Podstawy#
Poprawność dokumentu#
Poprawność syntaktyczna jest pierwszym krokiem w kierunku tworzenia semantycznych stron w języku (X)HTML.
Syntaktyka określa nam składnię danego języka, reguły poprawnego stosowania znaczników, atrybutów, encji.
Języki hipertekstowe są bardzo dobrze udokumentowane. Ich tworzeniem i wytyczaniem standardów zajmuje się W3C. W językach hipertekstowych istnieje dowolność jeśli chodzi o zawartość opisywaną tymi językami, ale jeśli chodzi o składnię to sprawa już jest bardziej skomplikowana. Istnieją różne języki hipertekstowe, jedne bardziej restrykcyjne, inne mniej, ale wszystkie wymagają pewnych stałych elementów i poprawnej budowy. Na ustalonych zasadach tworzenia dokumentów hipertekstowych bazują programiści tworząc przeglądarki stron WWW i roboty przeczesujące zasoby sieci.
Nikt nie jest doskonały i błędy składniowe w dokumentach internetowych popełniają najlepsi nawet webmasterzy, a cóż dopiero początkujący adepci sztuki webmasterskiej. Gdy tworzysz stronę internetową, sprawdzasz oczywiście jak wygląda w Twojej ulubionej przeglądarce. Wyświetla się? Wygląda dobrze? Nie zawiera literówek, błędów ortograficznych itp? No to OK., sprawa załatwiona. Nie oznacza to wcale, że strona pozbawiona jest błędów syntaktycznych (pomimo poprawnego wyświetlania zgodnego z naszym założeniem).
Przyjmij od razu podstawową zasadę, która uchroni Cię przed rozmaitymi problemami. Przeglądarka internetowa nie jest i nigdy nie była weryfikatorem poprawności składniowej dokumentów (X)HTML. Przeglądarki są miłosierne i wyświetlają także strony z błędami, starając się w jak największej mierze ominąć i zniwelować webmasterskie niedoskonałości. Strona może mieć i 200 błędów, a mimo to lepiej czy gorzej się wyświetli. Takie są wymogi rynku.
Skąd w takim razie biorą się te wszystkie błędy?#
Przede wszystkim z tego, że stosujemy znaczniki i atrybuty niezgodne z podaną definicją typu dokumentu DTD (Document Type Definition). Gdy zadeklarujesz wersję Strict i w znaczniku akapitu podasz atrybut align="center", walidator oczywiście zareaguje wyświetleniem błędu, mówiąc, że nie ma takiego atrybutu. Gdybyś użył deklaracji Transitional, komunikat o błędzie by się nie pojawił - a przecież chodzi nam właśnie o pisanie w zalecanym standardzie języka.
Choć zwykle korzystamy z edytorów (X)HTML, które minimalizują liczbę błędów (dlatego właśnie tak mocno podkreślam konieczność używania dedykowanych edytorów, a odradzam stosowanie zwykłego Notatnika lub jego równoważników), zdarza się, że poprawiamy ręcznie jakiś znacznik, manipulujemy przy deklaracjach stylów itd. Efektem może być choćby zwykła "literówka" albo zagubiony przecinek lub średnik, co jest wychwytywane jako błąd. Nierzadko zdarza się niedozwolone przemieszanie znaczników np.:
<b><i>Tekst pogrubiony i pochylony</b></i>Pomimo poprawnego wyświetlenia strony przez naszą przeglądarkę kod taki zawiera błędy, które wskazane zostaną przez walidatory, gdyż wg. specyfikacji (X)HTML mieszanie znaczników jest zabronione. Takie drobne uchybienia mogą owocować całą masą błędów.
Jak widać, możliwości popełnienia błędów jest wiele, zwłaszcza gdy rozminie się poziom deklaracji typu dokumentu z użytymi znacznikami. Warto im zapobiegać, sprawdzając składnię w rozmaitych narzędziach, choćby i dostępnych bezpłatnie. Postaram się wymienić i z grubsza opisać te najczęściej wykorzystywane przeze mnie.
Czy zatem musimy badać poprawność składniową?#
Nie, nie musimy - formalny przymus nie istnieje. Mamy miliony stron WWW napisanych jak to niektórzy określają po<b>a<br>anym kodem. Dlatego już na samym początku nauki warto się przyzwyczajać do kontrolowania jakości własnej pracy, bo Sieć, jej rozmaite usługi, coraz częściej faworyzuje strony napisane poprawnie, kosztem tych ułomnych. Zaprzyjaźnij się z walidatorami, choćby po to, aby mieć świadomość, na ile jesteś sprawnym webmasterem. Wprawdzie wadą walidatorów, z punktu widzenia polskiego użytkownika, jest to, że operują zwykle językiem angielskim, ale postaraj się przyjrzeć wyświetlonym komunikatom, a na pewno coś uda się dzięki nim poprawić, szczególnie te tzw. "głupie błędy".
Walidator (X)HTML w World Wide Web Consortium#
Walidator W3C, czyli W3C Markup Validation Service, to podstawowe narzędzie, które pomoże nam tworzyć poprawne konstrukcyjnie strony. Walidator jest internetową bramą do znanego parsera SGML o nazwie SP. SP pobiera nasz kod i porównuje go z obiektowymi regułami składni nazwanymi DTD. Pamiętaj, że poprawne przejście walidacji nie gwarantuje prawidłowego działania Twoich stron we wszystkich przeglądarkach. Większość z nich nie jest kompatybilna w 100% i być może będziesz musiał znaleźć alternatywne drogi osiągnięcia celu.
W3C Markup Validation Service nie generuje komunikatów o błędach - są one wszystkie generowanego przez Parser. Jego rolą jest dodanie krótkich wyjaśnień i zaproponowanie poprawek dla każdego błędu.
Tradycyjny sposób wykorzystania tego walidatora polega na uruchomieniu serwisu W3C i sprawdzeniu dokumentu na jeden z trzech możliwych sposobów:
- Validate by URI - sprawdzenie przez podanie adresu sieciowego prowadzącego do strony po wciśnięciu przycisku Check.
- Validate by File Upload - sprawdzenie przez wczytanie z dysku dokumentu HTML (przycisk Przeglądaj) i kliknięciu przycisku Check.
- Validate by Direct Input - sprawdzanie poprzez wklejenie do pola całego kodu źródłowego dokumentu, łącznie z deklaracją Doctype i kliknięciu przycisku Check.
W każdym z wyżej wymienionych sposobów możemy ustawić kilka dodatkowych opcja jak:
- Character Encoding - wybór kodowania znaków w dokumencie (jeśli nie zostało określone). Domyślnie kodowanie jest rozpoznawane automatycznie.
- Document Type - typ dokumentu, a dokładniej języka użytego do jego tworzenia. Standardowo jest rozpoznawany automatycznie, jednak jeśli typ nie został zdefiniowany w dokumencie należy wybrać jeden z listy.
- List Messages Sequentially - lista wiadomości wyświetlona zostanie sekwencyjnie.
- Group Error Messages by Type - wiadomości dotyczące błędów zostaną pogrupowane według typu.
- Show Source - pokazuje źródło sprawdzanego dokumentu.
- Show Outline - generuje i sprawdza drzewo logiczne dokumentu. Dzięki tej opcji można zobaczyć między innymi czy prawidłowo zostały zastosowane nagłówki (
<h1>...<h6>) z odpowiednimi poziomami. - Validate error pages - sprawdzenie również tych stron, dla których kod stanu HTTP wskazuje błąd (np. 404).
- Verbose Output - opcja powoduje, że wyniki pracy walidatora będą opisane obszerniej.
Bardziej szczegółowy opis każdej opcji znaleźć można w serwisie W3C, niestety tylko po angielsku.
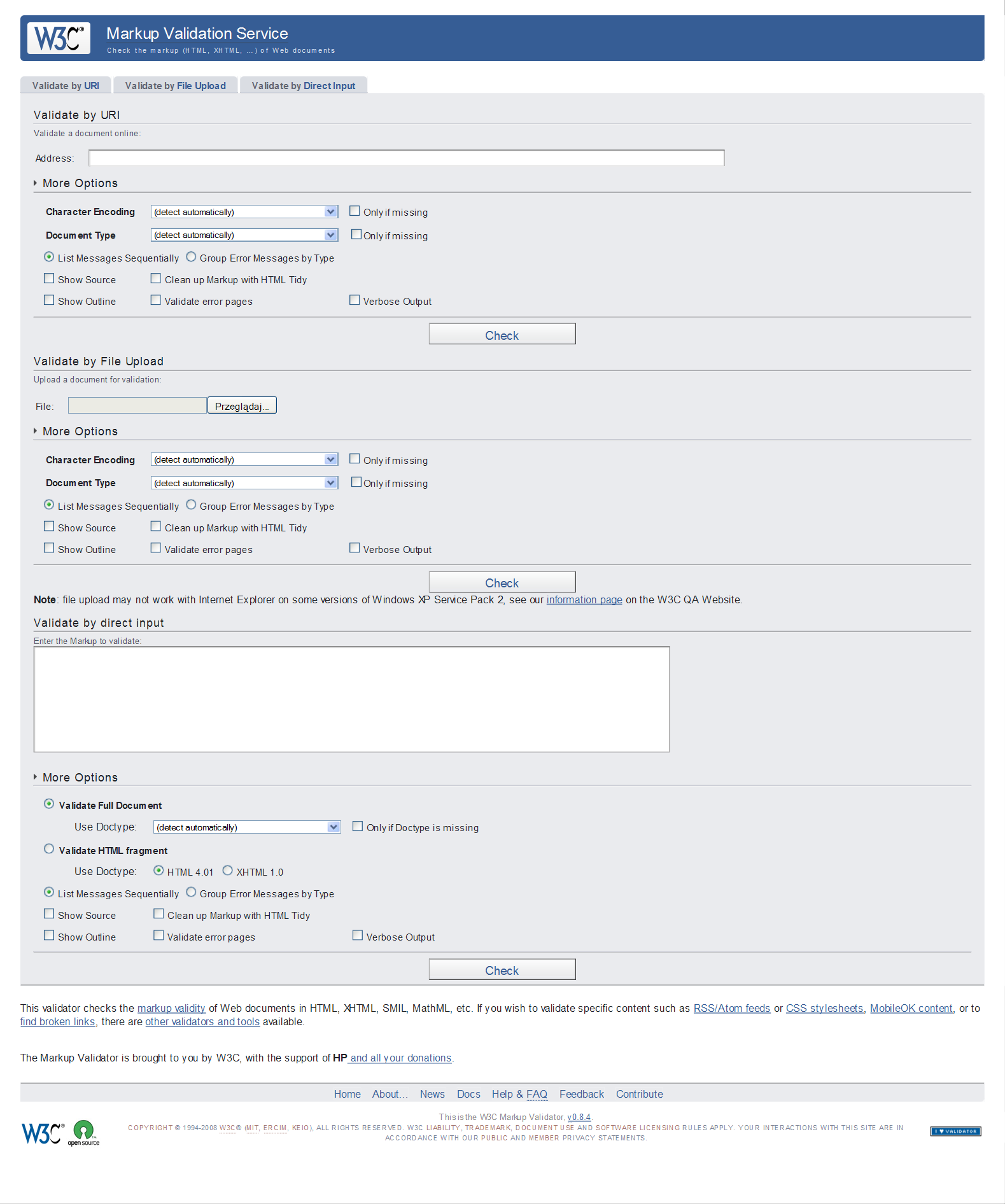
Rysunek. W3C Markup Validation Services - ekran roboczy
To był sposób wykorzystania walidatora W3C bezpośrednio z witryny, cały proces możesz przyspieszyć stosując odpowiednie rozszerzenia przeglądarek lub przeglądarki mające wbudowane mechanizmy walidacji kodu.
Jeśli korzystasz z przeglądarki Opera, to niezależnie od tego, czy sprawdzasz dokument znajdujący się w Sieci, czy też na swoim lokalnym dysku, możesz wybrać polecenie Sprawdź poprawność (skrót klawiaturowy Ctrl+Alt+Shift+U) w menu kontekstowym myszy, pod prawym klawiszem.
W przypadku przeglądarki Firefoksa konieczna jest instalacja rozszerzenia Web Developer (w polskiej wersji językowej). Następnie wybierz polecenie Narzędzia - Validate HTML (skrót klawiaturowy Ctrl+Shift+H) lub też, jeśli walidujesz lokalny plik na dysku, polecenie Narzędzia - Sprawdź poprawność lokalnego HTML (skrót klawiaturowy Ctrl+Shift+A).
Podobnie sytuacja wygląda w przypadku przeglądarki Internet Explorer, zainstaluj rozszerzenie Internet Explorer Developer Toolbar. Dla sprawdzenia poprawności dokumentu wybierz polecenie Validate - HTML dla pliku online lub Validate - Local HTML dla pliku lokalnego.
Walidacja i interpretacja jej wyników#
Walidacja jest procesem, którego wynik może być dwojaki: strona waliduje się (nie zawiera błędów) lub strona nie waliduje się. Nie można wyróżnić żadnych wartości pośrednich typu "strona prawie waliduje się". Dlatego należy zawsze doprowadzać do stanu, w którym strona się waliduje - liczba błędów musi być równa zero. Co prawda, są sytuacje, w których walidator, jak każdy program, zawodzi, ale zdarzają się one niezmiernie rzadko.
Istnieje tylko jeden przypadek dokumentu warunkowo poprawnego. Występuje, kiedy w dokumencie nie określono typu dokumentu lub kodowania. W takim przypadku walidator przyjmuje wartości domyślne. Oczywiście można je zmienić, ale to nie jest sednem sprawy. Jeśli dokument nie zawiera innych błędów poza tymi dwoma brakami to jest on poprawny warunkowo (Tentatively Valid). Oczywiście nie można na tym poprzestać. Należy uzupełnić braki by móc cieszyć się pełną zgodnością.
Po wyświetleniu wyników walidacji pozostaje już tylko przyjrzeć się podanym komunikatom (errors - błędy, warnings - ostrzeżenia) i spróbować poprawić usterki zgodnie z sugestiami walidatora, który dokładnie opisze co jest przyczyną problemu, a nawet podpowie jak można się pozbyć tego błędu.
Poprawianie kodu zaczynaj zawsze od błędów podanych w pierwszej kolejności, gdyż poprawianie omyłki na początkowym etapie może niekiedy owocować zniknięciem wielu błędów znajdujących się dalej.
Gdy uporasz się z błędami, czyli strona będzie zgodna z zadeklarowaną wersją Doctype, walidator proponuje wklejenie kodu na stronę. Kod ten wyświetla logo z informacją o zgodności oraz stanowi odnośnik do wyników walidacji twojego dokumentu. Przyjrzyj się stopce mojej witryny, widnieją w niej dwa obrazki wskazujące na poprawność syntaktyczną.
Przykładowy kod:
<p>
<a href="http://validator.w3.org/check?uri=referer"><img
src="http://www.w3.org/Icons/valid-xhtml11"
alt="Valid XHTML 1.1" height="31" width="88" /></a>
</p>Efekt:
Czytelnik strony może kliknąć wyświetloną ikonkę W3C, aby dokonać sprawdzenia, czy rzeczywiście tak jest. Ale, uwaga, w niektórych środowiskach w Internecie "pochwalenie się" taką ikonką jest uważane za objaw złego gustu lub zbyteczny szpan, co oczywiście wcale nie musi być prawdą. Tak więc wybór należy do Ciebie, autora strony. Osobiście na miejscu krytyków nie byłbym tak radykalny. Mam tu na myśli strony z faktycznie poprawnym kodem. Ostatnio widuje szereg witryn ze wstawkami zgodności W3C, niestety większość z nich jest na bakier z poprawnością składniową.
Najczęściej popełniane błędy przez webmasterów#
Przy "kodzeniu" strony błędów można popełnić mnóstwo, jednak wśród twórców stron jest kilkanaście błędów na tyle popularnych, że można je uznać za plagę. Oto one:
- No document type declaration; implying "<!DOCTYPE HTML SYSTEM>"
- Walidator nie znalazł w dokumencie definicji jego typu, czyli tak zwanego Doctype. Linijka ta jest wymagana i służy między innymi do poinformowania przeglądarki oraz samego walidatora z jakim typem dokumentu ma styczność i jak powinien być on interpretowany. W przypadku nie odnalezienia tej linijki walidator stosuje własną definicję (system).
- Required attribute "TYPE" not specified / Required attribute "ALT" not specified
- Nie został określony atrybut, który jest wymagany w znaczniku. W znaczniku
<script />należy określić typ MIME skryptu właśnie stosując atrybuttype. W znaczniku<img />należy wpisać tekst alternatywny (taki, który pojawi się zamiast obrazka, jeśli on się nie załaduje). Tekst ten powinien być umieszczony w atrybuciealt. - Document type does not allow element "LINK" here
- Znacznik, w tym wypadku
<link />został umieszczony w nieodpowiednim miejscu w dokumencie. Najczęściej bywa tak, jeśli (tak jak tutaj) używamy tego znacznika poza sekcją head dokumentu lub wstawiamy element blokowy do elementu liniowego. - There is no attribute "BORDERCOLOR"
- W definicji typu dokumentu nie ma takiego atrybuty w opcjach znacznika. Czasami jest to literówka, a czasami, tak jak tutaj, niestandardowe rozszerzenie jednego z producentów przeglądarek.
- End tag for "HEAD" which is not finished
- Walidator nie spodziewał się zakończenia sekcji head. Najczęstszym powodem wygenerowania takiego komunikatu jest brak tagu
<title />lub jego umiejscowienie poza tą sekcją. Walidator niestety nie mówi tego wprost, ale można wywnioskować to z definicji typu dokumentu, w której jest napisane, że sekcja head wymaga, aby był w niej umieszczony znacznik<title />. Analogiczna sytuacja jest w przypadku innych tagów, które wymagają obecności innych znaczników jak na przykład<html />, który wymaga w sobie znaczników<head />i<body />. - Element "ZNACZNIK" undefined
- W definicji typu dokumentu nie ma zdefiniowanego znacznika o takiej nazwie.
- End tag for "br" omitted, but OMITTAG NO was specified / End tag for "DIV" omitted, but its declaration does not permit this
- Nie znaleziono znacznika kończącego otwarty tag. W definicji typu dokumentu określono, że ten znacznik nie może pozostać otwarty.
- Start tag was here
- W połączeniu z poprzednim błędem, komunikat ten sygnalizuje krzyżowanie znaczników (np.
<a><b>...</a></b>). - End tag for element "TD" which is not open
- Walidator znalazł znacznik zamykający, ale nie znalazł odpowiadającego znacznika otwierającego. Nie zawsze oznacza to, że znacznik nie został otwarty. Po prostu znacznik otwierający mógł zostać zamknięty przez inny znacznik (odpowiadający, w założeniu autora innemu, ale w drzewie dokumentu odpowiadający innemu znacznikowi). Pojawienie się takiego komunikatu informuje, że w kodzie czegoś zapomniano, a jak wiadomo jeden błąd może lawinowo wygenerować inne. Taka sytuacja szczególnie często zdarza się podczas tworzenia tabel.
- ID "IDENTYFIKATOR" first defined here / ID "IDENTYFIKATOR" already defined
- Identyfikator, z założenia unikalny w dokumencie, został przypisany więcej niż jednemu obiektowi . Może warto skorzystać z klas?
- An attribute value must be a literal unless it contains only name characters / An attribute value specification must be an attribute value literal unless SHORTTAG YES is specified
- Pod tym, jakże skomplikowanym opisem błędu, kryje się informacja o tym, że wartość atrybutu powinna być ujęta w cudzysłowy (a właściwie symbole cala - "...").
- Reference to entity "opcja" for which no system identifier could be generated / Entity was defined here
- Nie istnieje encja
&opcja;, która została użyta. Problem ten najczęściej występuje podczas zapisu skomplikowanych linków w których pojawia się znak & (ampersand). Każdy taki znak w linku należy zapisać wykorzystując encję&. - Value of attribute "ID" invalid: "1" cannot start a name
- Nazwa identyfikatora nie może zaczynać się cyfrą, musi to być litera.
To była garstka błędów z którymi możesz się spotkać. Co prawda informacje podawane przez walidator są po angielsku, ale nie powinno być problemu z ich poprawną interpretacją.
A tutaj masz stronę testową # napisaną celowo z błędami. Sprawdź jej poprawność w walidatorze World Wide Web Consortium i przeczytaj wyświetlone komunikaty o błędach.
Kilka poważnych błędów samego walidatora#
Walidator W3C, jak każdy program nie jest pozbawiony błędów (bugs) i niedoskonałości. Nigdy nie można być w stu procentach pewnym jego działania. Dość często walidatorowi zdarza się informować o błędzie, którego tak naprawdę nie ma w tym miejscu, w którym walidator go upatruje. Jest on spowodowany innym błędem, który oddziaływuje na tę część kodu, na którą zwrócił uwagę walidator.
Opiszę teraz kilka podstawowych błędów, których walidator W3C nie jest w stanie wychwycić:
- Sprawdzanie poprawności dokumentów XHTML (Strict, 1.1) już na samym początku jest spalone. Specyfikacja tego języka jasno mówi, że dokumenty powinny być serwowane z odpowiednim typem MIME, najlepiej
application/xhtml+xml. Typtext/htmldomyślnie serwowany na wszystkich serwerach WWW jest nieodpowiedni. Niestety większość dokumentów zadeklarowanych jako XHTML wysyłanych jest ze starszym typem. XHTML słany jakotext/htmlnie jest interpretowany przez przeglądarkę jako XHTML, a jako HTML, który zawiera błędy składniowe. Walidator W3C nam tego nie powie. - W poprawnym XHTML-u używanie komentarzy
<!-- -->wewnątrz<script>i<style>jest niedozwolone. Przeglądarki mają prawo usunąć z dokumentów wszystkie komentarze (wraz z zawartością). Walidator W3C tego nie sprawdza. - XTHML nie akceptuje poleceń
document.write,element.innerHTML, ani podobnych. Sposób działania parserów XML wyklucza pierwsze i komplikuje drugie. Walidator W3C tego nie sprawdza. - Istnieje wiele konstrukcji, które się walidują, ale są niepoprawnym HTML/XHTML, np.
<a><b><a></a></b></a>jest nielegalne wg. specyfikacji, niestety walidator tego nie potwierdza.
Znany jest również sposób na oszukanie walidatora wpisując nieistniejące tagi na stronę przy pomocy JavaScript.
Jak wynika z powyższej listy, przy pisaniu XHTML-em nie można polegać tylko i wyłącznie na Walidatorze W3C z powodu jego licznych poważnych błędów, niedoróbek i braków. Walidator wyszukuje XHTML-a w treści dokumentu, choć żadna przeglądarka tego nie robi (ponieważ otrzymuje pliki z nieodpowiednim MIME Type).
Pozostałe mniej znane walidatory (X)HTML#
Jak widzisz walidator W3C ideałem nie jest. Do sprawdzenia poprawności dokumentu wykorzystuje reguły zapisane w DTD. Problem w tym, że DTD nie wyraża w pełni specyfikacji (X)HTML. Wiele konstrukcji posiada błędnych, niezgodnych ze specyfikacją (sprawdź <a><em><a/></em></a>).
Istnieją dużo lepsze schematy opisu dokumentu (XML Schema, RelaxNG) i bazujące na nich bardziej czepialskie walidatory. Oto kilka przykładów z których dodatkowo powinieneś skorzystać:
Niestety żaden z nich nie sprawdza sposobu wysyłania dokumentu, więc wszystkie zaakceptują "oslashowaną tagzupę".
Wszystkie wymienione wyżej metody polegały na sprawdzeniu dokumentów metodą Online. Poprawność składniową równie dobrze możemy sprawdzić bezpośrednio z dysku lokalnego, nie korzystając z Internetu. Wiele edytorów (m.in. Pajączek, CoreEditor i kED) posiada wbudowane mechanizmy walidacji np. Tidy. Jest to opensource'owy program Dave'a Raggetta walidujący kod HTML i XHTML, działający osobno i mogący współpracować z rozmaitymi aplikacjami. Cały proces sprawdzania jest zależny od używanego oprogramowania, dlatego nie ma sensu opisywać jego przebiegu.
Dużo większe możliwości posiada CSE HTML Validator Lite dla środowiska Windows. Jest to bezpłatny program firmy AI Internet Solutions - "młodszy brat" komercyjnego programu CSE HTML Validator. Po zainstalowaniu programu w menu kontekstowym myszy (pod prawym klawiszem) w Eksploratorze Windows pojawiają się dwa polecenia aktywizowane jeszcze w trakcie instalacji - Edit with CSE HTML Validator Lite oraz Validate using CSE HTML Validator Lite. To drugie polecenie powoduje sprawdzenie dokumentu i wyświetlenie wyników w Notatniku, natomiast to pierwsze uruchamia sam program. W programie możliwe jest także sprawdzenie CSS, JS, PHP, linków, dostępności i wiele innych. Z samego walidatora możemy skorzystać Online.
Wymuszenie typu application/xhtml+xml dla XHTML-a#
Uważam to za najdokładniejszy sposób sprawdzenia poprawności syntaktycznej tworzonego dokumentu. Wymuszenie odpowiedniego typu powoduje, że w przypadku popełnienia choćby jednego błędu strona po prostu się nie wyświetli. Dla mnie takie podejście powinno być standardem, jeśli coś jest napisane niepoprawnie w ogóle nie powinno pojawić się w Sieci. Niestety rzeczywistość jest inna, masa "bubli" zalewa WWW.
Wymuszenie odpowiedniego MIME wcale nie jest takie łatwe. Domyślnie wszystkie serwery wysyłają w nagłówkach odpowiedzi protokołu HTTP typ text/html. Żeby poprawnie ustawić typ z poziomu PHP trzeba dodać parę linijek kodu, a dla statycznych plików użyć mod_rewrite (musimy mieć odpowiednie uprawnienia, z tym bywa różnie). W ostateczności pozostaje użycie rozszerzenia pliku .xhtml. Szczegółowy opis sposobów jak tego dokonać opiszę w dziale poświęconym językowi XHTML.
Pisząc strony często popełniamy głupie błędy np.: niedomknięty znacznik, przemieszane tagi, stosowanie wycofanych elementów. By nie być gołosłownym zamieszczę po przykładzie dla Firefoksa, Opery i Chrome (Microsoft Internet Explorer do wersji 8 włącznie kompletnie nie wspiera XHTML-a). Przykładowo:
<em><strong>Ważny tekst, jednocześnie niepoprawny składniowo</em></strong>Podając przeglądarce plik z typem application/xhtml+xml od razu poinformowani zostaniemy o błędach, bez konieczności korzystania z zewnętrznych walidatorów. Parser XML samej przeglądarki wyręczy nas z tego, strona nie zostanie w ogóle wyświetlona. Dodatkowo wskaże nam, w którym miejscu popełniliśmy błąd i podpowie jak go rozwiązać.
W przypadku Opery będzie to wyglądało jak na poniższej ilustracji. W najnowszej wersji 10.x otrzymaliśmy odświeżoną formę prezentacji błędów. Teraz możemy ponownie wczytać stronę traktując ją jak najzwyklejszy plik HTML (MIME text/html).
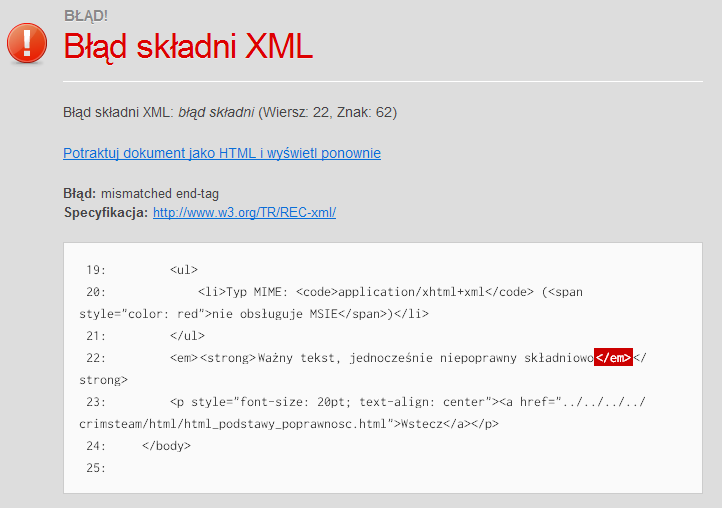
Rysunek. Błąd parsowania XML w przeglądarce Opera
Podobnie Firefox zasygnalizuje nam o wystąpieniu błędu w strukturze dokumentu, zrobi to w nieco odmienny sposób.

Rysunek. Błąd parsowania XML w przeglądarce Firefox
Nawet Google wzięło sobie do serca standard XML i w przeglądarce Chrome także zobaczymy odpowiedni komunikat. Chociaż w tym przypadku strona wyświetlona zostaje do wystąpienia pierwszego błędu.

Rysunek. Błąd parsowania XML w przeglądarce Chrome
Możesz oczywiście samemu przetestować błędnie napisaną stronę testową # w dowolnej przeglądarce obsługującej typ application/xhtml+xml.
Metoda dobra, niestety jak w przypadku pozostałych nie zagwarantuje nam stuprocentowej zgodności ze specyfikacją XHTML. Wina leży po stronie producentów przeglądarek. Istnieją elementy i atrybuty, które zgodnie ze specyfikacją są wycofane a w przeglądarkach wciąż obsługiwane - pomimo wymuszenia application/xhtml+xml. Przykładem może być align, font lub center, spójrz na stronę testową #.
Walidator CSS w World Wide Web Consortium#
Nie tylko kod HTML czy XHTML można sprawdzać w walidatorze, ale i kod arkuszy stylów. Najważniejszym narzędziem tego typu jest W3C CSS Validation Service. Dużym plusem jest jego całkowite spolszczenie.
Sposób użycia jest analogiczny jak w przypadku W3C Markup Validation Service. Kod CSS możemy sprawdzić na jeden z trzech możliwych sposobów:
- Validate by URI - sprawdzenie przez podanie adresu sieciowego prowadzącego do strony (z dowiązanym arkuszem lub samego arkusza CSS) i wciśnięcie przycisku Check.
- Validate by File Upload - sprawdzenie przez wczytanie pliku CSS z dysku (przycisk Przeglądaj) i kliknięcie przycisku Check.
- Validate by Direct Input - sprawdzanie poprzez wklejenie do pola całego kodu źródłowego arkusza stylów i kliknięcie przycisku Check.
Dodatkowo w każdej z wyżej wymienionych metod możemy ustawić kilka dodatkowych opcji jak: wersja CSS, rodzaj medium wyjściowego (dźwiękowe, braille, TV, ekran itp.) oraz rodzaj generowanych ostrzeżeń.
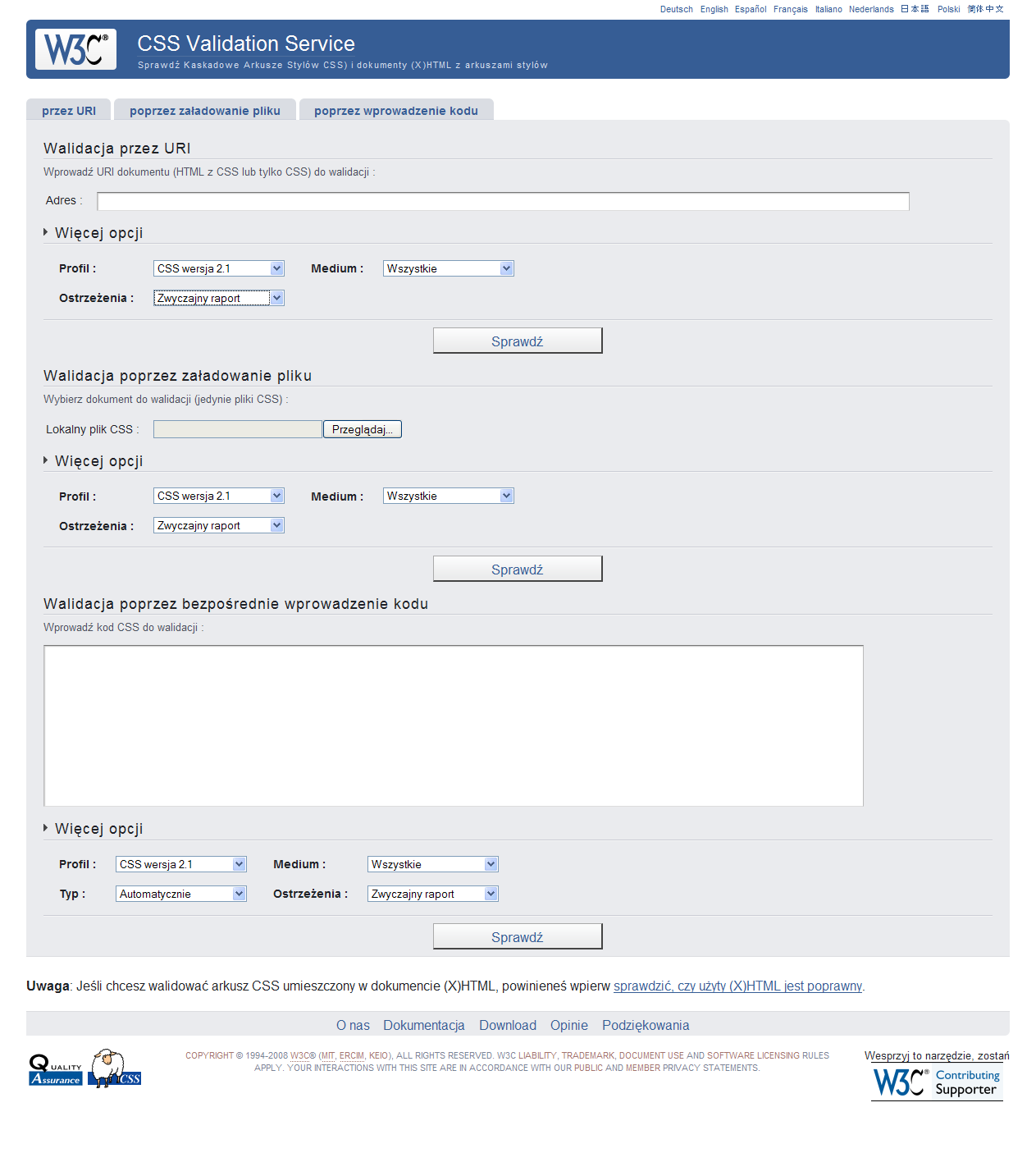
Rysunek. W3C CSS Validation Service - ekran roboczy
To był sposób wykorzystania walidatora W3C bezpośrednio z witryny, cały proces możesz przyspieszyć stosując odpowiednie rozszerzenia przeglądarek.
W przypadku przeglądarki Firefoksa konieczna jest instalacja rozszerzenia Web Developer (w polskiej wersji językowej). Następnie wybierz polecenie Narzędzia - Validate CSS lub też, jeśli walidujesz lokalny plik na dysku, polecenie Narzędzia - Sprawdź poprawność lokalnego CSS.
Podobnie sytuacja wygląda w przypadku przeglądarki Internet Explorer, zainstaluj rozszerzenie Internet Explorer Developer Toolbar. Dla sprawdzenia poprawności stylów wybierz polecenie Validate - CSS dla pliku online lub Validate - Local CSS dla pliku lokalnego.
Niestety Opera nie ma możliwości automatycznego skorzystania z serwisu W3C w przypadku CSS, pozostaje metoda tradycyjna - wykorzystanie adresu sieciowego.
Po wyświetleniu wyników walidacji pozostaje już tylko przyjrzeć się podanym komunikatom (błędy, ostrzeżenia) i spróbować poprawić usterki zgodnie z sugestiami walidatora, który dokładnie opisze co jest przyczyną problemu.
Gdy uporasz się z błędami, czyli strona będzie zgodna z zadeklarowaną wersją CSS, walidator proponuje wklejenie kodu na stronę. Kod ten wyświetla logo z informacją o zgodności oraz stanowi odnośnik do wyników walidacji twojego dokumentu. Przykładowy kod:
<p>
<a href="http://jigsaw.w3.org/css-validator/">
<img style="border:0;width:88px;height:31px"
src="http://www.w3.org/Icons/valid-xhtml11"
alt="Poprawny CSS!" />
</a>
</p>Efekt:

Podsumowanie#
Istnieje wiele narzędzi do sprawdzania poprawności syntaktycznej dokumentów tworzonych przy użyciu różnych języków znacznikowych. Niestety idealnych rozwiązań nie ma. Samego sprawdzania nigdy za wiele, a współpraca z walidatorami tego typu znakomicie rozwija webmasterskie "czucie" i umiejętność dostrzegania uchybień. W miarę swoich możliwości postaraj się sprawdzać poprawność tworzonego przez siebie kodu na wszelkie, dostępne sposoby.
Z drugiej strony nie traktuj oprogramowania jak wyroczni ostatecznych. Wiele z nich zawiera błędy. W razie wątpliwości właściwymi referencjami odnośnie języków znacznikowych są specyfikacje rekomendowane przez W3C.