u mogą korzystać niektóre komponenty (procesory specjalizowane) komputera, przykładowo karty graficzne czy muzyczne.
RAM to bardzo szybki podzespół maszyny, niestety wymaga ciągłego zasilania. W temperaturze pokojowej zawartość większości pamięci RAM jest tracona w czasie mniejszym niż sekunda po zaniku napięcia zasilania, niektóre typy wymagają także odświeżania, dlatego wyniki pracy programów, wymagające trwałego przechowania, muszą być zapisane na innym nośniku danych. Z drugiej strony, nie ma możliwości montowania dowolnej ilości RAM-u, wszystko zależy od posiadanej płyty głównej. Dlatego wizja stosowania wyłącznie pamięci RAM jest kusząca, ale niezwykle trudna i kosztowna we wdrożeniu.
Biorąc pod uwagę wady i zalety pamięci RAM postanowiono wziąć z niej to co najlepsze, a kłopotliwe kwestie (podtrzymanie stanu) rozwiązać w inny sposób. Wynikiem tego stało się wprowadzenie mechanizmu pamięci wirtualnej. Mechanizm ten zapewnia procesowi wrażenie pracy w jednym dużym i ciągłym obszarze pamięci operacyjnej podczas gdy fizycznie może być ona pofragmentowana, nieciągła i częściowo przechowywana na urządzeniach pamięci masowej (zazwyczaj na dyskach HDD lub SSD). Urządzenia pamięci masowej są z reguły wolniejsze, ale swą powolność nadrabiają znacznie większą dostępną przestrzenią pamięci.
Często popełnianym błędem jest utożsamianie pamięci wirtualnej z wykorzystaniem pamięci masowej do rozszerzenia dostępnej pamięci operacyjnej. Rozszerzenie pamięci na dyski twarde w rzeczywistości jest tylko naturalną konsekwencją zastosowania techniki pamięci wirtualnej, lecz może być osiągnięte także na inne sposoby, np. nakładki lub całkowite przenoszenie pamięci procesów na dysk, gdy znajdują się w stanie uśpienia.
W pierwszych komputerach z lat 40. i 50., podobnie jak współcześnie, pamięć była zorganizowana w sposób dwupoziomowy, analogicznie do obecnego podziału na RAM i pamięć masową. Jednak z powodu braku mechanizmu pamięci wirtualnej, każdy program musiał we własnym zakresie zarządzać przenoszeniem danych z jednego poziomu do drugiego, co komplikowało programowanie. Głównym powodem wprowadzenia pamięci wirtualnej była zatem chęć maksymalnego uproszczenia i automatyzacji procesów związanych z zarządzaniem pamięcią, a nie jej rozszerzenie.
Jeśli wymagania pamięciowe procesu wzrosną w znacznym stopniu, system operacyjny może być zmuszony do zwolnienia części pamięci RAM, która akurat w danej chwili jest nieprzydatna, a która jest buforowana przez inne programy. Jeśli pamięci operacyjnej wciąż będzie za mało rozpocznie się proces tzw. stronicowania, czyli bardzo powolnego etapu, w którym system operacyjny dzieli całą wirtualną pamięć potrzebną dla danego procesu na pojedyncze strony, tj. najmniejsze jednostki pamięci, które są odwzorowywane do pamięci operacyjnej lub pamięci masowej. W razie potrzeby strony te są przenoszone z pamięci operacyjnej do pamięci masowej (czyli na ogół z pamięci RAM na dysk twardy) lub odwrotnie.
W systemach z rodziny Windows rozszerzona pamięć operacyjna domyślnie przechowywana jest na dysku twardym w postaci pliku wymiany (nazwa pagefile.sys). System operacyjny może obsługiwać po jednym takim pliku na każdą partycję, przy czym można dokładnie określić jego rozmiar (ustawić sztywną lub dynamiczną wartość). Zbyt częste zapisy i odczyty z/do pliku wymiany zmniejszają wydajność komputera, przyczyniają się do nadmiernego zużycia dysku twardego i zazwyczaj świadczą o zbyt małej ilości pamięci RAM.
Stronicowanie to wolny proces, który powoduje ogólne, wszechobecne spowolnienie widoczne w całym systemie operacyjnym i we wszystkich uruchomionych programach. Za ten mechanizm odpowiedzialny jest właściwie tylko system operacyjny i niewiele możemy w tym kierunku zrobić. Jedynym rozwiązaniem może być dokupienie pamięci RAM lub ewentualnie zamontowanie dysku SSD zamiast HDD, przez co szybkość odczytu/zapisu ulegnie znacznej poprawie, oczywiście kosztem żywotności nośnika SSD.
Przykład z życia#
Kiedy jeszcze byłem w posiadaniu magicznego sprzętu dysponującego jedynie kością 512 MB RAM, problem stronicowania był chlebem powszednim. Uruchamiając przeglądarkę z wieloma kartami, w każdej jakiś skrypt lub makro, doprowadzałem do sytuacji, że po kilkudziesięciu minutach (ok. 30-60) cały RAM był zapchany. System zaczął włączać do podsystemu pamięci powolny dysk twardy, a był to jeszcze twardziel na IDE, bez NCQ i innych wynalazków. W efekcie otrzymywałem wolno działający system z powolną przeglądarką internetową. Można było przecierpieć tę niedogodności, wystarczyło odpalić odpowiednią ilość kart i od czasu do czasu uruchomić przeglądarkę (a najlepiej cały system) od nowa. Z doświadczenia wiem, że najlepiej na tym polu sprawdzał się leciwy Internet Explorer 6. Może nie miał najwydajniejszego silnika renderującego, zoptymalizowanej maszyny JS, dobrego odśmiecania, ale jego niewielkie zapotrzebowanie na RAM w dużym stopniu rekompensowało braki. Inne przeglądarki były zbyt wymagające dla tak przestarzałego komputera.
Problem został całkowicie wyeliminowany po przesiadce na nową maszynę. Większa ilość pamięci RAM (8 GB) i nowszy dysk twardy w zupełności zaspokaja wszelkie moje potrzeby i wymagania stawiane przez najnowsze programy. Chociaż należy być świadomym, że w przypadku bardziej profesjonalnych zastosowań taka ilość RAM-u wciąż pozostanie kroplą w morzu potrzeb.
Przeglądarki internetowe#
Czas przyjrzeć się mechanizmom wprowadzanym przez same przeglądarki, ponieważ w większości przypadków, to właśnie w tym środowisku będziemy tworzyć i uruchamiać nasz kod. Oczywiście przeglądarki podlegają rozwiązaniom zarządzania pamięcią samego systemu operacyjnego. Jeśli zapotrzebowanie pamięciowe procesu przeglądarki przekroczy możliwości pamięci RAM, do pracy włączony zostanie dysk twardy, ze wszystkimi jego wadami.
Co, jeśli mamy dużo pamięci RAM i możemy sobie pozwolić na rozrzutność ze strony przeglądarki? W zasadzie nie jest to problemem, przeglądarka powinna zająć tyle wolnej pamięci RAM ile potrzebuje. Niestety, takie zachowanie jest wytykane przez użytkowników, którzy oskarżają programy o zbyt duże zapotrzebowanie na RAM. W związku z tym programiści starają się jak najbardziej optymalizować swój kod pod względem konsumpcji RAM, ewentualnie udostępniają odpowiednie opcje konfiguracyjne umożliwiające zwiększenie zapotrzebowania. Można to osiągnąć poprzez lokowanie w RAM-ie tylko niezbędnych składników w czasie uruchamiania programu. Dopiero później doładowywane zostają pozostałe komponenty, kiedy faktycznie będą potrzebne.
Osobnego omówienia wymaga dynamiczne tworzenie stron i aplikacji webowych. W tym przypadku mamy do czynienia z programowaniem, czyli kwestie związane z zarządzaniem pamięcią będą nas dotyczyć bezpośrednio.
Cykl zajętości pamięci#
Niezależnie od języka programowania, cykl zajętości pamięci jest przeważnie taki sam:
- Alokuj (przydziel) pamięć, którą potrzebujesz.
- Użyj ją (zapis, odczyt).
- Zwolnij alokowaną pamięć, kiedy nie jest już potrzebna.
Pierwsza i druga część jest podobna we wszystkich językach. Trzecia część występuje doraźnie w językach niskiego poziomu, ale zazwyczaj jest przezroczysta w językach wysokiego poziomu, przykładowo w JavaScript.
Alokowanie pamięci w JavaScript#
Najprostszy przykład przydzielania pamięci dla pewnych wartości to literalne wypisanie tych wartości:
<script>
3; // Alokuje pamięć dla liczby
"test"; // Alokuje pamięć dla łańcucha znakowego
// Alokuje pamięć dla obiektu i zawartych w nim wartości
{
"num1" : 1,
"num2" : 2,
"num3" : 3
};
[0, 1, 2, 3]; // Alokuje pamięć dla tablicy i zawartych w niej wartości
</script>Przykład jest specyficzny, ponieważ do żadnej z tych alokowanych wartości nie utworzyliśmy odwołania. W takiej postaci wszystkie wypisane wartości nie są osiągalne w dalszym miejscu kodu. Wartości zostaną umieszczone w pamięci, ale przy pierwszej okazji oczyszczania pamięci nastąpi ich samoczynne usunięcie.
Bardziej realistycznym przykładem będzie alokacja pamięci przy użyciu operatora przypisania:
<script>
var n = 123; // alokuje pamięć dla liczby
var s = "azerty"; // alokuje pamięć dla łańcucha znakowego
// Alokuje pamięć dla obiektu i zawartych w nim wartości
var o = {
a: 1,
b: null
};
var a = [1, null, "abra"]; // alokuje pamięć dla tablicy i zawartych w niej wartości (podobnie jak dla obiektu)
// Alokuje pamięć dla funkcji (wywoływanego obiektu)
function f(a){
return a + 2;
}
// Alokuje pamięć dla wyrażenia funkcyjnego (wywoływanego obiektu)
someElement.addEventListener('click', function(){
someElement.style.backgroundColor = 'blue';
}, false);
</script>Można też rezerwować pamięć poprzez wywoływanie niektórych funkcji ustawiających lub zwracających wartości:
<script>
var d = new Date(); // alokuje pamięć dla obiektu daty
var e = document.createElement('div'); // alokuje pamięć dla obiektu DOM
var s = "azerty";
// 's2' jest nowym łańcuchem znakowym.
// Ponieważ łańcuchy znakowe mają niezmienną wartość, JS może zdecydować,
// by nie alokować pamięci dla 's2', tylko przechować zakres [0, 3] wprost od 's'.
var s2 = s.substr(0, 3);
var a = ["ouais ouais", "nan nan"];
var a2 = ["generation", "nan nan"];
var a3 = a.concat(a2); // nowa tablica z 4 elementami, będąca połączeniem elementów z 'a' i 'a2'
</script>Tym razem do każdej alokowanej wartości przypisano konkretną zmienną.
Zmienna określa symboliczną nazwę (identyfikator) dla wartości i pozwala odwoływać się do tej wartości przez nazwę. JavaScript jest językiem dynamicznie typowanym, co oznacza, że przy tworzeniu zmiennej nie deklarujemy typu wartości, jaki zmienna może przechowywać. W każdej chwili możemy zamienić wartości jednego typu na wartość innego typu. Dodatkowo JS jest językiem o słabych typach, co oznacza, że konwersje danych na różne typy mogą nastąpić automatycznie jeśli kontekst tego wymaga:
<script>
var test = 6; // zmienna przechowuje wartość typu number
test = "Cześć"; // zmienna przechowuje wartość typu string
test = [0, 1, 2]; // zmienna przechowuje wartość typu object
var num = 1;
document.write(num == "1"); // true - automatyczna konwersja
</script>W zależności od sposobu deklaracji zmienne można podzielić na dwa rodzaje:
- zmienne jawne
- zmienne domniemane
Z technicznego punktu widzenia oba rodzaje zmiennych są właściwościami obiektu, którym może być obiekt globalny lub kontekst wykonania funkcji, ale będą między nimi istotne różnice.
Zmienne jawne # tworzy się za pomocą słowa kluczowego var, po którym umieszcza się poprawny identyfikator. Zmienna taka staje się widoczna jedynie w danym kontekście, w którym została zadeklarowana. Również przy tworzeniu ustawiona zostaje odpowiednia flaga, która uniemożliwia usuwanie tego rodzaju zmiennej za pomocą operatora delete.
Zmienne domniemane tworzone są automatycznie w przypadku pominięcia słowa kluczowego var. Stają się właściwościami obiektu globalnego, niezależnie od kontekstu w którym się pojawiają. Ponadto możliwe jest ich usuwanie przy użyciu delete. Zazwyczaj zmienne domniemane są wynikiem popełnionego błędu w kodzie, gdyż zaśmiecanie przestrzeni globalnej niepotrzebnymi wartościami jest złą praktyką - przydają się w naprawdę skrajnych przypadkach. W nowym ECMAScript 5 (tryb Strict) tworzenie zmiennych domniemanych zwraca błąd.
Prosty przykład:
<script>
// Zmienna 'newObject1' jest doraźną właściwością obiektu globalnego
var newObject1 = {
item1: 1
}
function test(){
// Zmienna 'newObject2' jest domniemaną właściwością obiektu globalnego
newObject2 = {
item1: 1
}
}
test();
document.write(this.newObject1.item1); // 1
document.write("<br>");
document.write(delete newObject1); // false - brak reakcji, nie można usunąć 'newObject1'
document.write("<br><br>");
document.write(delete newObject1.item1); // true - zawartość pod właściwością 'item1' została usunięta
document.write("<br>");
document.write(newObject1.item1); // undefined
document.write("<br><br>");
document.write(delete this.newObject2); // true - 'newObject2' zostaje usunięty
document.write("<br>");
document.write(this.newObject2); // undefined
</script>Używanie wartości w JavaScript#
Ponowne używanie wartości oznacza głównie odczytywanie i zapisywanie w alokowanej pamięci. Można to robić poprzez odczyt i zapis wartości w zmiennej (właściwości obiektu), a nawet przekazując argument do funkcji.
W tym miejscu zaczyna robić się ciekawie. W JS mamy do czynienia z dwoma różnymi typami danych:
- typy proste (primitive) - przekazywane przez wartość
- obiekty (object) - przekazywane przez referencję
Do typów prostych zalicza się pięć rodzajów: number, string, boolean, undefined i null. Charakteryzują się one tym, że reprezentują stałą wartość, nie da się rozszerzyć istniejącego typu prostego. Żeby zmienić konkretną wartość danego typu na inną wartość (nawet tego samego typu) należy ją utworzyć od nowa:
<script>
var name = "Karol"; // zmienna przechowuje wartość 'Karol' typu string
name.wiek = 20; // próba rozszerzenia typu prostego
document.write(name); // Karol
document.write("<br>");
document.write(name.wiek); // undefined
document.write("<br>");
document.write(typeof name); // string
name = "Tomek"; // zmienna przechowuje nową wartość 'Tomek' typu string
</script>Typy proste są przekazywane przez wartość. Manipulacja typami prostymi zawsze odbywa się na aktualnych wartościach trzymanych w zmiennych. Przypisanie zmiennej (przechowującej typ prosty) do nowej zmiennej oznacza de facto skopiowanie wartości z pierwszej zmiennej i umieszczenie w nowej zmiennej.
<script>
var num1 = 5; // zmienna 'num1' przechowuje wartość '5' typu number
var num2 = num1; // zmienna 'num1' przechowuje nową wartość '5' typu number
</script>Obydwie wartości są trzymane w osobnych zmiennych i są od siebie odseparowane. Manipulowanie wartością poprzez jedną zmienną nie wpływa na wartość w drugiej zmiennej.
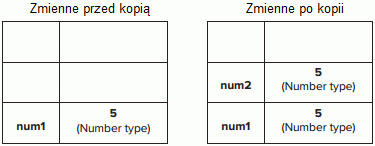
Rysunek. JavaScript - dostęp przez wartość
Obiekty różnią się diametralnie od typów prostych. Obiekty nie mają stałego charakteru, można je dynamicznie modyfikować poprzez usuwanie lub dodawanie nowych wartości. Wartościami obiektów mogą być inne obiekty lub typy proste. Trzy typy proste number, string, boolean mają swoje odpowiedniki w postaci obiektów.
<script>
var osoba = new Object(); // zmienna przechowuje pusty obiekt
osoba.name = "Karol"; // rozszerzamy obiekt
document.write(osoba); // [object Object]
document.write("<br>");
document.write(osoba.name); // Karol
document.write("<br>");
document.write(typeof osoba); // object
</script>Z obiektami nieustannie związane będzie pojęcie referencji.
Referencja (reference) to wartość, która zawiera informacje o położeniu innej wartości w pamięci lub na innym nośniku danych. W odróżnieniu od wskaźników, zarządzanie referencjami realizowane jest wyłącznie przez kompilator lub interpreter, a programista nie posiada żadnych informacji o konkretnym sposobie implementacji referencji.
W JavaScripcie obiekty są przekazywane przez referencję. W przeciwieństwie do innych języków, w JS nie ma możliwości bezpośredniego dostępu do alokowanej pamięci, dlatego bezpośrednia manipulacja przestrzenią pamięci obiektu nie jest możliwa. Kiedy zmieniamy obiekt, tak naprawdę pracujemy na referencji do tego obiektu, zamiast na obiekcie we własnej postaci.
Kiedy zmienna referencyjna # (wskazująca na obiekt) jest przypisywana do innej zmiennej, to wartość trzymana w tej zmiennej również jest kopiowana do nowej zmiennej. Różnica względem typów prostych jest taka, że kopiowaną wartością jest aktualny wskaźnik do obiektu trzymanego na stercie (heap).
<script>
var obj1 = new Object(); // nowy obiekt z pierwszą referencją 'obj1'
var obj2 = obj1; // kolejna referencja 'obj2' do nowego obiektu
obj1.name = "Karol"; // Ustawiamy nową wartość poprzez 'obj1'
document.write(obj2.name); // Karol - odczytujemy nową wartość poprzez 'obj2'
</script>Obydwie referencje wskazują na ten sam obiekt w pamięci. Manipulowanie jedną zmienną będzie miało odzwierciedlenie w drugiej zmiennej.
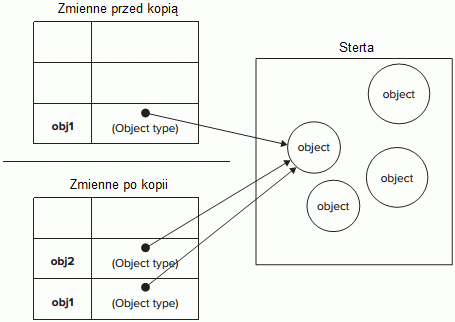
Rysunek. JavaScript - dostęp przez referencję
Od razu uprzedzam, że w przykładach (i ogólnie w kursie) będę często stosował termin "referencja" w odniesieniu do zmiennej trzymającej dowolny typ danych. W tym kontekście chodzi mi o to, że za pomocą konkretnej zmiennej możemy odwołać się do danej wartości, którą można odczytać i zmienić. Należy jedynie pamiętać o specyficznych aspektach przekazywania wartości przez referencję w przypadku obiektów. W niektórych źródłach słowo "referencja" zostało zarezerwowane jedynie dla wartości typu obiektowego.
Kolejny przykład:
<script>
var a = [0, 1, 2, 3]; // zmienna 'a' jest referencją do pierwszej tablicy (obiektu tablicowego) w pamięci
var b = a; // zmienna 'b' jest referencją do tego samego obiektu, co zmienna 'a' (to nie jest kopia!)
var c = a; // zmienna 'c' jest referencją do tego samego obiektu, co zmienna 'a' i 'b' (to nie jest kopia!)
a = 3; // zmienna 'a' jest teraz referencją do liczby 3
document.write(a); // 3
document.write("<br>");
document.write(b); // 0,1,2,3 - zmienna 'b' wciąż wskazuje na pierwszą tablicę [0, 1 ,2, 3]
document.write("<br>");
document.write(c); // 0,1,2,3 - zmienna 'c' wciąż wskazuje na pierwszą tablicę [0, 1 ,2, 3]
document.write("<br><br>");
b.push(4); // // dodajemy nową wartość do obiektu wskazywanego przez zmienną 'b'
document.write(b); // 0,1,2,3,4
document.write("<br>");
document.write(c); // 0,1,2,3,4 - zmienna 'c' widzi zmiany przeprowadzone za pomocą zmiennej 'b' (ten sam obiekt)
document.write("<br><br>");
var d = [0, 1, 2, 3, 4]; // // zmienna 'd' jest referencją do drugiej tablicy (obiektu tablicowego) w pamięci
document.write(b); // 0,1,2,3,4 - druga tablica wygląda tak samo jak pierwsza tablica, ale są to dwa różne obiekty!
document.write("<br>");
document.write(b == d); // false - zmienna 'b' (i 'c') to referencje do innego obiektu niż zmienna 'd'
</script>Przy modyfikowaniu obiektów należy uważać na referencyjne przekazywanie. Zmiana dokonana na obiekcie wskazywanym przez jedną referencje będzie widoczna we wszystkich odpowiadających referencjach. Czasami zachowanie to jest niepożądane, w razie konieczności należy sklonować obiekt, czyli utworzyć nowy obiekt i przekopiować do niego wszystkie właściwości ze starego obiektu.
Uwalnianie niepotrzebnej pamięci#
Większość problemów z zarządzaniem pamięcią występują w tej fazie. Najtrudniejszym zadaniem jest stwierdzenie, kiedy "przydzielona pamięć nie jest już potrzebna". Często wymaga od programisty wskazania, gdzie w programie pewien kawałek pamięci nie jest już potrzebny i może zostać zwolniony.
Interpretery języków wysokiego poziomu zazwyczaj posiadają dedykowane narzędzie zwane zbieraczem śmieci (garbage collector), w skrócie GC. Zadaniem GC jest śledzenie alokowanej pamięci i automatyczne uwalnianie jej, kiedy nie jest już potrzebna.
Na przestrzeni lat opracowano wiele algorytmów usprawniających pracę GC. Omówię tylko dwa podstawowe rozwiązania stosowane w maszynach JS, gdyż pozwalają zrozumieć sens całego zagadnienia.
Garbage collection#
Pisałem już w podstawach DOM, że cała strona internetowa to tak naprawdę obiekty JavaScript umieszczane w pamięci operacyjnej. Jak dobrze wiemy, obiekty JS mogą pochodzić z rdzenia ECMAScript, od gospodarza (DOM, BOM i inne) oraz mogą być tworzone przez nas samych (w tym wypadku zaliczane są do obiektów rdzennych). Każdy obiekt zajmuje odpowiednią dla siebie część pamięci RAM. W czasie życia strony będziemy mieli do czynienia z dużą liczbą obiektów, czasami będziemy je sami modyfikować, dodawać lub usuwać. Robiąc to w nieodpowiedni sposób możemy w prosty sposób doprowadzić do zajęcia całej dostępnej pamięci RAM, w konsekwencji uruchamiając proces wolnego stronicowania systemowego. Na szczęście maszyny JS mają odpowiednie mechanizmy zabezpieczające.
Podobnie jak w wielu nowoczesnych językach wysokiego poziomu, które zawierają elementy niskopoziomowego zarządzania pamięcią, tak i w większości środowisk uruchomieniowych JavaScriptu występuje mechanizm automatycznego oczyszczania pamięci (garbage collection). GC odpowiada za samodzielne wyszukanie i zwalnianie pamięci, czyli kasację nieużywanych obiektów. Może to być cudowne rozwiązanie, uwalniające programistę od nużących detali kojarzących się bardziej z księgowością niż z programowaniem.
Automatyczne zarządzanie pamięcią wiąże się jednak z pewnym kosztem. Wszystkie z wyjątkiem najbardziej zaawansowanych implementacji GC, w czasie odśmiecania "zamrażają" całe środowisko. W związku z tym, że JavaScript jest w zasadzie jednowątkowy, powoduje to zablokowanie interfejsu użytkownika na czas poświęcony procesowi GC.
W przypadku większości aplikacji mechanizm GC jest całkowicie przezroczysty. Okresy zablokowania środowiska uruchomieniowego są na tyle krótkie, że całkowicie umyka to uwadze użytkowników. Jednak w miarę zajmowania przez aplikację coraz większych obszarów pamięci wydłuża się czas niezbędny do wyszukania nieużywanych obiektów i ostatecznie może osiągnąć poziom, który będzie zauważalny dla użytkownika. Gdy to nastąpi, aplikacja w dość regularnych odstępach czasu będzie działać mniej lub bardziej ociężale. W miarę narastania problemu może dojść nawet do zablokowania przeglądarki. Oba te efekty mogą wpłynąć niekorzystnie na ocenę aplikacji przez użytkowników.
Większość nowoczesnych platform dostarcza wyrafinowanych narzędzi umożliwiających monitorowanie wydajności procesu GC w środowisku uruchomieniowym i podgląd bieżącego zestawu analizowanych obiektów w celu zdiagnozowania problemów związanych z oczyszczaniem pamięci. Przez długi czas środowiska uruchomieniowe JS nie mieściły się w tej kategorii. Dopiero od niedawna zaczęto implementować w przeglądarkach dedykowane narzędzia przeznaczone do analizy zużycia pamięci. W przypadku Firefoksa wystarczy wpisać w pasku adresowym polecenie about:memory. Dostaniemy ciekawy raport zużycia pamięci przez każdy komponent, ponadto możemy wykonać kilka akcji (np. wywołać globalne albo cykliczne czyszczenie).
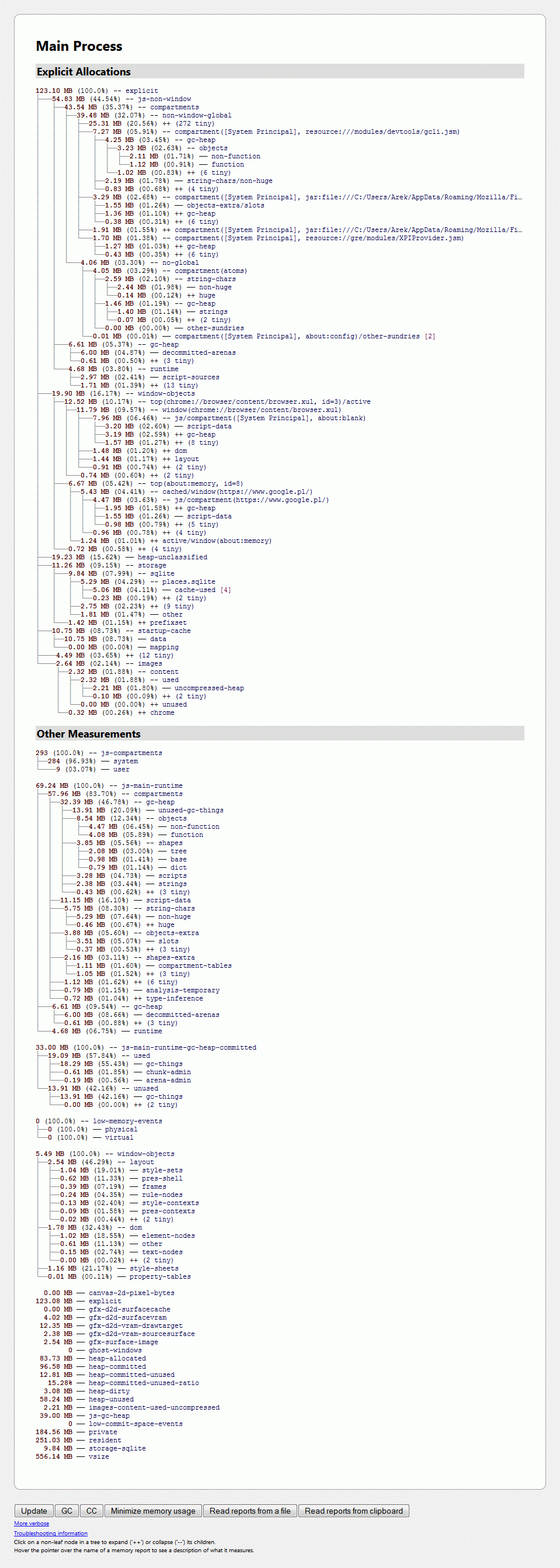
Rysunek. Zakładka about:memory do zarządzania pamięcią w Firefoksie
Pozostałe przeglądarki mogły już wprowadzić podobne rozwiązania. Dzięki nim programiści mogą oszacować, czy za opóźnienia interfejsu użytkownika odpowiada słaby algorytm w naszych programach, czy może mechanizm automatycznego oczyszczania pamięci.
Algorytm zliczania referencji (reference counting)#
W kontekście zarządzania pamięcią najważniejszą sprawą jest referencja między obiektami, która oznacza powiązanie między jednym a drugim obiektem. Może być ona bezpośrednia lub pośrednia. Przykładowo instancja obiektu ma referencję do swojego prototypu (referencja pośrednia) oraz do swoich wartości we właściwościach (referencja bezpośrednia).
Także w tym kontekście pojęcie "obiektu" może mieć szersze znaczenie niż regularny obiekt JavaScriptu, gdyż dotyczy także zasięgów w funkcjach oraz globalnego zasięgu leksykalnego.
GC oparty na zliczaniu referencji (reference counting) jest najprostszym algorytmem odśmiecania, opracowanym w 1959 roku przez Johna McCarthy'ego na potrzeby zarządzania pamięcią w języku programowania Lisp.
W metodzie tej, wraz z każdym zaalokowanym obiektem, skojarzony jest licznik (domyślna wartość wynosi 0), który służy do zliczania wszystkich aktualnych odwołań do obiektu. Za każdym razem, kiedy tworzone jest nowe odwołanie do obiektu, licznik ten jest zwiększany o jeden, natomiast kiedy odwołania te są usuwane, licznik jest zmniejszany o jeden. Kiedy wartość licznika osiągnie zero, oznaczać to będzie, że dany obiekt nie jest już osiągalny w prawidłowy sposób, więc można zwolnić pamięć mu przydzieloną. Jeśli przed skasowaniem ów obiekt sam używał referencji do innych obiektów, to liczniki odwołań tych obiektów także są zmniejszane; mogą zatem również osiągnąć wartość zero, co spowoduje rekursywne skasowanie kolejnych obiektów.
Przeanalizujmy teoretyczny przykład zobrazowany za pomocą poniższej grafiki:
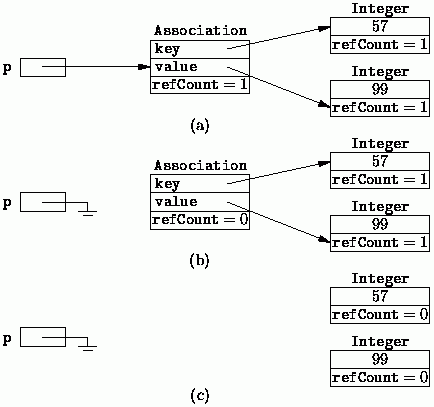
Rysunek. Przykład działania algorytmu zliczania referencji
(a) Mamy obiekt typu Association, do którego prowadzi referencja P, dlatego licznik referencji obiektu ma wartość 1. Obiekt zawiera dwie właściwości key oraz value, które wskazują na nowe obiekty typu Integer. Każdy z tych liczbowych obiektów będzie miał swój licznik referencji ustawiany na wartość 1.
(b) Usuwamy referencję P wskazującą na obiekt typu Association, przez co licznik referencji tego obiektu ma wartość 0.
(c) Obiekt typu Association może zostać usunięty, przez co liczniki referencji do innych obiektów ulegają zmniejszeniu. Jeśli osiągną wartość 0 także zostaną usunięte.
Zaletą metody jest fakt, że alokowana pamięć jest zwalniana tak szybko jak to możliwe - tuż po tym jak licznik referencji osiągnie wartość 0. Metoda ta jest także prosta w implementacji.
Jedną z wad zliczania referencji jest fakt, że nie radzi sobie z wzajemnymi (cyklicznymi) odwołaniami pomiędzy obiektami. Jeśli obiekt A wskazuje na obiekt B, natomiast obiekt B wskazuje z powrotem na obiekt A (np. są to dwa komunikujące się ze sobą obiekty), to żaden z nich nie zostanie nigdy zwolniony (licznik w żadnym z nich nigdy nie osiągnie zera), nawet jeśli obiekty te nie będą osiągalne z poziomu kodu.
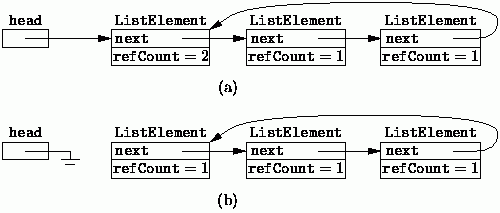
Rysunek. Przykład działania algorytmu zliczania referencji cyklicznych
Wykorzystanie tej metody może także prowadzić do nadmiernej fragmentacji pamięci.
Prosty przykład referencji między obiektami JS:
<script>
// Tworzymy dwa obiekty. Pierwszy obiekt jest referencją do drugiego obiektu poprzez swoją właściwość 'a'.
// Zmienna 'o' jest referencją do pierwszego obiektu.
// Ze względu na obydwie referencje żaden z obiektów nie może zostać usunięty przez GC.
var o = { // pierwszy obiekt
a: { // drugi obiekt
b:2
}
};
var o2 = o; // zmienna 'o2' jest kolejną referencją do pierwszego obiektu
var o = 1; // teraz pierwszy obiekt pierwotnie wskazywany przez 'o' jest wskazywany jedynie przez zmienną 'o2'
var oa = o2.a; // zmienna 'oa' jest referencją do obiektu drugiego
// Obiekt drugi ma teraz dwie referencje, pierwsza przez właściwość o2.a, druga przez zmienną 'oa'.
o2 = "you"; // obiekt pierwszy wskazywany początkowo przez 'o' nie ma teraz żadnej referencji do siebie
// Mógłby zostać usunięty, ale obiekt drugi umieszczony we właściwości 'a' obiektu pierwszego jest wskazywany przez zmienną 'oa'.
// Ze względu na tę referencję obiekt pierwszy usunięty być nie może.
oa = null; // obiekt drugi umieszczony we właściwości 'a' obiektu pierwszego nie ma żadnej referencji do siebie
// Obydwa obiekty mogą zostać usunięte.
</script>Prosty przykład zapętlonych referencji przy użyciu wywołania funkcji #:
<script>
function f(){
var o = {};
var o2 = {};
o.a = o2; // 'o' jest referencją do 'o2'
o2.a = o; // 'o2' jest referencją do 'o'
return "azerty";
}
f();
// Tworzone są dwa obiekty, które odnoszą się do siebie wzajemnie.
// Obiekty tworzone są w zasięgu funkcji, dlatego nie wydostaną się na zewnątrz.
// Po wykonaniu funkcji obiekty są bezużyteczne i powinny zostać usunięte.
// Niestety, algorytm oparty na zliczaniu referencji na to nie pozwala.
// Obiekty są niepotrzebne, ale wciąż powiązane są wzajemnymi referencjami i nie można ich usunąć.
</script>Słabość zliczania referencji obnażona została w przeglądarkach IE do wersji 8, gdzie zapętlone referencje dla obiektów DOM doprowadzały do systematycznych wycieków pamięci # (memory leak):
<script>
function f(){
var div = document.createElement("div");
div.onclick = function(){
doSomething();
};
}
f();
// Zmienna div jest referencją do obiektu DOM.
// Poprzez div.onclick obiekt DOM jest referencją do uchwytu zdarzeń (funkcji).
// Uchwyt zdarzeń także jest referencją dla obiektu DOM, ponieważ div jest zmienną dostępną w zasięgu funkcji.
// Te zapętlone referencje nie pozwalają na usunięcie obiektów i doprowadzają do wycieku pamięci.
</script>Powyższy przykład jest interesujący. W starszych przeglądarkach z rodziny IE cykliczne referencje między obiektami JS nie były problemem dla kolektora JS. GC oparty był na algorytmie znakowania i usuwania dlatego przeglądarki prawidłowo zwalniały pamięć. Jednak nie wszystkie obiekty w IE8 (i wcześniejszych) były natywnymi obiektami JavaScript. Obiekty BOM (Browser Object Model) oraz DOM (DOM Object Model) były implementowane jako obiekty COM (Component Object Model) w C++, i używały GC opartego na zliczaniu referencji. W rezultacie, kiedy występowały cykliczne zapętlenia między obiektami z różnych światów, pamięć dla obiektów COM nigdy nie została zwalniana. W miarę upływu czasu mogło to doprowadzić do całkowitego zapchania pamięci.
Jedynym rozwiązaniem problemu było przerwanie cyklicznej referencji po stronie DOM. Po skończonej pracy z danym elementem wystarczyło przypisać wartość null dla uchwytu zdarzeń. Programiści udostępniali gotowe funkcje kompleksowo realizujące to zadanie na dowolnej liczbie węzłów DOM.
Dopiero w IE9 poczyniono pewne kroki rozwiązujące powyższy problem. W tej wersji przeglądarki obiekty DOM oraz BOM są macierzystymi obiektami JS, dlatego unika się problemów z działaniem dwóch różnych algorytmów GC.
W artykule "Memory Leakage in Internet Explorer - revisited" umieszczono więcej przykładowych wzorców tego typu wycieków z dokładnymi opisami i diagramami.
Algorytm znakowania i usuwania (mark-and-sweep)#
W algorytmie zakłada się istnienie zbioru obiektów zwanych korzeniami (w JS takim korzeniem może być obiekt globalny). Co jakiś czas, zaczynając od korzeni, GC znajduje wszystkie obiekty, do których odwołują się korzenie, następnie znajduje kolejne obiekty, do których odwołują się te znalezione wcześniej itd. Przeprowadzane jest zatem przeszukiwanie w głąb (depth-first search). Skoro można dotrzeć do jakiegoś obiektu od korzenia, to znaczy, że jest on używany (seria referencji). Jest to pierwsza faza algorytmu (mark), w której obiekty osiągalne zostaną odpowiednio oznaczone przez tzw. markbit (ustawiony na 1). Wszystkie pozostałe obiekty są obiektami nieosiągalnymi (markbit ma wartość 0), mogą zostać usunięte przez GC w drugiej fazie algorytmu (sweep).
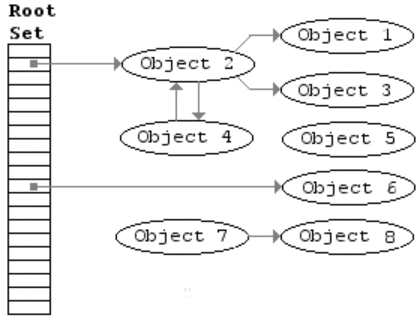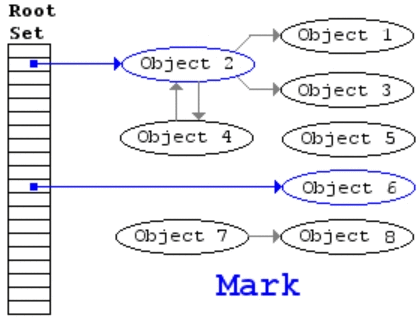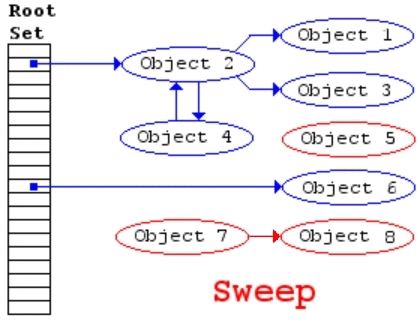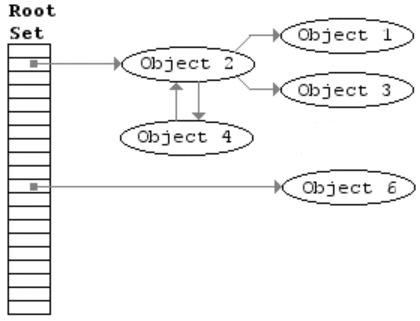
Rysunek. Animacja obrazująca działanie algorytmu mark-and-sweep
Pamięć nie jest odzyskiwana bezpośrednio po stwierdzeniu, że obiekt jest już niepotrzebny, lecz dopiero w momencie stwierdzenie przekroczenia pewnego progu wykorzystania pamięci. Chociaż szczegóły tego działania będą zależne od konkretnych usprawnień algorytmu.
Ten algorytm jest lepszy od poprzedniego, ponieważ zwrot "obiekt nie ma referencji, która na niego wskazuje" odpowiada pojęciu "obiekt nieosiągalny", ale w przypadku wzajemnych referencji algorytmy działają inaczej.
Od tej pory wzajemne referencje między dowolnymi obiektami nie stanowią problemu. W naszym przykładzie z wywołaniem funkcji, dwa nowe obiekty istnieją jedynie w zasięgu funkcji, nie mogą istnieć referencje do tych obiektów z poziomu korzenia (lub jego kolejnych referencyjnych obiektów), dlatego są traktowane jak obiekty nieosiągalne i mogą zostać usunięte przez GC.
To samo odnosi się do przykładu z wyciekami pamięci. Obiekt wskazywany przez zmienną div oraz jego uchwyt zdarzeń są nieosiągalne z korzeni, dlatego mogą zostać usunięte przez GC, mimo że odwołują się do siebie wzajemnie.
Wadą algorytmu jest to, że potrzebne jest wstrzymanie działania programu podczas fazy GC. Jej złożoność wynosi O(V + E), gdzie V to liczba istniejących obiektów, a E referencji. Sprawia to, że metoda ta jest mało przydatna w systemach czasu rzeczywistego. Metoda ta prowadzi także do fragmentacji pamięci.
Począwszy od 2008 roku wszystkie nowoczesne przeglądarki stosują GC oparty na algorytmie mark-and-sweep. Dalsze udoskonalenia poczynione w temacie GC dla JavaScriptu (generational/incremental/concurrent/parallel) w ciągu ostatnich kilku lat są rozwiązaniami usprawniającymi ten algorytm, ale nie zmieniającymi jego istoty. Warto przeanalizować zasadę działania przyrostowego GC wprowadzonego wraz z 16 wydaniem Firefoksa.
Ręczna optymalizacja#
Mechanizm automatycznego oczyszczania pamięci w przeglądarkach internetowych jest niezły, obecnie bazuje na algorytmie mark-and-sweep (i jego usprawnieniach), aczkolwiek nie sprawdza się w każdej sytuacji. GC jest uruchamiany w pewnych odstępach czasu, dlatego w skrajnych przypadkach może nie mieć okazji zainicjowania, np. przy ciągłym uruchamianiu kodu JS w niewielkich odstępach czasu. Kolejna kwestia to ilość alokowanej pamięci dla danych. W przypadku dużej liczby obiektów oczyszczanie może zająć sporo czasu, nawet jeśli stosowane są wymyślne algorytmy usprawniające cały proces.
W razie konieczności można samodzielnie zoptymalizować zużycie pamięci, mamy kilka sposobów do wyboru:
- usunięcie zbędnych węzłów widocznych w modelu DOM strony WWW
- użycie słowa kluczowego
deletew celu usunięcia z pamięci zbędnych węzłów DOM - użycie słowa kluczowego
deletew celu usunięcia z pamięci zbędnych właściwości obiektów JS - usunięcie referencji wskazujących na zbędne obiekty (tzw. dereferencja)
Pierwszą metodę pomijam ponieważ jest ona bardzo skrajna, zazwyczaj to co widoczne na stronie jest potrzebne i nie może zostać usunięte.
Inaczej wygląda sytuacja w przypadku drugiej metody. Bardzo często będziemy mieli do czynienia z węzłami DOM, które nie są widoczne bezpośrednio na stronie, a które wciąż pozostają w pamięci operacyjnej. Węzły takie mogą zostać zwrócone przez metody Node.removeChild() czy Node.replaceChild(). Jeśli będziemy wywoływać wspomniane metody na dużej liczbie węzłów, a węzły te nie będą potem potrzebne, zajmą bez powodu sporo pamięć RAM. Obiekty te zostaną samoczynnie usunięte przez GC w odpowiedniej chwili (jeśli nie będą osiągalne), ale możemy wykonać tę czynność od razu, oto przykładowy wzorzec:
delete removeNode.parentNode.removeChild(removeNode);
Operator delete pozwala na bezpośrednie usuwanie wartości z pamięci, ale efekt działania jest zależny od różnych czynników. Dla zmiennych jawnych czy innych zablokowanych właściwości użycie delete nie daje żadnego efektu.
Ostatnią deską ratunku jest czyszczenie referencji wskazującej na obiekt (dereferencing). Będzie to miało zastosowanie głównie w przypadku wartości wskazywanych przez właściwości obiektów globalnych. Dzięki tej czynności konkretne dane przestaną być osiągalne z poziomu korzenia i zostaną usunięte przez GC, ale nie nastąpi to od razu. Zmienne lokalne w kontekstach wykonania funkcji są automatycznie poddawane procesowi dereferencji, kiedy kontekst kończy działanie i nie jest tworzone żadne domknięcie:
<script>
// Funkcja tworząca nowe obiekty
function createPerson(name){
var localPerson = new Object();
localPerson.name = name;
return localPerson;
}
// Nowy obiekt tworzony w globalnej przestrzeni (wskazywany przez zmienną 'globalPerson')
var globalPerson = createPerson("Iza");
// Pewne operacje przeprowadzone na globalPerson
globalPerson = null; // czyścimy referencję do nowego obiektu (zostanie usunięty przez GC)
</script>W powyższym kodzie zmienna globalPerson wskazuje na nowy obiekt zwracany przez funkcję createPerson(). Wewnątrz createPerson(), zmienna lokalna localPerson przechowuje nowy obiekt, który jest zwracany jako wartość funkcji. Ponieważ localPerson po zakończeniu działania funkcji createPerson() jest nieosiągalna z żadnego korzenia, to nie musi być doraźnie poddawana dereferencji. Odwrotna sytuacja występuje w przypadku zmiennej globalPerson, która znajduje w globalnej przestrzeni, wskazuje na obiekt osiągalny z poziomu korzenia, dlatego jeśli chcemy się go pozbyć musimy wyczyścić referencję na ten obiekt, czyli zmiennej globalPerson przypisać inną wartość (np. null).
Samodzielna dereferencja zmiennych będzie przydatna nie tylko w przypadku zapętlonych referencji (dla starszych przeglądarek), ale także w ogólnym usprawnianiu działania GC, głównie dzięki porządkowaniu globalnej przestrzeni.
Przykład z życia#
Na zakończenie jeszcze jeden przypadek, z którym w przeszłości miałem do czynienia, a który niewątpliwie związany był z procesem odśmiecania pamięci. Miałem napisać pewien skrypt, który automatycznie przejdzie przez wiele stron, na każdej pobierze informacje i zapisze je do pliku, ewentualnie wykona drobne zmiany w drzewie DOM aktualnej strony. Całość miała być na tyle szybka, na ile byłoby to możliwe. Przejścia między stronami wprowadziłem bez żadnych opóźnień.
Skrypt uruchamiany był w przeglądarce Firefox. Przez długi czas nie było z nim problemów. Wyglądało to tak, że po pewnej liczbie przejść proces oczyszczania pamięci uruchamiał się samodzielnie i wykonywał swoją robotę. Pewnie między wczytywaniem kolejnej strony było wystarczająco dużo czasu, żeby GC został zainicjowany.
Traf chciał, że przy pewnym wydaniu Firefoksa został "zepsuty" GC, tzn. przy takim wykonaniu skryptu nie miał on czasu na zainicjowanie. W skutek tego, po 30-minutowej pracy skryptu cały RAM był zajęty, a przeglądarka zaczynała działać bardzo wolno, niejednokrotnie ulegała crashowi. Dopiero po wprowadzeniu odpowiednich modyfikacji w skrypcie (wymuszenie czasowej przerwy po określonej liczbie przejść) całość zaczęła normalnie funkcjonować. Kolejna wersja Firefoksa przyniosła poprawę mechanizmu GC, ale dzięki całej sytuacji zacząłem w szerszym stopniu interesować się sposobami optymalizacji pamięci, co wyszło mi tylko na dobre.