Podstawy#
Historia HTML-a#
Wprawdzie historia języka nie stanowi najważniejszej informacji przy tworzeniu stron internetowych, jednak warto się z nią zapoznać.
Początki HTML-a sięgają roku 1960, gdy IBM pracował nad systemem prezentowania i organizowania dużych ilości danych. Nazwano go wówczas GML (General Markup Language) a po latach prac, w 1978 roku przekształcono na SGML (Standard Generalized Markup Language), który okazał się być bardziej przydatny. SGML to tak zwany metajęzyk, czyli język na podstawie, którego tworzone są języki podrzędne (HTML jest właśnie takim językiem wywodzącym się z SGML-a).
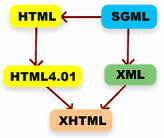
Rysunek. Rozwój (X)HTML-a
Jak wcześniej wspomniałem, twórcą języka HTML jest Tim Berners-Lee. Jego pierwsza wersja została opracowana w 1989 roku. Tim w tym czasie był fizykiem oraz konsultantem do spraw oprogramowania pracującym w Europejskim Ośrodku Badań Jądrowych CERN (Conseil Européen pour la Recherche Nucléaire) koło Genewy. Pierwotnie język składał się z kilkunastu znaczników umożliwiających wyświetlenie tekstu wraz z odsyłaczami do innych tekstów (dodanie elementu a). Rewolucyjność pomysłu polegała na tym, że użytkownik przeskakujący do innego tekstu nie musiał w ogóle wiedzieć gdzie fizycznie znajduje się interesujący go tekst. HTML miał pozwalać autorom na opis struktury dokumentu, wyróżnianie nagłówków, paragrafów, przerw, list i tabel. Sposób prezentacji zależał od programu odczytującego dokument. Była to tzw. zerowa wersja HTML-a.

Rysunek. Tim Berners-Lee
Tim Berners-Lee oprócz HTML-a stworzył również pierwszą przeglądarkę WWW (o nazwie WorldWideWeb aka Nexus), pierwszy serwer WWW, koncepcję URL i protokół HTTP. Naprawdę niezły z niego "mózg".
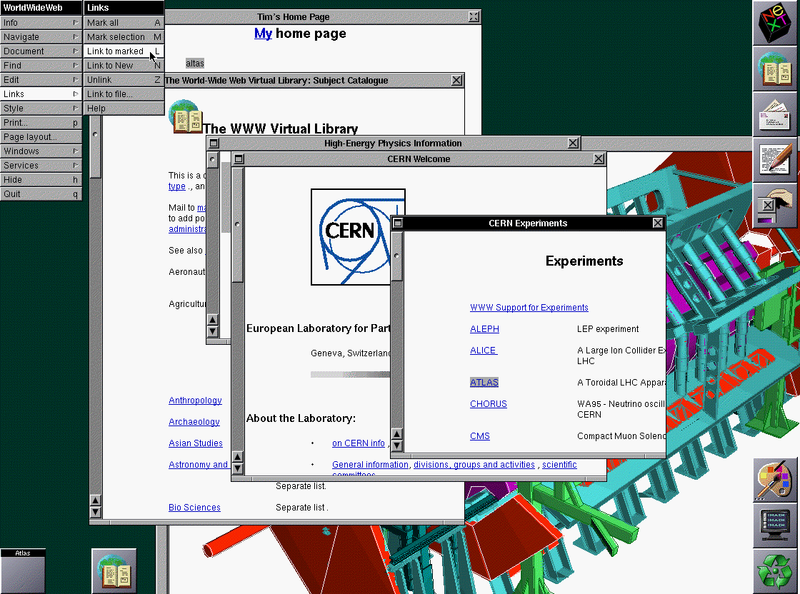
Rysunek. WorldWideWeb - pierwsza przeglądarka WWW w historii
Choć zarówno HTML jak i cała Sieć Web na nim oparta są stosunkowo nowymi technologiami, koncepcja hipertekstu jest już dość leciwa. W latach czterdziestych ubiegłego wieku Vannevar Bush w swoim artykule "As we may think" opisał komputerowy system hipertekstowy, który nazwał "memex". Innymi osobami zaangażowanymi w rozwój tej koncepcji byli Douglas Engelbart, Bill Atkinson i Ted Nelson, którego uważa się za ojca terminu "hipertekst". Jednak systemy przez nich projektowane bazowały tylko na jednym komputerze - tym, na którym działały.
Sieć WWW (World Wide Web, Web) to sieć stron WWW, po której nawiguje się za pomocą przeglądarki internetowej. Nawigacja ta sprowadza się do klikania odnośników, które łączą strony WWW. Proponowaną (zgodną z angielskim akronimem) polską nazwą dla WWW jest Wszechnica Wiedzy Wszelakiej.
Zanim jednak ukuto akronim WWW, rozważano też inne nazwy, m.in. "The Information Mesh" oraz "The Mine of Information". Niezależnie jednak od nazwy projektu, przez hipertekst rozumiano sposób łączenia informacji różnego rodzaju i dostępu do niej, w postaci sieci węzłów, które użytkownik może przeglądać podług woli i tłumaczono jego zastosowania: "hipertekst dostarcza ujednoliconego interfejsu użytkownika dla wielu dużych klas zgromadzonej informacji – raportów, notatek, baz danych, dokumentacji komputerowej i online'owych systemów pomocy".
Język HTML pomyślany jako narzędzie ułatwiające komunikowanie się naukowców w sieci szybko zyskał ogromną popularność. Przyniósł on w latach 90-tych szalony rozwój Internetu, zwłaszcza sieci WWW. Wraz z rozwojem sieci globalnej zmienił się także sam język. Z tego powodu zaistniała potrzeba stworzenia organizacji mającej na celu kontrolę nad dalszym rozwojem Sieci. W ten sposób w roku 1994 powstało W3C (World Wide Web Consortium) prowadzone i finansowane przez liderów branży informatycznej i telekomunikacyjnej. Konsorcjum nie ogranicza się jednak tylko do zadań opiniotwórczych. Zajmuje się także rozwijaniem dotychczasowych i tworzeniem całkiem nowych standardów dla WWW.

Rysunek. Logo World Wide Web Consortium (W3C)
Na dzień dzisiejszy (31.08.2009) Konsorcjum liczy sobie 355 członków. Wśród nich znaleźć możemy firmy i organizacje takie jak: Adobe Systems, Hewlett-Packard, IBM, Google, Microsoft, Macromedia i inni. Pełną listę znajdziecie na oficjalnej stronie projektu.
W 1995 roku zatwierdzono HTML 2.0, natomiast specyfikacja HTML 3.0, także z tego roku, nie doczekała się rekomendacji. W 1996 roku powstała specyfikacja HTML 3.2 (Wilbur), która uzyskała rekomendację w 1997 roku.
Wkrótce po tym pojawiły się pierwsze przeglądarki graficzne, takie jak Netscape Navigator i Internet Explorer. Ich użytkownicy zapragnęli większej liczby atrakcji, niż te oferowane w specyfikacjach. By zaspokoić potrzeby rynku, producenci zaczęli prześciga się w dodawaniu nowych możliwości do języków HTML 2 i HTML 3. Kolorowe czcionki, migające napisy, animowane obrazki... tak, to było bardzo "fascynujące". Dokumenty WWW zamieniły się w nieprzeniknioną dżunglę zagnieżdżonych tabel - po prostu nie było innego sposobu kontroli układu strony.
Wersja 4.0 (Cougar) z 1998 roku rozszerzyła możliwości języka HTML o style (CSS1), skrypty, ramki i osadzanie obiektów. Poprawiono obsługę tekstu, rozbudowano opcje tabel i formularzy wprowadzając ułatwienia dla osób niepełnosprawnych. Wprowadzono dodatkowy element DIV, który wraz ze stylami miał odseparować treść od sposobu prezentacji.
Bardzo fajny przegląd historyczny dotyczący HTML-a znajduje się na specjalnej stronie W3C. Zawarto w nim wszystkie istotne wydarzenia, które nastąpiły od 1989 do 1998 roku.
Pojawienie się nowych możliwości w języku zostało, jak można się tego było spodziewać, poważnie nadużyte przez webmasterów. Strony zaczęły być pełne tagów <div>...<div>, zdobiących niemal każdy element, który mógłby takiego zdobienia potrzebować. Tabelki znów służyły tylko do prezentacji danych tabelarycznych, jednak treść i forma prezentacji pozostały wciąż przemieszane.
W wersji 4.01, wprowadzonej 24 grudnia 1999 roku poprawiono błędy i wprowadzono drobne zmiany. W wersji Strict pozbyto się wielu znaczników, za cześć wizualną odpowiadają arkusze stylów CSS2 (Cascading Style Sheets 2). Wersje Transitional i Frameset języka dopuszczają starsze polecenia i atrybuty, ale odradza się ich wykorzystywanie.
Przeglądarki "piątej generacji", które pojawiły się w tym okresie, obok w miarę pełnej obsługi standardu CSS2 umożliwiły także łączenie własności CSS z innymi niż div elementami. Zamiast tworzyć klasę "paragraf_italika" dla warstwy div zawierającej tekst, zaczęto zamykać tekst w elemencie p i redefiniować sposób prezentacji p w powiązanym z dokumentem arkuszu stylu.
W tym samym czasie konsorcjum World Wide Web zaproponowało nowy język XHTML 1.x, który miał być językiem równoważnym HTML 4.01, ale zachowującym składnię języka XML. Jego powstanie pomogło w przenoszeniu dokumentów XML-owych do Internetu i sprawdzaniu poprawności syntaktycznej kodu za pomocą istniejących walidatorów.
Należy pamiętać, że przejście na XML nie wiązało się ze zmianą składni języka – zmienił się tylko sposób jej przedstawiania, czyli tzw. serializacja. XML jest bardziej doprecyzowany i mniej tolerancyjny od HTML-a, co sprawia, że pisanie programów go przetwarzających (tzw. parserów, czyli m.in. przeglądarek) jest łatwiejsze, a ich działanie szybsze i lepiej przewidywalne. Z drugiej strony utrudnia to trochę pracę webmasterom, ponieważ strona XHTML, w przeciwieństwie do HTML, nie może zawierać błędów – każdy błąd teoretycznie powoduje wyświetlenie w przeglądarce komunikatu o błędzie zamiast żądanej strony. Oprócz użycia serializacji XML zastosowano w niej modularyzację, co ułatwia jej rozszerzanie, jak również adaptację w przeglądarkach.
Pod nadzorem W3C zarówno HTML, jak i XHTML przyjęły swą obecną postać - HTML 4.01 oraz XHTML 1.0 (oba w wersjach Strict, Transitional, Frameset). Wydano też XHTML 1.1, który przestał być dzielony na osobne wersje (usunięto wszystkie przestarzałe polecenia i atrybuty z poprzednich specyfikacji). Od ponad dziewięciu lat standardy obu języków pozostają bez zmian.
Jak widać, w kolejnych specyfikacjach wprowadzano zmiany, których zadaniem było poprawienie przenośności dokumentów (X)HTML między różnymi platformami i przeglądarkami. Zdano sobie bowiem sprawę, że jedynie pełna kompatybilność zagwarantuje prawidłowy rozwój Internetu, a jej brak będzie oznaczał lawinę formatów, która utrudni lub wręcz uniemożliwi powszechne wykorzystanie Sieci. Wprowadzane stopniowo modyfikacje rozszerzały potencjał języka nie naruszając jego dotychczasowych możliwości. Chodziło przecież o to, aby już utworzone strony były nadal dostępne. Inne ważne kwestie, które zdecydowały o kierunku rozwoju to potrzeba umożliwienia korzystania z informacji sieciowych za pomocą rożnych urządzeń, takich jak telefony komórkowe czy komputerowe urządzenia służące do komunikacji głosowej oraz uniezależnienie się od konfiguracji sprzętowej (a więc na przykład od ustawień takich jak rozdzielczość czy głębokość barwy) i parametrów łączy sieciowych.
Tak pokrótce wygląd to co wydarzyło się w przeszłości, zostało uznane przez szerokie grono specjalistów jako standard i obowiązuje po dzień dzisiejszy. Jeśli myślisz że to koniec, jesteś w dużym błędzie. Rozwój standardów dopiero przybiera na sile, powodując większe zawirowania niż za dawnych czasów. O kolejnych pomysłach przeczytasz w następnym rozdziale.