Podstawy#
Zakresy#
Zakres (range) oferuje bardzo ciekawy sposób na wybieranie pewnej części drzewa węzłów, która znajdować się będzie między dwoma charakterystycznymi punktami. Na tak wybranym fragmencie udostępniono szereg interesujących operacji.
Zakresy przydają się w chwili, kiedy regularne manipulacje drzewem węzłów (za pomocą standardowych metod i właściwości) nie są wystarczająco precyzyjne, aby je łatwo zastosować.
Zamiast terminu "zakres" można używać zamiennie "zasięg", "rozpiętość" czy "zestaw". Ja osobiście stosuję jedynie "zakres", a termin "zasięg" specjalnie pomijam, żeby nie wprowadzać zamieszania z zasięgami w JavaScripcie (scope).
W przeszłości zakresy definiowane były w osobnej specyfikacji DOM Level 2 Traversal and Range (W3C). Obecnie zostały całkowicie przeniesione do DOM4 z pewnymi modyfikacjami.
Stosowanie zakresów może być nieco trudniejsze niż używanie interfejsów NodeIterator lub TreeWalker. Wynika to z faktu, że zakres (jego punkty graniczne) mogą zawierać w sobie jedynie pewną część węzłów, nawet nieciągłą, przez co algorytmy operujące na takiej zawartości są zazwyczaj bardzo rozbudowane, żeby ewentualne zmiany lub zwracane wyniki nie zaburzały poprawności drzewa węzłów.
W pigułce#
Z zakresami związanych jest wiele określeń. Żeby nie zmuszać czytelników do ciągłego przeszukiwania treści (zakładając że lekturę mają już za sobą), zamieszczam na samym początku jeden wykaz graficzny z tabelkowym objaśnieniem dla każdego terminu w kilku zakresach.
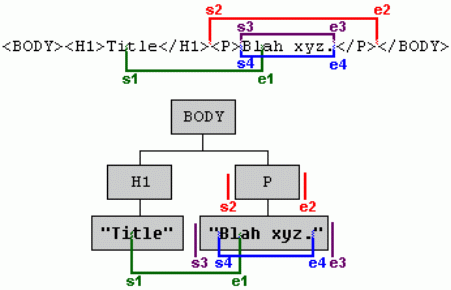
Rysunek. Drzewo węzłów z kilkoma zakresam
| Zakres | Początek (s) | Koniec (e) | ||
|---|---|---|---|---|
| Węzeł początkowy (Node) | Przesunięcie początkowe (Offset) | Węzeł końcowy (Node) | Przesunięcie końcowe (Offset) | |
| s1 ----- e1 | Text1 | 2 | Text2 | 2 |
| s2 ----- e2 | BODY | 1 | BODY | 2 |
| s3 ----- e3 | P | 0 | P | 1 |
| s4 ----- e4 | Text2 | 0 | Text2 | 9 |
Wystarczy spojrzeć na drzewo węzłów (grafika) oraz opisy w tabelce i wszystko powinno wydawać się jasne (sposób wybierania zawartości za pomocą węzłów i przesunięć). W dalszej części pokrótce opiszę trochę podstaw, żeby nawet początkujący szybciej opanowali mechanizmy rządzące zakresami.
Definicje#
Każdy zakres składa się z dwóch punktów granicznych. Z racji tego, że są tylko dwa, to pierwszy określa się początkiem a drugi końcem zakresu. Między początkiem i końcem znajduje się jego zawartość.
Sam punkt graniczny (początek lub koniec) charakteryzowany jest przez dwie cechy: węzeł oraz przesunięcie, co można zapisać krotką (node, offset). Oczywiście początek ma swój węzeł i przesunięcie (nazywane węzłem początkowym i przesunięciem początkowym), także koniec ma swój węzeł i przesunięcie (nazywane węzłem końcowym i przesunięciem końcowym).
Weźmy na warsztat prostą strukturę znacznikową:
<div>
Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>Wybieranie węzłów w punktach granicznych nie stanowi problemu. Sytuacja ulega komplikacji w przypadku ustawiania przesunięć, ponieważ ich znaczenie będzie zależne od długości w węźle, która sama zależy od rodzaju węzła. Generalnie rzecz biorąc, przesunięcie w punkcie granicznym będzie między zerem a długością węzła w punkcie granicznym, włącznie.
Tak naprawdę istotne jest to, że w przypadku węzłów o charakterze tekstowym (tj. dla węzłów tekstowych, węzłów komentarzowych, instrukcji przetwarzania) przesunięcie ustawiane jest między znakami w danych tekstowych węzła, natomiast w przypadku innych węzłów przesunięcie dotyczy dzieci tych węzłów (bez uwzględniania dalszych potomków).
We wszystkich poniższych przykładach węzły tekstowe wynikające ze stosowania białych znaków (np. nowej linii), które wstawiono by poprawić czytelność kodu HTML, będą pomijane przy analizie.
Załóżmy, że chcemy wybrać całą zawartość w elemencie DIV, co można zrobić w następujący sposób (między czerwonymi znakami || reprezentującymi punkty graniczne znajduje się zawartość zakresu):
<!-- Początek (DIV, 0) -->
<!-- Koniec (DIV, DIV.length) -->
<div>
<nocode style="color: red">|</nocode>Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.|
</div>Węzeł początkowy i końcowy ustawiliśmy na DIV, przesunięcie początkowe na 0 (czyli przed pierwszym dzieckiem DIV), natomiast przesunięcie końcowe na DIV.length (czyli za ostatnim dzieckiem w DIV).
Jeśli chcielibyśmy teraz wybrać cały pierwszy akapit, to można to zrobić w następujący sposób:
<!-- Początek (DIV, 1) -->
<!-- Koniec (DIV, 2) -->
<div>
Pierwszy blok tekstowy w DIV.
|<p>Tekst w <em>P1</em>.</p>|
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>Teraz przesunięcie początkowe ma wartość 1 (znajduje się za pierwszym dzieckiem w DIV, czyli przed drugim dzieckiem, którym jest nasz akapit), natomiast przesunięcie końcowe ma wartość 2 (znajduje się za drugim dzieckiem w DIV, którym jest nasz akapit, czyli przed trzecim dzieckiem).
Warto nadmienić, że przesunięcie w przypadku takich węzłów może operować jedynie na dzieciach węzła początkowego/końcowego, czyli w naszym przykładzie bezpośrednio z poziomu DIV nie da się zaznaczyć całego elementu EM (który jest jego dalszym potomkiem, ale nie dzieckiem). Musimy zmienić węzły w punktach granicznych na bezpośrednie odwołania lub zastosować odpowiednie właściwości na DIV:
<!-- Początek (P1, 1) lub Początek (DIV.firstElementChild, 1) -->
<!-- Koniec (P1, 2) lub Początek (DIV.firstElementChild, 2) -->
<div>
Pierwszy blok tekstowy w DIV.
<p>Tekst w |<em>P1</em>|.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>I tutaj pojawia się jedna z pierwszych cech zakresów, tj. węzły początkowe i końcowe nigdy nie są w nich zawarte, co można zaobserwować na powyższych przykładach.
Przeanalizujmy teraz węzły tekstowe. Załóżmy, że chcemy wybrać słowo "Pierwszy" z węzła tekstowego o danych "Pierwszy blok tekstowy w DIV":
<!-- Początek (DIV.firstChild, 0) -->
<!-- Koniec (DIV.firstChild, 8) -->
<div>
|</nocode>Pierwszy<nocode style="color: red">| blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>Ustawiliśmy węzeł początkowy i końcowy na pierwszy węzeł tekstowy w DIV (polecenie DIV.firstChild), przesunięcie początkowe na wartość 0 (czyli przed pierwszym znakiem w danych tekstowych węzła początkowego), natomiast przesunięcie końcowe na 8 (czyli za ósmym znakiem w danych tekstowych węzła końcowego, przed dziewiątym znakiem).
W przypadku węzłów o charakterze tekstowym, spełniających rolę węzłów początkowych/końcowych w zakresie, one także nie są zawarte w zakresie, chociaż pewna część ich danych tekstowych będzie wybierana. To jest właśnie ta różnica znaczenia przesunięć w zakresach, kiedy operujemy na różnych rodzajach węzłów, należy o tym pamiętać.
Oczywiście można rozciągać zakres na różne sposoby:
<!-- Początek (DIV.firstChild, 8) -->
<!-- Koniec (DIV.lastChild, 5) -->
<div>
Pierwszy| blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi| blok tekstowy w DIV.
</div>Teraz zawartość zakresu zawiera dane tekstowe za "Pierszy", plus cała struktura znacznikowa pomiędzy, plus dane tekstowe "Drugi".
Jeśli początek i koniec w zakresie mają takie same węzły i przesunięcia, to mówimy, że zakres jest zwinięty. W takiej sytuacji zakres nie będzie zawierał żadnej zawartości:
<!-- Początek (DIV, 0) -->
<!-- Koniec (DIV, 0) -->
<div>
|<nocode style="color: red">|</nocode>Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>Ciągłość#
Zakres nie musi być ciągły (continuous), tzn. węzeł początkowy nie musi mieć takiego samego przodka obejmującego, co węzeł końcowy, dlatego też wprowadzono specjalne pojęcie węzła częściowo zawartego:
<!-- Początek (DIV, 0) -->
<!-- Koniec (UL, 1) -->
<div>
<nocode style="color: red">|</nocode>Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>
<ul>
<li>Pierwszy punkt w liście UL.|
<li>Drugi punkt w liście UL.</li>
</ul>Węzły DIV i UL są częściowo zawarte w zakresie. Takie sytuacje powodują sporo komplikacji, ponieważ usuwanie lub zwracanie z drzewa węzłów tak rozpiętego zakresu musi przebiegać prawidłowo, aby zmodyfikowane lub zwrócone drzewo węzłów było poprawne składniowo. Dlatego też algorytmy usuwające, wypakowujące lub kopiujące zawartość zakresu są aż tak rozbudowane.
Usuwając zawartość zakresu za pomocą metody Range.deleteContents() otrzymalibyśmy zmodyfikowane drzewo węzłów w postaci:
<div>
</div>
<ul>
<li>Drugi punkt w liście UL.</li>
</ul>Widać wyraźnie, że węzły częściowo zawarte w zakresie nie zostały usunięte z drzewa węzłów, chociaż wszystkie pozostałe zostały całkowicie usunięte.
Z kolei kopiując zawartość zakresu za pomocą metody Range.cloneContents() otrzymalibyśmy obiekt typu DocumentFragment z następującą zawartością:
<div>
Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>
<ul>
<li>Pierwszy punkt w liście UL.</li>
</ul>Czyli węzły częściowo zawarte w zakresie zostały skopiowane, dlatego drzewo węzłów wciąż pozostaje prawidłowe. W zasadzie mamy prawie całą naszą pierwotną strukturę węzłową (prócz drugiego punktu w liście UL).
Jeszcze jeden przykład z mieszaną zawartością zakresu:
<!-- Początek (P1.firstElementChild.firstChild, 1) -->
<!-- Koniec (UL.lastElementChild.firstElementChild.firstChild, 3) -->
<section>
Pierwszy blok tekstowy w SECTION.
<div>
Pierwszy blok tekstowy w DIV.
<p>Tekst w <em>P|1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>
<ul>
<li>Pierwszy punkt w liście UL.</li>
<li>Drugi punkt w <em>liś<nocode style="color: red">|</nocode>cie</em> UL.</li>
</ul>
Drugi blok tekstowy w SECTION.
<section>Kopiując zawartość zakresu za pomocą metody Range.cloneContents() otrzymalibyśmy obiekt typu DocumentFragment z następującą zawartością:
<div>
<p><em>1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi blok tekstowy w DIV.
</div>
<ul>
<li>Pierwszy punkt w liście UL.</li>
<li>Drugi punkt w <em>liś</em></li>
</ul>Teraz widać jak na dłoni o co tak naprawdę chodzi. Zaczynaliśmy za pierwszym znakiem "P" węzła tekstowego w elemencie EM, dlatego został skopiowany kolejny znak "1" wraz całym element EM. Kolejny znak w zakresie "." należał do węzła tekstowego z pierwszego akapitu, dlatego akapit także został skopiowany. Wszyscy ci skopiowani rodzice są węzłami częściowo zawartymi. Bardzo podobna sytuacja będzie w przypadku końca zakresu.
Ciekawostką jest natomiast fakt, że element section nie został skopiowany. W zasadzie nie musiał, obejmuje on zarówno węzeł początkowy jaki i końcowy, nie jest węzłem częściowo zawartym, dlatego może zostać pominięty.
I jeszcze jeden króciutki przykład podkreślający to, co zostało napisane wcześniej:
<!-- Początek (DIV.firstChild, 8) -->
<!-- Koniec (DIV.lastChild, 5) -->
<div>
Pierwszy| blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
Drugi| blok tekstowy w DIV.
</div>Kopiując zawartość zakresu za pomocą metody Range.cloneContents() otrzymalibyśmy obiekt typu DocumentFragment z następującą zawartością:
blok tekstowy w DIV.
<p>Tekst w <em>P1</em>.</p>
<p>Tekst w <strong>P2</strong>.</p>
DrugiTym razem element DIV nie był węzłem częściowo zawartym, czyli był przodkiem obejmującym dla początku i końca zakresu, dlatego on sam nie został skopiowany.
Wczytując się dokładnie w poszczególne algorytmy zdefiniowane dla interfejsu Range można dojść do podobnych wniosków. Najlepiej jednak samodzielnie przeanalizować kilka żywych przykładów, by jak najdokładniej zaznajomić się ze wszystkimi meandrami tego interesującego obiektu.
Tworzenie zakresów i ustawianie punktów granicznych#
Zakres zwracany przez metodę Document.createRange() lub konstruktor new Range() jest domyślnie zwinięty tak, że obydwa punkty graniczne są jednakowe i umieszczone przed jakąkolwiek zawartością w węźle typu Document, co można zapisać następującą krotką (document, 0) i zobrazować następująco:
<!-- Początek (document, 0) -->
<!-- Koniec (document, 0) -->
#document
||
<!-- dalsza struktura znacznikowa -->Dopiero po utworzeniu zakresu możemy rozciągnąć jego punkty graniczne na odpowiednią część drzewa węzłów. Udostępniono szereg metod ułatwiających to zadanie:
Range.setStart()- ustawia węzeł początkowy i przesunięcie początkowe na przekazane wartości.Range.setEnd()- ustawia węzeł końcowy i przesunięcie końcowe na przekazane wartości.Range.setStartBefore()- ustawia węzeł początkowy i przesunięcie początkowe przed przekazanym węzłem.Range.setStartAfter()- ustawia węzeł początkowy i przesunięcie początkowe za przekazanym węzłem.Range.setEndBefore()- ustawia węzeł końcowy i przesunięcie końcowe przed przekazanym węzłem.Range.setEndAfter()- ustawia węzeł końcowy i przesunięcie końcowe za przekazanym węzłem.Range.selectNode()- ustawia początek i koniec na przekazany węzeł plus jego zawartość.Range.selectNodeContents()- ustawia początek i koniec na zawartość przekazanego węzła.
Jeśli ktoś ma problemy z samodzielnym ustaleniem węzłów i przesunięć powinien skorzystać z dwóch ostatnich metod, które wykonają całe zadanie automatycznie zarówno dla początku jak i dla końca zakresu.
Oczywiście w interfejsie Range zdefiniowano kilka innych przydatnych metod, przykładowo Range.deleteContents(), Range.extractContents(), Range.cloneContents() czy Range.surroundContents(). Możliwości i przeznaczenie wszystkich tych metod warto dokładnie przeanalizować.
Zakres został tak zdefiniowany, że jeśli ustawiany jeden z punktów granicznych ma inny korzeń niż bieżący punkt graniczny, to zakres zostaje zwinięty do nowej pozycji. To wymusza ograniczenie, że obydwa punkty graniczne muszą mieć ten sam korzeń.
Także pozycja startowa zakresu gwarantuje, że nigdy nie będzie ona za pozycją końcową zakresu. To wymusza ograniczenie, że jeśli początek jest ustawiany za końcem, to zakres zostaje zwinięty do nowej pozycji. Podobnie, jeśli koniec jest ustawiany przed początkiem, to zakres również zostaje zwinięty do nowej pozycji.
Wszystkie wspomniane wyżej ograniczenia wynikają bezpośrednio z algorytmu ustawiania początku i końca w zakresie.
Zmiany w drzewie węzłów#
Zakres rozciągany jest na aktualnym drzewie węzłów, dlatego też każda zmiana węzła w takim drzewie może mieć wpływ na stan zakresu. Dotyczy to głównie algorytmów wstawiania, usuwania, normalizacji, zastępowania danych tekstowych czy podziału. Przytoczone algorytmy mają zdefiniowane szczegółowe kroki dla zakresów w przypadku, kiedy zmiany w węzłach mają wpływ na zakres.
Przeanalizujmy następującą strukturę znacznikową z rozciągniętym zakresem:
<p>Abcd efgh <nocode style="color: red">|</nocode>XY blah i<nocode style="color: red">|</nocode>jkl</p>Poniżej zamieszczam wyniki wstawiania tekstu "inserted text" w różnych pozycjach:
<!-- 1. Przed 'X' -->
<p>Abcd efgh inserted text<nocode style="color: red">|</nocode>XY blah i<nocode style="color: red">|</nocode>jkl</p>
<!-- 2. Za 'X' -->
<p>Abcd efgh <nocode style="color: red">|</nocode>X<nocode style="font-style: italic">inserted text</nocode>Y blah i<nocode style="color: red">|</nocode>jkl</p>
<!-- 3. Za 'Y' -->
<p>Abcd efgh |</nocode>XY<nocode style="font-style: italic">inserted text blah i<nocode style="color: red">|</nocode>jkl</p>
<!-- 3. Za 'h' w 'Y blah' -->
<p>Abcd efgh |</nocode>XY blah<nocode style="font-style: italic">inserted text i<nocode style="color: red">|</nocode>jkl</p>W kolejnych przykładach część podkreślona będzie usuwaną treścią z drzewa węzłów:
<!-- 1. Przed-->
<p>Abcd efgh T|he Range i<nocode style="color: red">|</nocode>jkl</p>
<!-- 1. Po -->
<p>Abcd | Range i<nocode style="color: red">|</nocode>jkl</p>
<!-- 2. Przed-->
<p>Abcd efgh T|he Range i|<nocode style="text-decoration: underline">j</nocode>kl</p>
<!-- 2. Po -->
<p>Abcd |<nocode style="color: red">|</nocode>kl</p>
<!-- 3. Przed-->
<p>Abcd efgh T|he <em>R</nocode>ange<nocode style="color: red">|</em> ijkl</p>
<!-- 3. Po -->
<p>Abcd <em>|</nocode>ange<nocode style="color: red">|</em> ijkl</p>
<!-- Po usunięciu węzłem początkowym został węzeł TEXT posiadający dane tekstowe "ange" -->
<!-- 4. Przed-->
<p>Abcd efgh T<nocode style="color: red">|</nocode>he Range i<nocode style="color: red">|</nocode>jkl</p>
<!-- 4. Po -->
<p>Abcd <nocode style="color: red">|</nocode>he Range i<nocode style="color: red">|</nocode>jkl</p>
<!-- 5. Przed-->
<p>Abcd <em>efgh T|he Range i|<nocode style="text-decoration: underline">j</em></nocode>kl</p>
<!-- 5. Po -->
<p>Abcd |<nocode style="color: red">|</nocode>kl</p>Zakresy i zaznaczenia#
Zakresy w czystej formie są rzadko stosowane na stronach WWW. Ich prawdziwa przydatność objawia się dopiero we współpracy z interfejsem Selection, czyli z obiektami typu Selection, potocznie zwanymi zaznaczeniami. Zaznaczenie jest obiektem, który reprezentuje wszystkie zaznaczenia wykonane przez użytkownika na drzewie węzłów bieżącej strony (za pomocą myszy lub klawiatury, jak również odpowiednimi poleceniami po stronie JS).
Zaznaczenie można uzyskać metodami Window.getSelection() lub Document.getSelection(), a następnie wydobyć z nich (za pomocą dedykowanych poleceń interfejsu Selection) poszczególne zaznaczone części, które będą reprezentowane przez obiekty typu Range.
Wykorzystanie tych dwóch interfejsów daje spore pole do popisu, gdyż możemy dynamicznie zareagować na pewne akcje wykonane przez użytkownika. Nawet u mnie na stronie implementuje pewne aspekty tego rozwiązania, co można zauważyć przy każdym prezentowanym przykładzie (interaktywny przycisk [Z] lub [Z']) lub w Testerze kodu WWW v1 (stosowanie Tab lub Shift + Tab bezpośrednio na zaznaczonym kodzie) i Testerze kodu WWW v2 (gdzie zaznaczenia to istotny mechanizm biblioteki CodeMirror).
Prosty przykład:
<!DOCTYPE html>
<html>
<head>
<script>
var storedSelections = [];
function update(){
var info = document.getElementById("info");
var currSelection = window.getSelection();
var currSelectionCount = currSelection.rangeCount;
var storedSelectionsLen = storedSelections.length;
var result = "Liczba aktualnych (widocznych) zakresów: " + currSelectionCount
+ "<br>" + "Liczba zapamiętanych zaznaczeń: " + storedSelectionsLen;
info.innerHTML = result;
}
function storeSelection(){
var currSelection = window.getSelection();
var currSelectionCount = currSelection.rangeCount;
for (var i = 0; i < currSelectionCount; i++){
storedSelections.push(currSelection.getRangeAt(i));
}
currSelection.removeAllRanges();
update();
}
function clearStoredSelections(){
var currSelection = window.getSelection();
currSelection.removeAllRanges();
storedSelections.splice(0, storedSelections.length);
update();
}
function showStoredSelections(){
var currSelection = window.getSelection();
var storedSelectionsLen = storedSelections.length;
currSelection.removeAllRanges();
for (var i = 0; i < storedSelectionsLen; i++){
currSelection.addRange(storedSelections[i]);
}
update();
}
</script>
</head>
<body>
<div>Jakiś tekst wewnątrz kontenera DIV.</div>
<p>Jakiś <strong>pogrubiony tekst</strong> wewnątrz akapitu P.</p>
<p>Zaznacz dowolną zawartość na tej stronie i kliknij jeden z poniższych przycisków.</p>
<input type="button" value="Zachowaj zaznaczenie" onclick="storeSelection()">
<input type="button" value="Pokaż zachowane zaznaczenia" onclick="showStoredSelections()">
<input type="button" value="Kasuj zachowane zaznaczenia" onclick="clearStoredSelections()">
<p style="color: blue;">Szczegółowe informacje dla zaznaczeń (i ich zakresów):</p>
<p id="info"></p>
</body>
</html>Mam nadzieję, że w niedalekiej przyszłości uda mi się dokładniej opisać całą specyfikację Selection API (W3C). Tymczasem zapraszam do samodzielnej nauki tego, co zostało opisane do tej pory.