Podstawy#
Rodzaje dokumentów#
DOM jest technologią, która przeznaczona została do współpracy z dwoma rodzajami dokumentów:
- dokumentami XML (i wszystkimi pochodnymi)
- dokumentami HTML
Na temat (X)HTML-a i jego historii pisałem już w innych częściach witryny (link1, link2). Były to suche chronologiczne fakty, bez zagłębiania się w przyczyny rozwoju osobnych języków. W tym miejscu postaram się opisać kluczowe rzeczy dla obydwu rodzajów dokumentów. Dopiero w dalszej części skupię się na dokładniejszej analizie poszczególnych poleceń ze specyfikacji DOM4.
Pochodzenie#
Rodowód każdego języka znacznikowego najlepiej prezentuje poniższa infografika:
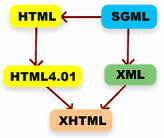
Rysunek. Rozwój języków znacznikowych
Wszystko zaczęło się w 1960 roku, gdy IBM pracował nad systemem prezentowania i organizowania dużych ilości danych. Nazwano go wówczas GML (General Markup Language) a po latach prac, w 1978 roku przekształcono na SGML (Standard Generalized Markup Language). W 1986 roku opublikowana została specyfikacja ISO 8879 dla SGML-a.
SGML to metajęzyk #, czyli język, który definiuje nowe elementy, na przykład znaczenie nawiasów trójkątnych oraz ich lokalizację, ale pozwala programistom decydować o szczegółach zawartości tych nawiasów. Innymi słowy, jest to język umożliwiający tworzenie nowych języków.
Przed pojawieniem się WWW język SGML był głównie wykorzystywany w złożonych systemach dokumentacji, takich jak TEI (Text Encoding Initiative). SGML roztoczył wokół siebie aurę tajemniczości ze względu na swoją złożoność i ogromną różnorodność. Złożoność języka SGML jest jego największą zaletą, ale kryją się za nią również pewne niebezpieczeństwa. Jednym z nich jest tworzenie parserów, niezwykle trudne zadanie ze względu na ogrom języka SGML. W praktyce projektanci używali jedynie podzbioru poleceń dostępnych w języku SGML.
HTML#
Jednym z pierwszych projektów bazujących na SGML-u, który zdobył globalną popularność, było dzieło Tima Bernersa-Lee. Tim pracując w CERN-ie w 1990 roku, eksperymentował z językami znacznikowymi, które byłyby najodpowiedniejsze dla opracowywanego właśnie uniwersalnego systemu informacji, określanego jako WWW. Miał to być prosty przenośny język hipertekstowy, dla którego można by tworzyć programy (np. przeglądarki). To on zdecydował, że język powinien być w jak największym stopniu zrozumiały dla ówczesnych pracowników CERN, dlatego nadał mu wygląd języka SGML - na bazie używanego wtedy przez CERN podzbioru SGMLGuid - i udostępnił pod nazwą HyperText. Wygląd wczesnego HTML-a jest niezwykle podobny do SGMLGuid, który był złożonym językiem formatowania dokumentów. Jedyna różnica polegała na zmniejszeniu liczby znaczników oraz dodaniu znacznika łącza <A>, który jest wykorzystywany do wstawiania łączy hipertekstowych wewnątrz dokumentów.
Mimo że wczesny HTML (zanim eksperci od SGML-a dobrali się do niego) wyglądał podobnie jak SGML, zasadniczo nie było żadnej ścisłej definicji języka, z wyjątkiem notatek Tima. Dlatego programy tworzone do analizowania i wyświetlania tekstu HTML były pełne błędów i często usilnie starały się wyświetlić błędny HTML, bez sprawdzania go na podstawie ścisłej definicji. Do dnia dzisiejszego niewiele w tej kwestii się zmieniło.
Dopiero na początku 1992 roku, kiedy programiści SGML, między innymi Dan Connolly, zaczęli korzystać z sieci WWW, zdecydowali się utworzyć definicje typu dokumentu dla języka HTML, które mogły posłużyć do sprawdzania poprawności dokumentów. Jednak było za późno - tworzono już przeglądarki internetowe obsługujące niepoprawny kod HTML. Użytkownicy HTML mieli za złe złożoność SGML, a programiści SGML zarzucali językowi HTML oczywisty brak struktury i niezgodność ze specyfikacją SGML. Społeczność SGML-ową dzieliły kłótnie pomiędzy różnymi stronami, a tego społeczność WWW starała się unikać.
W tym czasie coraz więcej ludzi tworzyło dokumenty HTML i powstawało coraz więcej programów do ich wyświetlania. Pojawiła się popularna przeglądarka Mosaic, która umożliwiała po raz pierwszy korzystanie z WWW tysiącom ludzi, przyspieszając rozwój WWW, ale wciąż próbowała przed wyświetleniem naprawić błędny kod. Wprowadzała też nowe funkcje, takie jak wyświetlanie rysunków osadzonych w dokumentach.
Doszło do tego, że projektanci dołączali znaczniki do języka HTML według własnych zachcianek. Microsoft wprowadził obsługę elementu <MARQUEE>, a Netscape - znacznika <BLINK>, co powodowało podział rynku i niebezpieczną destabilizację, która doprowadziła HTML (język o niezbyt stabilnej architekturze) do stanu całkowitego pandemonium, gdzie nieustannie dodawano nowe funkcje.
Wszystkie te nieporozumienia miała rozwiązać organizacja W3C, powołana do życia w roku 1994 i kierowana przez Tima Bernersa-Lee. Wydano zestaw specyfikacji HTML, w nadziei, że producenci oprogramowania (łącznie z firmami Microsoft i Netscape, które były członkami W3C) dostosują się do nich. W późniejszym czasie powstało kilka kolejnych wydań specyfikacji HTML. Niestety, rozszerzenia nadal były dodawane w programach, a ludzie nadal tworzyli dokumenty HTML niezgodne ze standardem. Należało coś z tym zrobić.
Takim pierwszym krokiem ku lepszemu światu miał być język XML, o którym będzie nieco później. Jego odmianę stanowi język XHTML, który jest wyrażeniem HTML-a za pomocą składni XML. Miało być lepiej, poprawniej, ale realia po raz kolejny wzięły górę. XHTML nie zyskał dużej popularności ze względu na wiele problemów związanych z jego poprawnym stosowaniem.
Na dzień dzisiejszy język HTML występuje w wersji 5. Od strony znacznikowej nie jest żadną rewolucją. Usunięto z niego to co zbędne, dodano kilka wyczekiwanych elementów, zdefiniowano sposoby obsługi błędów, tak żeby każdy program robił to w jednakowy sposób. Ogólnie można powiedzieć, że HTML5 tak naprawdę dostosowuje się do tego, co już było, czyli implementacji w przeglądarkach. Dalej można robić błędy, które będą korygowane automatycznie, ponadto w niektórych przypadkach składnia języka pozwala na więcej, niż było to w przeszłości. Ciężko wyrokować czy jest to słuszne posunięcie, czy może spowodować zbyt dużą "rozwiązłość" ze strony programistów. Mnogość opcji nigdy nie będzie problemem jeśli pozostawiony zostanie swobodny wybór. Zawsze możemy ograniczyć składnię języka HTML5 do pewnego podzbioru i sumiennie ją stosować w swoich projektach.
HTML jest potrzebny, dobrze się stało, że rozwój języka nie został porzucony. Informacje umieszczone w sieci WWW z wykorzystaniem HTML-a są dorobkiem całej ludzkości, powinny być dostępne tak długo, jak to tylko możliwe. Całkowite zerwanie z kompatybilnością poprzednich rozwiązań (jak zakładano w XHTML 2.0) było czymś irracjonalnym, i szybko spotkało się z wylaniem kubła zimnej wody na głowy autorów tego pomysłu. HTML5 może być z powodzeniem stosowany przez profesjonalistów jak i amatorów. Osoby chcące tworzyć czysty i poprawny kod mogą to robić dalej, ale też pozostaje miejsce dla osób, które aż tak dużych umiejętności nie mają. Jeśli komuś taki zestaw nie wystarcza, zawsze może sięgnąć po XML-a i tworzyć to, co mu się żywnie podoba.
XML#
Złożoność języka SGML zachęciła grupę osób do zastanowienia się nad możliwością utworzenia podzbioru języka SGML, języka zbudowanego wyłącznie dla sieci WWW, języka o prostej strukturze, który mógłby być w łatwy sposób przetwarzany bez odwoływania się do definicji tego języka. Jon Bosak, Dan Connolly, Tim Bray i wielu innych pracowników organizacji W3C, podchwycili pomysł stworzenia języka XML i zamienili go w rzeczywistość. W roku 1997 został on przedstawiony na konferencjach dotyczących sieci WWW, a w 1998 roku opublikowane zostały zalecenia W3C dotyczącego tego języka.
XML jest zatem metajęzykiem otrzymanym z SGML, stanowi podzbiór SGML-a, toteż nie definiuje - w przeciwieństwie do HTML - znaczników, a jedynie konwencję składniową. W metajęzykach takich jak SGML czy XML, używamy w odniesieniu do zdefiniowanych na ich podstawie języków dziedzinowych pojęcia aplikacji #:
- HTML - język dziedzinowy oparty na SGML (aplikacja SGML).
- XSLT, XHTML, SVG, XUL i wiele innych - języki dziedzinowe oparte na XML (aplikacje XML).
Jako aplikacje XML możemy tworzyć nowe języki, które są tanie i dają się zastosować dla WWW. Jednak język XML nie jest przeznaczony wyłącznie do wykorzystania w sieci WWW. Jest on również często stosowany w dużych systemach baz danych.
Rysunek. Rodzina standardów W3C bazujących na języku XML
Zazwyczaj większość dokumentów XML jest zgodna z SGML, ale nie na odwrót. Istnieją dokumenty XML, które nie są poprawnymi dokumentami SGML, lub też przetwarzane zgodnie z regułami SGML mogą zostać zinterpretowane wbrew intencji autora. Powodem tego jest mechanizm zamykania pustych znaczników XML (jak np. <p/>, które w XML-u jest równoważne <p><p>), kolidujący ze skróconą notacją znaczników SGML znaną jako Null End Tag, w skrócie NET (np. <p/abc/, co w dokumentach SGML może być równoważne <p>abc</p> lub być niepoprawne, jeśli definicja dokumentu zabrania stosowania NET).
W przypadku XML zapis <p/>abc/ odpowiada <p></p>abc/, podczas gdy w SGML-u <p>abc</p>. Notabene cecha ta jest jednym z najczęściej wysuwanych argumentów przeciwko tezie o kompatybilności opartego na XML-u języka XHTML z opartym o SGML językiem HTML (chociaż skrócone tagi nigdy nie zostały wprowadzone w rzeczywistych implementacjach HTML-a). Istnieją również inne cechy różniące te dwa metajęzyki.
Jedną z kluczowych cech języka XML jest fakt, że specyfikacje definiują go na tyle dokładnie, że nie ma konieczności jego walidacji przed uruchomieniem. Oznacza to, że zastosowania języka XML muszą być zgodne z zestawem prostych, ale ścisłych zasad, aby być dobrze sformułowane (well-formed). Aby jednak tworzyć same aplikacje, musimy mieć obowiązujący XML, co można uznać za uszczegółowienie dobrego sformułowania. Obydwa zagadnienia opiszę dokładnie w dalszej części.
Obecnie XML występuje w wersjach 1.0 i 1.1, przy czym obie wersje traktowane są jako osobne rozwiązania, gdyż nie są ze sobą kompatybilne. Wersja 1.1 wprowadza zmiany w zestawie dopuszczanych znaków, co ma związek z modyfikacjami standardu Unicode przeprowadzanymi już po publikacji wersji 1.0. Samo W3C nie traktuje tej wersji jako następcy dla 1.0, raczej jako jego odmianę do bardzo specyficznych zastosowań . Wciąż zalecane jest korzystanie z wersji 1.0 wszędzie, gdzie to możliwe. Wersja 1.0 z kodowaniem UTF-8 jest uznawana za domyślną, jeśli nie zostanie dołączony prolog na początku dokumentu XML. Obie wersje są dalej wspierane i rozwijane przez W3C, a kolejne ich edycje, jak dotąd, pojawiają się w tym samym czasie.
Poprawność dokumentu#
XML sam w sobie jest językiem znacznikowym, za pomocą którego możemy od razu tworzyć nowe dokumenty. W takiej sytuacji nie ma specjalnych narzutów co do stosowania konkretnych elementów, ich atrybutów czy dopuszczalnej zawartości. Jedyne co trzeba spełnić, to zachować ogólne zasady składni samego XML-a.
Prosty przykład:
<?xml version="1.0"?>
<ARTYKUL>
<TYTUL>
Tytuł artykułu
</TYTUL>
<TRESC>
Treść artykułu
</TRESC>
</ARTYKUL>Mówimy o dokumencie, że jest poprawny składniowo, czyli dobrze sformułowany (well-formed), jeżeli jest zgodny z regułami składni XML. Reguły te obejmują m.in. konieczność domykania wszystkich znaczników, stosowania wartości w atrybutach (nawet logicznych), wykluczenie błędnego mieszania znaczników itd., czyli wszystkich podstawowych zasad zawartych w specyfikacji XML. Nie będę opisywał poszczególnych wytycznych w drobnych szczegółach, nie jest to kurs XML-a, w razie potrzeby należy poszukać informacji na własną rękę. Najlepiej bezpośrednio przeanalizować specyfikację XML, gdyż jest bardzo minimalistyczna i przystępnie napisana.
Dokument niepoprawny składniowo (mal-formed) nie może być przetworzony przez parser XML, koniecznie musi zostać zwrócony błąd. Zazwyczaj podawany jest przy tym rodzaj błędu oraz wiersz, w którym błąd wystąpił.
Mówimy o dokumencie, że jest poprawny strukturalnie, czyli obowiązujący/walidujący (valid), jeżeli ma przypisaną deklarację typu dokumentu (document type declaration) i jest zgodny z ograniczeniami zawartymi w tej deklaracji, tzn. dodatkowymi regułami określonymi przez użytkownika (Document Type Definition - DTD). Do tworzenia tych reguł służą specjalne języki. Najpopularniejszymi są DTD, XML Schema oraz RELAX NG. Oczywiście warunkiem koniecznym do uzyskania poprawności strukturalnej jest zachowanie poprawności składniowej.
Parsery XML (XML processor) można podzielić na dwie grupy:
- z walidacją - sprawdzają poprawność składniową i strukturalną, czyli są w stanie odczytać i przetworzyć schematy (np. DTD).
- bez walidacji - sprawdzają jedynie poprawność składniową.
Akurat w przypadku XML-a przeglądarki internetowe obsługujące ten standard traktują DTD tak jak powinny, co dla HTML-a było czymś abstrakcyjnym (chociaż definiowanym w specyfikacjach).
Mówiąc krótko, wszystkie dokumenty XML muszą być poprawne składniowo żeby zostały przetworzone, ale wymóg poprawności strukturalnej będzie już zależny od typu danego parsera XML. Brak mechanizmu walidującego w parserze XML może być po części niwelowany poprzez zastosowanie zewnętrznych narzędzi, potocznie zwanych walidatorami.
Schematy#
Wyjątkowość języka XML wynika z faktu, że każdy może definiować nowy zbiór elementów. Co się jednak stanie, jeśli chcemy stworzyć całkowicie nowy język na podstawie XML-a? Potrzebny jest jakiś sposób ograniczenia dobrze sformułowanego XML, aby określić jakie nazwy znaczników mają obowiązywać, jakie atrybuty mogą zawierać oraz jaką zawartość musi lub może mieć dany element lub atrybut.
Dodatkowe ograniczenia pozwala wprowadzić dokument zwany schematem (schema). Jest to po prostu dokument sterujący uporządkowaniem, rozmieszczeniem i innymi szczegółami znaczników w języku, zgodnie z XML (co technicznie nazywa się aplikacją XML). Istnieją zasadniczo dwa typy schematów:
- DTD (Document Type Definition) - opierające się na DTD języka SGML (więcej).
- XML schema - będące dobrze sformułowanym XML (więcej).
Każdy z tych rodzajów dokumentów musi zostać utworzony za pomocą właściwego dla siebie języka. Tylko jeden język DTD jest szczegółowo opisany w specyfikacji XML (można przeczytać mój opis), ale jest kilka języków schematów. Jeden z nich to język XML Schema opracowany przez W3C, o którym wiele osób myśli jak o schemacie XML. Należy uważać, aby nie mylić języka XML Schema ze schematami XML w ogóle (pojęcia można rozróżnić po wielkości znaku "S" w nazwach). Inne języki schematów to:
- XDR Schema - stworzony przez Microsoft
- RELAX NG - utworzony i rozwijany przez grupę OASIS
- Schematron - autorstwa Ricka Jelliffe
Definicje DTD dla języka XML opierają się na definicjach DTD dla języka SGML i jako takie nie były przygotowane dokładnie na potrzeby XML. Na przykład trudno jest wymusić mieszanie przestrzeni nazw i typów danych w definicjach DTD dla XML. Właśnie dlatego pojawił się nowy mechanizm w postaci schematów XML, który opiera się na samej składni XML i przez to oferuje o wiele większe możliwości.
DTD jest integralną częścią XML-a, dlatego nie ma problemów z dołączaniem plików DTD do plików XML. W przypadku schematów XML jest nieco inaczej. Mechanizm kojarzenia dokumentu XML ze schematem zależy od języka schematu. Połączenie może odbywać się za pomocą znaczników, domyślnie, lub za pośrednictwem pewnych środków zewnętrznych. Większa część parserów XML wspiera mechanizm DTD, ale niektóre z nich potrafią obsługiwać także schematy XML.
Nie zawsze istnieje konieczność dołączania schematów do dokumentów, aby móc skorzystać z konkretnej aplikacji XML. Niektóre programy przetwarzające, takie jak przeglądarki internetowe, mają na stałe "zaszyte" reguły dla niektórych języków bazujących na XML-u (głównie tych standaryzowanych przez W3C). W takich przypadkach można swobodnie mieszać ze sobą języki za pomocą mechanizmu przestrzeni nazw. Najpopularniejszymi aplikacjami XML będą języki SVG i MathML, które w przypadku HTML5 obsługiwane są natywnie przez parser HTML, bez potrzeby określania przestrzeni nazw dla elementów czy atrybutów.
Wyświetlanie#
Najprostsza sytuacja będzie w przypadku (X)HTML-a. Wyglądem dokumentów (X)HTML steruje się za pomocą Kaskadowych Arkuszy Stylów (CSS). Ponadto większość narzędzi przetwarzających ma wbudowane domyślne style, które są stosowane z każdym dokumentem. Domyślne style mogą być nadpisane przez nasze własne deklaracje, wszystko oparte jest na zasadzie kaskadowości i dziedziczeniu.
XML domyślnie nie zawiera żadnych informacji na temat sposobu wyświetlania elementów. Próba bezpośredniego otworzenia dokumentu XML w przeglądarce internetowej zazwyczaj zaowocuje zwróceniem drzewa dokumentu. XML może być wyświetlany z wykorzystaniem technologii arkuszy stylów (style sheet) wstawianych za pomocą instrukcji przetwarzania. Dwie najpopularniejsze technologie wykorzystywane do wyświetlania XML-a to:
- CSS - identyczny, jak dla HTML-a.
- XSLT - transformacja jednego dokumentu w inny, np. XML na HTML, który będzie miał zdefiniowany wygląd.
CSS jest znany i powszechnie używany, dlatego nie wymaga dodatkowego opisu. Warto napisać parę słów na temat drugiej możliwości.
XSLT (Extensible Stylesheet Language Transformation) jest potężnym narzędziem, ponieważ pozwala transformować strukturę dokumentu XML (poprzez zmianę elementów i danych w dokumencie) na inny dowolny dokument. XSLT nie zezwala, w odróżnieniu od CSS, na definiowanie sposobu wyświetlania dokumentu. Innymi słowy, nie pozwala projektantowi dyktować przeglądarce stylu poszczególnych dokumentów. Istnieje jednak możliwość transformowania poszczególnych elementów do języka znaczników zawierającego zestaw elementów o określonym stylu. Same arkusze XSLT są dobrze sformułowanymi dokumentami XML. Większość współczesnych przeglądarek obsługuje mechanizm XSLT w wersji 1.0.
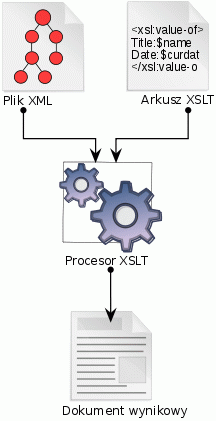
Rysunek. Proces transformacji XSLT
Analiza poszczególnych API#
W ujęciu programistycznym dokumenty to nic innego jak obiekty (pewien rodzaj węzła), i z perspektywy przeglądarek internetowych można je utworzyć z wykorzystaniem dwóch podstawowych sposobów #:
- bezpośrednio wczytując dokument - zaliczymy tutaj wszystkie manualne akcji wykonywane przez użytkownika, np. kiedy otwieramy nowe karty/okna z jakimś adresem lub wczytujemy je do ramki. W takiej sytuacji uruchomiony zostanie dedykowany parser, który automatycznie utworzy obiekt dokumentu z odpowiednim interfejsem (zgodnie z wymogami poszczególnych specyfikacji).
- wywołując dedykowane polecenie po stronie kodu JS - w platformie webowej istnieje sporo poleceń, które pozwalają tworzyć dowolną ilość nowych dokumentów (obiektów) wprost z kodu JS. Każde z nich ma ściśle zdefiniowane zachowanie, jedne od razu zwracają nowy obiekt z konkretnym interfejsem, kiedy w drugich należy uruchomić dedykowany parser, i to od niego będzie zależeć, z jakim dokładnie interfejsem dla nowego dokumentu będziemy mieli do czynienia.
Od konkretnego sposobu tworzenia dokumentu oraz kontekstu, w jakim się to odbywa, będzie zależeć działanie niektórych mechanizmów i dostęp do poszczególnych poleceń. W szczegółach jest to bardzo ciekawe, ale wyjątkowo niespójnie jeśli chodzi o implementację w aktualnych przeglądarkach internetowych.
Można powiedzieć, że w obszarze ogólnej pracy z dokumentami istnieje pięć bazowych interfejsów: Document, XMLDocument, DOMImplementation, DocumentType i DocumentFragment. W tym miejscu doprecyzuję kilka najważniejszych kwestii oraz, w razie potrzeby, umieszczę osobno dodatkowe informacje na temat każdego z nich.
Prawidłowe interfejsy dla tworzonych dokumentów#
Wszystkie dokumenty, w chwili ich tworzenia (dowolnym sposobem), muszą otrzymać prawidłowy interfejs Web IDL. Niestety w przeszłości zdefiniowano kilka interfejsów opisujących różne typy dokumentów, gdzie każdy z nich miał swoje unikatowe polecenia:
- Document - ogólny interfejs z którego dziedziczą pozostałe
- XMLDocument - interfejs właściwy dla dokumentów XML i pokrewnych
- HTMLDocument - interfejs właściwy dla dokumentów HTML
- SVGDocument - interfejs właściwy dla dokumentów SVG
- MathMLDocument - interfejs właściwy dla dokumentów MathML
W raz z pojawieniem się i popularyzacją HTML5, który pozwala na bezpośrednie osadzanie kodu SVG i MathML w kodzie HTML (i odwrotnie), wszystkie te interfejsy (prócz pierwszego) stały się zbędne. Od tej pory każdy dokument jest reprezentowany jedynie przez interfejs Document (z małym wyjątkiem), a jego naturę wyraża się wewnętrznymi stanami (np. typem). Dzięki temu pozostawiono przy życiu jedynie dwa typy/rodzaje dokumentów: XML lub HTML.
Jedną z istotnych konsekwencji nowego podejścia jest to, szczególnie z perspektywy przeglądarek internetowych, że wszystkie nadmiarowe polecenia definiowane dla poszczególnych języków znacznikowych wylądują w interfejsie Document i będą dostępne dla każdego dokumentu, niezależnie od jego rodzaju (wystarczy zerknąć do rozszerzenia interfejsu Document ze specyfikacji HTML). Sama obecność dodatkowych poleceń w obiekcie dokumentu nie oznacza wcale, że można z nich swobodnie korzystać. Tutaj istotny będzie już rodzaj danego dokumentu, gdyż w przypadku dokumentów XML istnieją większe restrykcje, i wywołanie niektórych poleceń zrzuci po prostu błąd. Wszystkie te niuanse należy ustalić samodzielnie poprzez analizę poszczególnych algorytmów dla konkretnych poleceń, na początek proponuję zerknąć na metody Document.open(), Document.close() czy Document.write().
Eksponowanie wszystkich możliwych poleceń dla wszystkich dokumentów (niezależnie od ich typu) nie zwiększy diametralnie zużycia pamięci operacyjnej przez przeglądarki, technicznie rzecz biorąc to lądują one w prototypach i są współdzielone przez każdą instancję obiektu reprezentującego dokument. Dużo poważniejszym problemem będzie ogólne pogorszenie wydajności dostępu do poleceń, a to ze względu na obsługę nazwanych właściwości w każdym możliwym dokumencie, co nie jest wskazane przy jednoczesnym operowaniu na wielu dokumentach (np. poprzez Ajaksa czy Fetch). Wciąż trwa dyskusja, czy nie wprowadzić dodatkowych wariantów dla dokumentów, tj. z obsługą i bez obsługi nazwanych właściwości.
Oczywiście rozszerzanie interfejsu Document (i każdego innego) o kolejne polecenia nie jest obowiązkowe i nie musi dotyczyć każdej implementacji. Wszelkie biblioteki DOM przeznaczone dla różnych języków programowania najczęściej implementują jedynie podstawy umieszczone w specyfikacji DOM4.
Trzeba jednak zaznaczyć, że powyższe wytyczne to dosyć inwazyjna zmiana. Nie wiadomo kiedy, i czy w ogóle, przeglądarki internetowe zaimplementują aktualne wymagania ze wszystkich specyfikacji. Na dzień dzisiejszy jest z tym różnie, i jakoś nie widać wielkiego optymizmu w tym obszarze (DOM - Bug 22960, Mozilla - Bug 897815, Chromium - Bug 238368, Webkit - Bug 110772 ). Z drugiej jednak strony, by nie być totalnym pesymistą, w niektórych programach pewne kroki zostały poczynione (Mozilla - Bug 1017932, Chromium - Bug 146193003, Chromium - Bug 141733006, Chromium - Bug 362955).
#Poniższa tabela zawiera wykaz interfejsów dla zwracanych dokumentów przez różne polecenia w poszczególnych przeglądarkach:
| Polecenie | Firefox | Chrome | IE11 |
|---|---|---|---|
new Document() | Document | Brak obsługi | Brak obsługi |
DOMImplementation.createDocument() | XMLDocument | XMLDocument | XMLDocument |
DOMImplementation.createHTMLDocument() | HTMLDocument | HTMLDocument | HTMLDocument |
text/htmltext/xmlapplication/xmlapplication/xhtml+xmlimage/svg+xml |
HTMLDocument XMLDocument XMLDocument XMLDocument SVGDocument |
HTMLDocument XMLDocument XMLDocument XMLDocument XMLDocument |
HTMLDocument XMLDocument XMLDocument XMLDocument XMLDocument |
Jeśli proponowane zmiany faktycznie się przyjmą, to rozróżnienie między poszczególnymi rodzajami dokumentów najwygodniej przeprowadzić z wykorzystaniem właściwości Document.contentType. Samo sprawdzanie obecności danego polecenia w obiekcie dokumentu nie jest najlepszym pomysłem. Jak wspomniałem nieco wcześniej dokumenty (niezależnie od rodzaju) mają dostęp do wszystkich poleceń, ale nie zawsze będzie można z nich swobodnie korzystać. Na chwilę obecną jedynie przeglądarki Chrome i IE działają zgodnie z tymi wytycznymi, Firefox wciąż utrzymuje podział na kilka różnych interfejsów, i co ciekawe, ma odmienne zachowania w zależności od użytego podstawowego sposobu tworzenia dokumentów. Z drugiej jednak strony wszystkie te programy w dalszym ciągu są wyjątkowo niespójne jeśli chodzi o prawidłową implementację poszczególnych standardów.
Prosty przykład:
<script>
function getInfoDoc(desc, whatDoc){
doc.write(desc + "<br>");
doc.write("Interfejs: " + whatDoc + "<br>");
doc.write("contentType: " + whatDoc.contentType + "<br>");
doc.write("readyState: " + whatDoc.readyState + "<br>");
doc.write("hasFocus: " + whatDoc.hasFocus + "<br>");
doc.write("open: " + whatDoc.open + "<br>");
doc.write("write: " + whatDoc.write + "<br>");
doc.write("links: " + whatDoc.links + "<br>");
doc.write("body: " + whatDoc.body + "<br>");
doc.write("getElementsByName: " + whatDoc. getElementsByName + "<br>");
doc.write("load: " + whatDoc.load + "<br><br>");
}
var doc = document; // domyślny dokument tworzony przez parser HTML
doc.write("typeof HTMLDocument: " + typeof HTMLDocument + "<br>");
doc.write("typeof SVGDocument: " + typeof SVGDocument + "<br>");
doc.write("typeof MathMLDocument: " + typeof MathMLDocument + "<br><br>");
getInfoDoc("Parametry dla domyślnego dokumentu tworzonego przez parser HTML (właściwość document):", doc);
try{
var newDoc = new Document(); // nowy dokument
getInfoDoc("Parametry dla new Document():", newDoc);
}
catch(e){
doc.write("Brak obsługi konstruktora new Document() dlatego zrzucony zostanie błąd:" + "<br>")
doc.write(e + "<br>"); // opis zależny od przeglądarki
doc.write(e.constructor + "<br><br>"); // function TypeError() { [native code] }
}
var newDocXML = doc.implementation.createDocument(null, null, null); // nowy dokument XML
getInfoDoc("Parametry dla createDocument(null, null, null):", newDocXML);
var newDocHTML = doc.implementation.createHTMLDocument(""); // nowy dokument HTML
getInfoDoc("Parametry dla createHTMLDocument(''):", newDocHTML);
var parser = new DOMParser(); // tworzymy nowy parser DOM
var newDoc = parser.parseFromString("", "text/html"); // nowy dokument HTML
getInfoDoc("Parametry dla parseFromString('', 'text/html'):", newDoc);
newDoc = parser.parseFromString("", "text/xml"); // nowy dokument XML
getInfoDoc("Parametry dla parseFromString('', 'text/xml'):", newDoc);
newDoc = parser.parseFromString("", "application/xml"); // nowy dokument XML
getInfoDoc("Parametry dla parseFromString('', 'application/xml'):", newDoc);
newDoc = parser.parseFromString("", "application/xhtml+xml"); // nowy dokument XML
getInfoDoc("Parametry dla parseFromString('', 'application/xhtml+xml'):", newDoc);
newDoc = parser.parseFromString("", "image/svg+xml"); // nowy dokument XML
getInfoDoc("Parametry dla parseFromString('', 'image/svg+xml'):", newDoc);
</script>XMLDocument#
Interfejs XMLDocument, mimo że nigdy nie był częścią żadnego standardu, to i tak do dnia dzisiejszego reprezentuje dokumenty XML we wszystkich aktualnych przeglądarkach internetowych. W założeniach miał on służyć do ewentualnego dodawania kolejnych poleceń przeznaczonych tylko i wyłącznie dla dokumentów XML, ale w praktyce nie było ich zbyt wiele. Zgodnie z nowymi wytycznymi z DOM4 i HTML5 jego istnienie w zasadzie stało się zbędne, no ale z uwagi na kompatybilność wsteczną nie można go całkowicie wyeliminować.
Na prośbę niektórych programistów (głównie z Mozilli) aktualne specyfikacje DOM4 i HTML5 definiują interfejs XMLDocument w następujący sposób (DOM - Bug 14037):
- DOM4 zawiera pusty interfejs XMLDocument (bez żadnych poleceń).
- Jedynym poleceniem zwracającym nowy obiekt dokumentu dziedziczący po interfejsie XMLDocument będzie metoda
DOMImplementation.createDocument(). Pozostałe polecenia tworzące nowe dokumenty, ze wszystkich specyfikacji, mają dziedziczyć bezpośrednio po interfejsie Document i spełniać aktualne wymagania z tych specyfikacji. Na potrzeby starszego kodu specyfikacja HTML5 definiuje dla interfejsu XMLDocument jedynie metodę
XMLDocument.load(), która pozwala pobrać i sparsować wskazany dokument zgodnie z wymogami XML.W ujęciu historycznym metodę
load()z kilkoma dodatkowymi poleceniami umieszczono w interfejsie DocumentLS, który po raz pierwszy pojawił się w roboczej wersji specyfikacji DOM Level 3 Load and Save. Mimo że finalna rekomendacja tejże specyfikacji uległa gruntownej zmianie, to i tak część wcześniejszych poleceń, w szczególności metodaload()oraz właściwośćasynctrafiły już do ówczesnych przeglądarek internetowych zyskując tym samym sporą popularność.
Obecna sytuacja wygląda tak, że dzisiejsze przeglądarki internetowe wciąż implementują interfejs XMLDocument (zresztą niewłaściwe), ale tylko Firefox, Opera (Presto) oraz IE (w formie obiektu ActiveX) wdrożyły metodę XMLDocument.load(). W aktualnym kodzie produkcyjnym nie należy jej używać, istnieją dużo lepsze alternatywy (np. Ajax lub Fetch), i niewykluczone, że w niedalekiej przyszłości metoda (włącznie z interfejsem XMLDocument) zostanie całkowicie usunięta (Mozilla - Bug 983090).
Prosty przykład:
<!DOCTYPE html>
<html>
<p id="info"></p>
<script>
var info = document.getElementById("info");
var newDocXML = document.implementation.createDocument(null, null, null); // nowy dokument XML
info.innerHTML += "Parametry dla dokumentu XML utworzonego metodą createDocument(null, null, null):" + "<br>";
info.innerHTML += "Interfejs: " + newDocXML + "<br>";
info.innerHTML += "contentType: " + newDocXML.contentType + "<br>";
info.innerHTML += "load: " + newDocXML.load + "<br>";
info.innerHTML += "async: " + newDocXML.async + "<br>";
info.innerHTML += "childNodes.length: " + newDocXML.childNodes.length + "<br><br>";
if (newDocXML.load != undefined){
var returned = newDocXML.load("http://www.crimsteam.site90.net/przyklady/html/dodatki/dtd/internal.xml");
info.innerHTML += "returned: " + returned + "<br><br>";
newDocXML.onload = function(){
info.innerHTML += "childNodes.length: " + newDocXML.childNodes.length;
}
}
try{
var newXML = new ActiveXObject("Microsoft.XMLDOM");
info.innerHTML += "Parametry dla obiektu ActiveX w przeglądarce IE:" + "<br>";
info.innerHTML += "typeof doc: " + typeof newXML + "<br>"; // object
info.innerHTML += "typeof doc.load: " + typeof newXML.load + "<br>"; // unknown - oznacza że istnieje
info.innerHTML += "typeof doc.loadXML: " + typeof newXML.loadXML + "<br>"; // unknown - oznacza że istnieje
info.innerHTML += "typeof doc.save: " + typeof newXML.save + "<br>"; // unknown - oznacza że istnieje
info.innerHTML += "typeof doc.fake: " + typeof newXML.fake + "<br>"; // undefined - oznacza że nie istnieje
info.innerHTML += "doc.async: " + newXML.async + "<br>"; // true
}
catch(e){
info.innerHTML += "Brak obsługi obiektu ActiveX:" + "<br>";
info.innerHTML += e + "<br>"; // opis zależny od przeglądarki
info.innerHTML += e.constructor + "<br><br>"; // function TypeError() { [native code] }
}
</script>
</html>DocumentType#
Deklaracja typu dokumentu (document type declaration), w skrócie DTD lub DOCTYPE, odpowiada tylko i wyłącznie za tryby renderowania w dokumentach HTML i gdzieniegdzie może wpływać na zachowanie niektórych poleceń po stronie kodu JS (np. tych korzystających z algorytmu pobierającego listę elementów z określonymi klasami). W ramach uproszczenia dalszych opisów zakładamy, że deklaracja typu dokumentu będzie utożsamiana z:
Łańcuchem znakowym przeznaczonym bezpośrednio dla parsera HTML, jak w przypadku uproszczonego zapisu z najnowszej specyfikacji HTML5 w postaci "
<!DOCTYPE html>", który umieszczamy bezpośrednio w kodzie znacznikowym strony lub przekazujemy do odpowiedniej metody wywołującej taki parser, np.DOMParser.parseFromString(). Oto kilka uogólnionych konstrukcji składniowych dla łańcucha:<!DOCTYPE nazwa> <!DOCTYPE nazwa PUBLIC "identyfikator_publiczny"> <!DOCTYPE nazwa SYSTEM "identyfikator_systemowy"> <!DOCTYPE nazwa PUBLIC "identyfikator_publiczny" "identyfikator_systemowy">
Poszczególne specyfikacje uściślają możliwe wartości dla powyższych wariantów, i to właśnie od konkretnej postaci DTD zależy tryb renderowania w dokumentach HTML.
- Jednym z węzłów występujących w drzewie węzłów, na którym można wykonywać ogólne operacje węzłowe i który można przekazywać do metody
DOMImplementation.createDocument()tworzącej nowe dokumenty XML. Węzły typuDocumentTypebędą tworzone automatycznie na podstawie parsowanej struktury znacznikowej lub mogą być tworzone po stronie kodu JS za pomocą metodyDOMImplementation.createDocumentType(), która jest bardziej restrykcyjna od samego parsera HTML, a to ze względu na weryfikację nazwy pod kątem wymagań stawianych przez specyfikację XML.
Więcej szczegółowych informacji związanych z budową i przeznaczeniem DTD umieściłem w poprzednim kursie HTML (dział "Szkielet dokumentu - DOCTYPE") oraz kursie HTML5. W dalszej części doprecyzuję tylko te zachowania, o których warto pamiętać w trakcie tworzenia kodu JS i DOM.
Kolejny niepotrzebny rodzaj węzła#
Zdefiniowanie dodatkowego rodzaju węzła tylko i wyłącznie na potrzeby kontrolowania trybu renderowania w dokumentach HTML było nietrafionym pomysłem (podobnie zresztą jak w przypadku sekcji CDATA). Spowodowało to niepotrzebną komplikację niektórych algorytmów ze specyfikacji DOM (głównie tych związanych z modyfikowaniem drzewa węzłów), i rykoszetem odbiło się także na specyfikacji HTML. Ustawianie trybu renderowania należało wykonać w jakiś mniej inwazyjny sposób w odniesieniu do drzewa węzłów, jak ma to miejsce przy deklarowaniu kodowania w dokumencie. Prawda jest taka, że mleko się rozlało i niewiele w tej kwestii można poprawić. Oto wykaz najważniejszych prawidłowości, na które trzeba zwracać uwagę:
- Każdy dokument może mieć tylko jeden węzeł typu
DocumentTypew swoim drzewie węzłów, udostępniany pod właściwościąDocument.doctype. Umieszczenie nadmiarowych DTD spowoduje zrzucenie błędu przez parser XML lub ich całkowite zignorowanie w parserze HTML. - Deklaracja typu dokumentu może występować tylko w węźle będącym dokumentem, jako jedno z jego dzieci (zgodnie z wymogami dopuszczalnej zawartości), dlatego też najlepiej umieszczać DTD na początku struktury znacznikowej czy też drzewie węzłów, ewentualnie za komentarzami lub instrukcjami przetwarzania, ale koniecznie przed jego elementem dokumentowym (jeśli występuje). Niedostosowanie się do tych wymagań, np. poprzez umieszczenie DTD wewnątrz elementu
<body>lub za elementem<html>zaowocuje całkowitym zignorowaniem DTD w parserze HTML lub też zrzuceniem błędu przez parser XML. - Metody wstawiające węzły w konkretne miejsce drzewa węzłów, np.
Node.appendChild()czyNode.insertBefore(), są wrażliwe na wszelkie nieprawidłowości i w razie niespełnienia powyższych warunków zawsze zrzucają błąd (niezależnie od rodzaju dokumentu), co wynika z używanego przez nie algorytmu gwarantującego poprawność przed wstawieniem. - Węzły typu
DocumentTypepodlegają serializacji, dlatego niesiona przez nie informacja o ustawianym trybie renderowania w danym dokumencie HTML zostanie zachowana.
Prosty przykład:
<!-- Jakiś komentarz -->
<!DOCTYPE pierwszy! SYSTEM "Identyfikator systemowy"><!DOCTYPE html>
<!-- Kolejny komentarz -->
<html>
<script></script>
</html>Modyfikowanie trybu renderowania w dokumentach HTML#
Tryb renderowania może zostać zmieniony z wartości domyślnej (tj. z trybu bez dziwactw) jedynie w przypadku tworzenia dokumentów przez parser HTML w oparciu o obecność, nieobecność lub wartość deklaracji typu dokumentu. Można to osiągnąć chociażby poprzez bezpośrednie otworzenie jakiegoś dokumentu HTML w oknie lub karcie przeglądarki, albo poprzez skorzystanie z odpowiedniej metody tworzącej nowy dokumentu HTML po stronie JS-a, która pobierze deklarację typu dokumentu w odpowiedniej dla siebie postaci. Już po utworzeniu dokumentu HTML jego tryb renderowania nie podlega modyfikacji, zatem wstawienie do dokumentu HTML nowego węzła typu DocumentType nie spowoduje żadnego efektu.
Trzeba wyraźnie zaznaczyć, że dokumenty XML posiadają jedynie tryb bez dziwactw, i nie można tego w żaden sposób zmienić, nawet jeśli metoda DOMImplementation.createDocument() tworząca dokumenty XML pobiera argument będący deklaracją typu dokumentu. Technicznie rzecz biorąc to jedynym akceptowalnym wariantem dla tego osobliwego przypadku będzie DTD pasujące do wzorca wyrażanego łańcuchem znakowym "<!DOCTYPE nazwa>" lub "<!DOCTYPE nazwa SYSTEM 'identyfikator_systemowy'>", dla którego odpowiadający węzeł typu DocumentType zostanie utworzony, co jednak nie zmieni faktu, że wciąż nie będzie on miał żadnego wpływu na domyślny tryb renderowania tego dokumentu. Każda inna kombinacja, włącznie ze zmianą wielkości znaków w łańcuchu "DOCTYPE" lub "SYSTEM", będzie ignorowana i zrzucony zostanie błąd.
Z praktycznego punktu widzenia różne tryby renderowania to w zasadzie relikty z przeszłości. Na dobre upowszechniły się poszczególne standardy webowe (HTML i CSS), i w aktualnym kodzie produkcyjnym starsze rozwiązania po prostu nie występują. Oczywiście wyjątkiem będą sytuacje, w której ktoś świadomie pomija deklarację typu dokumentu w dokumentach HTML odpowiedzialną za ustawienie trybu bez dziwactw. Niemniej jednak, z uwagi na kompatybilność wsteczną, wytyczne dla prawidłowej obsługi historycznych trybów renderowania wciąż są opisywane przez niektóre specyfikacje.
Prosty przykład:
<script></script>DocumentFragment#
Fragment dokumentu w poprzednich specyfikacjach DOM (DOM3 i DOM2) był określany jako "lekka" lub "minimalna" postać dokumentu, chociaż z samymi obiektami dokumentów ma on niewiele wspólnego (nie dziedziczy po nich). W rzeczywistości jest to osobny rodzaj węzła, bez żadnych dodatkowych poleceń, ale ze specyficznym zachowaniem pozwalającym w wygodny sposób operować na dowolnej liczbie węzłów poza właściwym drzewem węzłów.
Trzeba wyraźnie zaznaczyć, że fragment dokumentu nie występuje bezpośrednio w drzewie węzłów (obok innych węzłów), nie można go wyprodukować za pośrednictwem parsera, a jedynymi możliwościami konstruującymi są polecenia dostępne wprost ze skryptu:
Istotną zaletą stosowania fragmentów dokumentów będzie możliwość ogólnej poprawy wydajność skryptów w obszarze DOM, szczególnie w sytuacji, kiedy zachodzi potrzeba przeprowadzenia wielu modyfikacji w aktywnym drzewie dokumentu. Nowy fragment dokumentu domyślnie znajduje się poza aktywnym drzewem dokumentu i wszelkie zmiany w nim przeprowadzane nie powodują niepotrzebnego ponownego wlewania i przemalowania w drzewie renderowania dla aktywnego drzewa dokumentu.
Oczywiście manipulowanie wieloma węzłami poza aktywnym drzewem dokumentu można wykonać na wiele sposobów. Przykładowo można samodzielnie utworzyć nowe drzewo węzłów poza drzewem dokumentu z dowolnym korzeniem (np. obiektem div), lub sklonować czy usunąć istniejący fragment aktywnego drzewa dokumentu z już wyrenderowanej części. Następnie należy przeprowadzić zmiany i na koniec z powrotem wstawić zawartość korzenia do wyrenderowanej części aktywnego drzewa dokumentu.
Operacje takie najlepiej przeprowadzać jednak za pomocą fragmentu dokumentu, który może być bezpośrednio umieszczany jako argument w metodach operujących na węzłach, takich jak Node.appendChild(), Node.replaceChild(), Node.insertBefore() i wielu innych. Każda z tych metod doda do dowolnego drzewa węzłów jedynie zawartość fragmentu dokumentu (czyli wszystkie jego dzieci), dlatego nie trzeba się nim przejmować w kontekście korzenia, gdyż on sam (jako węzeł) nie będzie dodawany do wskazywanego miejsca.
Więcej informacji oraz przykłady praktycznego stosowania fragmentów dokumentów, a także korzyści z tego wynikających w formie testów, opisał John Resig w artykule "DOM DocumentFragments".
Prosty przykład:
<!DOCTYPE html>
<title>Cat data</title>
<script>
// Data is hard-coded here, but could come from the server
var data = [
{ name: 'Pillar', color: 'Ticked Tabby', sex: 'Female (neutered)', legs: 3 },
{ name: 'Hedral', color: 'Tuxedo', sex: 'Male (neutered)', legs: 4 },
];
</script>
<table>
<thead>
<tr>
<th>Name <th>Colour <th>Sex <th>Legs
<tbody>
<template id="row">
<tr><td><td><td><td>
</template>
</table>
<script>
var template = document.querySelector('#row');
for (var i = 0; i < data.length; i += 1) {
var cat = data[i];
var clone = template.content.cloneNode(true);
var cells = clone.querySelectorAll('td');
cells[0].textContent = cat.name;
cells[1].textContent = cat.color;
cells[2].textContent = cat.sex;
cells[3].textContent = cat.legs;
template.parentNode.appendChild(clone);
}
</script>Podsumowanie#
Z opisów można wywnioskować, że język XML wymaga poznania zdecydowanie większej ilości współpracujących ze sobą technologii, chociaż język sam w sobie jest niewielki, widać to wyraźnie po minimalistycznej specyfikacji XML. Będzie on kierowany raczej dla profesjonalistów, którym HTML (a nawet XHTML) nie wystarcza. Bardzo często można zetknąć się z plikami XML w desktopowych aplikacjach, gdzie język wykorzystywany jest najczęściej do konfiguracji programów. Także w przeszłości format XML był często stosowany do wymiany informacji przez Internet (np. za pomocą Ajaxa w przeglądarkach), obecnie rolę tę przejął znacznie bardziej oszczędny JSON.
HTML w porównaniu z XML-em może wydawać się jedynie zabawką. Jest to złudne wrażenie, kolejna wersja języka, czyli HTML5, jest bardzo rozbudowana, powiązana z wieloma nowymi funkcjonalnościami. Ze względu na "zepsuty" charakter HTML-a, najnowsze specyfikacje opisujące ten język są bardzo rozwlekłe, prezentują wszystko w najdrobniejszych szczegółach, tylko po to, żeby każdy program przetwarzający obsługiwał dokumenty HTML identycznie. W większości przypadków wystarczy nam sam HTML, którego dogłębne poznanie będzie wyzwaniem nawet dla profesjonalnych programistów.