Podstawy#
Wstęp#
Document Object Model (w skrócie DOM), czyli Obiektowy Model Dokumentu (lub Model Obiektów Dokumentu) definiuje zdarzenia oraz model dokumentu dla aplikacji webowych.
Od strony teoretycznej (zawartej w specyfikacjach) jest to zestaw programowalnych interfejsów (API) charakteryzujących całą strukturę dokumentów HTML i XML. Specyfikacja jasno opisuje każdy interfejs, zależności między nimi oraz wytyczne, które muszą być spełnione przez implementacje by być zgodne z DOM. Model ten jest niezależny od platformy i może być wykorzystywany przez dowolny język programowania (np. PHP czy Java).
Od strony praktycznej implementacja DOM będzie zależna od danego programu. Najczęściej będziemy mieli do czynienia z przeglądarkami internetowymi, gdzie DOM będzie w pełni obiektową reprezentacją dokumentu umieszczaną w pamięci operacyjnej urządzenia. Każdy element dokumentu (ze struktury znacznikowej) będzie miał swój odpowiednik w postaci obiektu. Każdy obiekt będzie miał swoje określone właściwości i metody, dzięki którym możliwa będzie jego dynamiczna zmiana. Obiekty będą zależne od siebie, czyli będą organizowane w odpowiedniej hierarchii.
Specyfikacje W3C/WHATWG odnośnie DOM (oraz kilku innych języków) starają się być uniwersalne, tak żeby całość mogła mieć zastosowanie na dowolnej platformie. Biorąc pod uwagę fakt, że jedynym językiem skryptowym obsługiwanym przez wszystkie przeglądarki jest ECMAScript (zwany JavaScriptem, JScript, JS) bardzo często specyfikacje będą specjalnie rozszerzane o dokładne wytyczne dla tego języka.
Przetwarzanie przez przeglądarki#
Zamiast prezentować zawiłe regułki lepiej będzie przedstawić temat na prostym przykładzie dokumentu HTML. Kiedy klikamy na dowolny odsyłacz (prowadzący do strony internetowej) przeglądarka nawiązuje połączenie z danym serwerem, na który wskazuje adres odnośnika. Mówimy wówczas, że przeglądarka wysyła żądanie (request) do serwera. Serwer odbiera żądanie, analizuje je i podejmuje określone kroki. W naszym przykładzie po prostu prześle do przeglądarki plik, który może być statycznym dokumentem HTML, albo dynamicznie generowaną treścią (np. przez język skryptowy po stronie serwera). Mówimy wówczas, że serwer wysyła odpowiedź (response).
Kiedy przeglądarka odbierze taki strumień bajtów (nasz plik) musi podjąć względem niego jakieś kroki. Rodzaj danego zasobu jest zazwyczaj rozpoznawany po typie MIME odczytywanym z nagłówków serwera. Jeśli będzie to dokument (X)HTML przeglądarka będzie musiała go odpowiednio przetworzyć (sparsować). Zaprzęgnie do tego swój parser HTML/XML. Parser zacznie analizować każdy znak w dokumencie, rozpozna czy ma do czynienia ze znacznikiem czy z inną treścią, w razie czego pobierze pozostałe zasoby (multimedia) i na podstawie wszystkich danych utworzy a następnie wyświetli nam gotowy dokument w oknie przeglądarki.
Nie byłoby w tym nic nadzwyczajnego gdybyśmy mieli do czynienia tylko z dokumentami statycznymi, czyli całkowicie pozbawionymi możliwości jakiejkolwiek dynamicznej zmiany przez programistę po stronie użytkownika. Wówczas każdy program przetwarzający mógłby zaimplementować własne sposoby parsujące/wyświetlające i problem z głowy. Tak naprawdę liczyłby się tylko końcowy efekt. Początkowo tak właśnie wyglądało operowanie stronami WWW.
Z biegiem czasu statyczne strony okazały się niewystarczające dla potrzeb WWW. Programiści zapragnęli dynamicznej interakcji z wyświetlaną stroną. Przeglądarki musiały udostępnić jakiś sposób manipulacji dowolnym dokumentem. Tym właśnie jest nasz omawiany DOM. Parsery w przeglądarkach analizują kod znacznikowy i budują na ich podstawie całą obiektową strukturę danego dokumentu i lokują ją w pamięci - jest to tzw. drzewo DOM. Obiekty są udostępniane dla języków skryptowych i mogą być przez nie dowolnie modyfikowane.
Na podstawie drzewa DOM będzie jednocześnie tworzone drzewo renderowania #, które odpowiada za sposób wyświetlania węzłów DOM. Drzewo renderowania będzie miało co najmniej jeden węzeł dla każdego węzła drzewa DOM, który musi być wyświetlony. Węzły, które nie muszą zostać wyświetlone to np. komentarze, DOCTYPE czy węzły ukryte. Węzły w drzewie renderowania są nazywane ramkami lub polami, zgodnie z modelem CSS, który traktuje element strony jako pole z dopełnieniami i marginesami, obramowaniami oraz położeniami. Dopiero po zbudowaniu drzewa DOM i drzewa renderowania, przeglądarka może wyświetlić (namalować) elementy na stronie.
Gdy zmiana w drzewie DOM ma wpływ na wymiary elementu (szerokość i wysokość) - na przykład przy zmianie grubości obramowania lub dodaniu tekstu - przeglądarka musi przeliczyć ponownie geometrię elementu, a także geometrię i położenie innych elementów, których mogła dotyczyć ta zmiana. Przeglądarka unieważnia część drzewa renderowania, na które zmiana ma wpływ, i dokonuje jego rekonstrukcji. Proces ten określany jest jako ponowne wlewanie (reflow). Po wykonaniu ponownego wlewania, przeglądarka ponownie rysuje zmienione części ekranu w procesie określanym jako przemalowanie. Ta sama uwaga będzie dotyczyła dodawania lub usuwania elementów z drzewa DOM.
Nie wszystkie zmiany w DOM mają wpływ na geometrię. Na przykład zmiana koloru tła nie zmieni szerokości ani wysokości elementu. W tym przypadku ma miejsce tylko przemalowanie (bez ponownego wlewania), gdyż układ elementów pozostaje bez zmian.
Tak szczegółowy opis procesu budowania i wyświetlania strony opisuję już teraz nie bez powodu. Przemalowanie oraz ponowne wlewanie są operacjami bardzo kosztownymi (w porównaniu z operacjami samego JS). Niewłaściwe wykonywanie tego zadania może sprawić, że UI aplikacji sieciowej będzie wolniej reagował. Dlatego bardzo ważna jest minimalizacja liczby takich operacji gdy tylko to możliwe.
Na poniższej grafice znajduje się przykładowa struktura DOM dla dokumentu HTML.
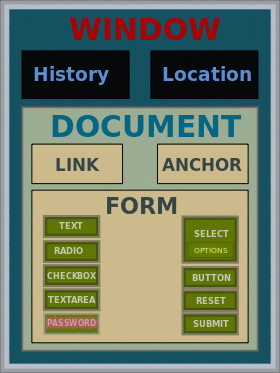
Rysunek. Hierarchia obiektów w przykładowym HTML DOM
Najwyżej w hierarchii położony jest obiekt window, który reprezentuje okno przeglądarki. Obiekt ten zawiera inne obiekty history, location oraz document. Obiekt document reprezentuje nasz właściwy dokument HTML i zawiera obiekty link, anchor oraz form. Każdy z tych obiektów może posiadać kolejne obiekty. Wszystko (a przynajmniej większość) można dynamicznie modyfikować. Nie wygląda to skomplikowanie, ale w praktyce okaże się bardzo problematyczne, głównie ze względów na sposób implementacji DOM w przeglądarkach.
Wielki bałagan z przeszłości#
Pierwsze przeglądarki internetowe były w stanie jedynie wyświetlić dokumenty HTML. Nie posiadały żadnego mechanizmu umożliwiającego modyfikowanie dokumentu po stronie użytkownika. Wszystko zmieniło się w 1995 roku, po wprowadzeniu przez przeglądarkę Netscape Navigator 2.0 języka skryptowego LiveScript (szybko przemianowanego na JavaScript). Język ten okazał się na tyle ciekawy, że zmarginalizował inne technologie osadzane na WWW, np. aplety Javy. JavaScript był lekkim językiem skryptowym, który oprócz swojej rdzennej postaci (jako pełnoprawnego języka programowania) pozwalał także na dostęp do pewnych elementów na stronie (np. ramek, obrazków czy formularzy).
Popularność języka spowodowała, że główny rywal Netscape'a - Microsoft - postanowił zaimplementować JavaScript u siebie. Oczywiście MS nie miał dostępu do oryginalnej implementacji, ale mógł ją zrekonstruować wykorzystując inżynierię wsteczną # (reverse engineering) [WikiEN|WikiPL]. Zrobił to tak dokładnie, że praktycznie przekopiował cały język ze wszystkimi jego błędami, które ze względów na kompatybilność pozostawiono bez zmian w późniejszych wydaniach specyfikacji ECMAScript. Jednym z bardziej znanych błędów będzie zwracanie typu obiektowego dla wartości null (typeof null === "object").
Pomimo że sam język JS został zaimplementowany w przeglądarkach niemalże identycznie, to sposoby manipulacji dokumentem były już bardzo odmienne. W krytycznym momencie obie firmy specjalnie wprowadzały inne metody tak, by czynić swoje produkty jak najbardziej niekompatybilnymi z rozwiązaniami konkurencji (np. pobieranie kolekcji za pomocą Document.layers lub Document.all). Oznaczało to konieczność tworzenie wielu wersji kodu, przygotowanego specjalnie pod każdą przeglądarkę. Cechy które były obsługiwane tak samo zostały potem określone jako DOM Level 0 (DOM poziomu zerowego), ale w rzeczywistości nigdy nie był to oficjalny standard.
W3C postanowiło zrobić coś w tym kierunku. W 1998 roku wydano pierwszy standard DOM Level 1. Składał się on z dwóch osobnych dokumentów. Pierwszy definiował model podstawowy (DOM Core Level 1), czyli zbiór minimalnych reguł dostępnych zarówno dla dokumentów XML jaki i HTML. Druga część opisywała już reguł właściwe dla dokumentów HTML (DOM HTML Level 1). HTML zawsze był "śmietnikiem tagów" dlatego koniecznym było definiowanie dla niego dodatkowych/osobnych reguł.
W roku 2000 opublikowano kolejną wersje standardu DOM Level 2. Oprócz nowej części bazowej (DOM Level 2 Core) i HTML-owej (DOM Level 2 HTML) w jego skład wchodziły jeszcze inne dokumenty, np. definiujące zdarzenia (DOM Level 2 Events), poruszanie po drzewie i zakres (DOM Level 2 Traversal and Range), widoki (DOM Level 2 Views) i style (DOM Level 2 Style).
Kolejnym etapem standaryzacyjnym był DOM Level 3 wprowadzony w 2004 roku. Definiował on na nowo model podstawowy (DOM Level 3 Core), zdarzenia (DOM Level 3 Events) oraz wprowadzał jakieś pomniejsze dokumenty.
Standardy standardami, ale rzeczywistość okazała się bardziej brutalna. Żadna przeglądarka nie zaimplementowała standardu DOM (dowolna wersja) w 100% poprawnie. Na domiar złego, ta która w późniejszym czasie zagarnęła większość rynku na długie lata (czyli Internet Explorer) miała ten model zepsuty, tzn. część rzeczy pochodziła ze standardu, ale inne były własnymi rozwiązaniami. Sytuacja taka utrzymywała się aż do wydania IE9. Co prawda w IE9 jest z tym lepiej, ale na tle konkurencji produkt Microsoftu zawsze będzie w tyle. Wynika to raczej z modelu dystrybuowania przeglądarki, a nie braku chęci ze strony programistów odpowiedzialnych za jej rozwój. Nowe wersje zazwyczaj pojawiają się wraz z udostępnieniem kolejnego systemu operacyjnego, czyli co 3-4 lata. Z perspektywy technologii webowych jest to zbyt długi czas, by mówić o produkcie MS w dobrym kontekście.
Ze względu na szybki cykl wydawniczy pozostałych przeglądarek (Firefox, Safari, Opera i Chrome) mogliśmy na bieżąco testować najnowsze nowinki. Producenci tych przeglądarek zawsze próbowali implementować jak najszybciej jak największą liczbę standardów, dlatego tworzenie kodu dla tych produktów nie stwarzało wielu problemów. Oczywiście drobne różnice zawsze występowały, każda przeglądarka miała swoje mniejsze i większe błędy w implementacji DOM. Niestety, ze względów na popularność IE trzeba było tworzyć kod podwójny, przeznaczony dla konkretnej rodziny przeglądarek (czasami nawet osobny dla wersji w danej rodzinie). Właśnie przez to JavaScript uzyskał miano "tego niedobrego", kiedy rzeczywistym winowajcą był DOM. O dziwo JavaScript był implementowany bardzo spójnie, i rzadko wymagał stosowania haków.
Obecna sytuacja (DOM4 i DOM Living Standard)#
Od 2013 roku możemy już tworzyć kod, w którym bardziej skupiamy się na wymyślaniu czegoś nowego niż na samym jego implementowaniu. Obecne przeglądarki w dużym zakresie zaadoptowały DOM Level 2, co jest zazwyczaj wystarczające. Ta sama uwaga dotyczy języków CSS, JavaScript oraz HTML5.
A co z samym DOM? Sytuacja jest bardzo interesująca. Z racji tego, że cały HTML5 definiowany jest w kategoriach DOM, nie ma potrzeby powtarzać tego w specyfikacji DOM. Dlatego aktualnie trwają prace nad wydaniem DOM4 (W3C) i DOM Living Standard (WHATWG), który będzie opisywał model podstawowy w połączeniu z innymi specyfikacjami, tak aby całość miała odniesienie dla dowolnego dokumentu XML czy HTML.
Nowa specyfikacja powstaje według następujących kryteriów:
Poprzez połączenie DOM Level 3 Core, DOM Level 2 Traversal and Range, Element Traversal, Selectors API Level 2 oraz kilku części z DOM Level 3 Events ("DOM Event Architecture" i "Basic Event Interfaces"), a także:
- Dostosowania jej do potrzeb języka JavaScript w miarę możliwości.
- Dostosowania jej do już istniejących implementacji.
- Uproszczenia jej w jak największym zakresie.
- Poprzez przeniesienie funkcji właściwych dla HTML5, które nie powinny być częścią nowej specyfikacji DOM4, czyniąc ją niezależną od HTML5.
- Poprzez wprowadzenie zamiennika dla "Mutation Events" i "Mutation Name Event Types" z DOM Level 3 Events, które były problematyczne. Stary model prawdopodobnie zostanie usunięty przez aplikacje klienckie w przyszłości.
- Poprzez zdefiniowanie nowych poleceń, które upraszczają typowe operacje DOM.
Pisząc w kursie "DOM4" lub "specyfikacja DOM4" będę miał na myśli "żywą wersję" od WHATWG, gdyż materiał ten na bieżąco jest uzupełniany i poprawiany.
Specyfikacja DOM4 wprowadza sporo zmian, usuwa wiele interfejsów, atrybutów i operacji z poprzednich standardów. Specjalnie nie będę ich opisywał, ponieważ zaleca się porzucenie ich wsparcia w nowszych programach. Lepiej uczyć się i stosować tylko to, co aktualne jest teraz i aktualne będzie przez najbliższe lata.
Punkt odniesienia dla planowanych zmian#
Upraszczanie i dalszy rozwój specyfikacji DOM to wyjątkowo delikatny proces. W zasadzie dotyczy to wszystkich specyfikacji, które zostały w jakimś stopniu zaimplementowane. Na przestrzeni lat powstało wiele bibliotek, które w mniejszym lub większym stopniu korzystają z poleceń, które można by zastąpić już istniejącymi i popularniejszymi wariantami. Całkowite usunięcie zbytecznego balastu, choć bardzo pożądane, mogłoby doprowadzić do błędnego działania wielu stron bazujących na starszych wersjach bibliotek. Prym wiedzie tutaj jQuery, dla której zapewnienie kompatybilności wstecznej # (backward compatibility) [WikiEN|WikiPL] jest chyba najważniejszym wyznacznikiem przyszłych zmian.
Kolejnym interesującym punktem odniesienia może być dedykowana witryna ze statystykami projektu Chromium, gdzie prezentowana jest popularność najważniejszych mechanizmów platformy webowej w oparciu o informacje pozyskane wprost z przeglądarek bazujących na Chromium. Podobną telemetrię # (telemetry) [WikiEN|WikiPL] prowadzi także Mozilla w przeglądarce Firefox (Telemetry - MozillaWiki, Telemetry Dashboards). Wiele decyzji związanych z dalszym rozwojem i upraszczaniem DOM zostaje podparta właśnie owymi statystykami.
Niezależnie od sposobu pozyskiwania danych telemetrycznych i tak decydujące znaczenie będzie miała rzeczywistość. Niejednokrotnie zdarzało się, że marginalna wartość danego pomiaru (nawet rzędu 0,001% czy 0,0001% w stosunku do całej próbki) i tak powodowała problemy w już istniejących systemach (głównie korporacyjnych). Twórcy przeglądarek na ogół kierują się realnymi problemami, a same specyfikacje (choć w dłuższej perspektywie bardzo potrzebne), są jedynie drogowskazem, który w razie potrzeby można - i niejednokrotnie trzeba - po prostu zmienić.
Jeśli ktoś chciałby być na bieżąco ze wszystkimi niuansami w obrębie webu powinien dodatkowo śledzić następujące adresy:
- W3C Public Mailing List Archives (listy mailingowe W3C, np. www-dom@w3.org, public-webapps@w3.org, public-web-perf@w3.org, www-style@w3.org czy public-html@w3.org)
- LogBot (logi z rozmów, np. LogBot - #whatwg czy LogBot - #html5)
- Specifiction Discourse (nowe pomysły zgłaszane przez społeczność)
- ECMAScript Discussion Archives (logi z rozmów dla aktualnych i przyszłych wersji ES)
- mail.mozilla.org Mailing Lists (listy mailingowe Mozilli)
- W3C Webperf Tracker (aktualne błędy dla specyfikacji związanych z wydajnością)
- Bugzilla@Mozilla (aktualne błędy dla wszystkich produktów Mozilli)
- WebKit Bugzilla (aktualne błędy dla programów bazujących na WebKicie)
- Chromium Issues (aktualne błędy dla programów bazujących na Chromium)
Systematyczna lektura wyżej wymienionych źródeł dostarcza szereg informacji odnośnie dalszych poczynań osób związanych z rozwojem technologii webowych, i niejednokrotnie pozwala zrozumieć mechanizmy działania aktualnych rozwiązań. Jest to jeden z najlepszych sposobów przyswajania "niskopoziomowej wiedzy", z którego sam czerpię garściami.
Zbędny balast#
Z uwagi na wspomnianą wcześniej kompatybilność wsteczną niektóre polecenia, takie jak Attr.specified, DOMImplementation.hasFeature(), Range.detach() czy NodeIterator.detach() pozostawiono, ale przedefiniowano tak, by ich wpływ na działanie już utworzonego kodu był jak najmniej dotkliwy. W większości przypadków polecenia te nie będą robiły niczego sensownego, co same w sobie wydaje się dość dziwne. Z perspektywy programowania polecenia te określa się terminem instrukcji pustych # (no operation) [WikiEN|WikiPL|WhatIs] i najczęściej opisuje skróconymi formami NOP, NOOP lub no-op.
Innym przykładem będą aliasy # (WikiEN|WikiPL), czyli dodatkowe nazwy dla już istniejących właściwości lub metod. Te nadmiarowe polecenia są spuścizną po bałaganie z przeszłości, których w klasycznym rozumieniu usunąć nie można, a jedynym sensownym wyjściem, o ile to możliwe, jest po prostu przekierowanie do już istniejących poleceń, co w założeniu ma prowadzi do uproszczenia całej platformy. Oto kilka z nich:
Document.charsetiDocument.inputEncoding(aliasy doDocument.characterSet)Attr.nodeName(alias doAttr.name)Attr.nodeValueiAttr.textContent(aliasy doAttr.value)
Istnieje duże prawdopodobieństwo, że wraz z upływem czasu, a co za tym idzie jeszcze większą marginalizacją przestarzałych bibliotek, część wyżej wymienionych poleceń zostanie całkowicie usunięta. Najlepiej unikać ich stosowania i zawsze sięgać po aktualne (właściwsze) warianty.
Wydajność#
Przy uproszczonym opisie renderowania stron przez przeglądarki napomknąłem o przykrych konsekwencjach manipulacji DOM, czyli o wpływie na ogólną wydajność strony/aplikacji. Przyczyna tego jest bardzo prosta: implementacje DOM i JavaScript są zazwyczaj od siebie niezależne. Na przykład w Internet Explorerze implementacja JavaScript nosi nazwę JScript i znajduje się w pliku biblioteki o nazwie jscript.dll, natomiast implementacja DOM znajduje się w innej bibliotece mshtml.dll (wewnętrznie znanej jako Trident i nazywanej potocznie silnikiem przeglądarki). Taka separacja pozwala innym technologiom i językom, takim jak VBScript, na korzystanie z DOM i funkcji renderowania oferowanych przez Trident.
Podobne rozwiązanie występuje w pozostałych popularnych przeglądarkach. Safari korzysta z należącej do WebKit biblioteki WebCore dla DOM i renderowania, oraz ma oddzielną maszynę JavaScriptCore (określaną w ostatniej wersji jako SquirrelFish). Także Google Chrome korzysta z biblioteki WebCore z WebKit do renderowania stron, ale implementuje własną maszynę JavaScript o nazwie V8. W Firefox implementacja JavaScript jest połączeniem kilku rozwiązań (JägerMonkey + TypeInference + IonMonkey), a za renderowanie odpowiada silnik Gecko.
Co to oznacza dla wydajności? Po prostu korzystanie z dwóch oddzielnych elementów funkcjonalności współpracujących ze sobą zawsze niesie dodatkowy koszt. Świetną analogią jest potraktowanie DOM jako części terenu, zaś JavaScript (w znaczeniu ECMAScript) jako inną część terenu, połączonych płatnym mostem. Za każdym razem, gdy nasz ECMAScript potrzebuje dostępu do DOM, trzeba przejechać przez most i uiścić opłatę za przejazd, która w tym wypadku będzie wydajnością. Im więcej współpracujemy z DOM, tym więcej musimy zapłacić.
O ile techniki optymalizacyjne dla samego ECMAScriptu mogą tracić na znaczeniu (ze względu na coraz wydajniejsze i sprytniejsze maszyny JS), w przypadku DOM zagadnienie będzie aktualne jeszcze przez długie lata. Ogólne zalecenie jest więc takie, aby możliwie najrzadziej przekraczać most, pozostając na terenie ECMAScript. Jeśli już musimy modyfikować DOM należy to robić z wykorzystaniem wszelkich dostępnych wskazówek minimalizujących (w pewnym zakresie) koszty wydajnościowe.
Biblioteki#
DOM jest nieintuicyjny, niekompatybilny i niepraktyczny. Po dłuższej pracy z DOM każdy dojdzie do podobnych wniosków. Najbardziej będzie doskwierać kwestia kompatybilności, szczególnie w przypadku starszych przeglądarek. Abstrahując już od tego całego bałaganu z poszczególnymi implementacjami, to nawet sama składnia DOM jest bardzo rozwlekła, przykładem mogą być metody getElementById(), getElementsByClassName() czy getElementsByTagName(). Trzeba się nieźle napracować zanim utworzymy właściwy kod. Wszystkie te bolączki starają się wyeliminować twórcy bibliotek. Biblioteki ukrywają całą specyfikację DOM, udostępniając na wierzchu interfejsy bardziej zwięzłe i przyjazne dla programistów, z jednoczesnym zachowaniem kompatybilności między przeglądarkami. Oczywiście najlepszym tego przykładem będzie znana biblioteka jQuery # (autorstwa Johna Resiga), która w szczególności nastawiona jest na współpracę z DOM. Bibliotek tego typu będzie więcej, np. Prototype, Dojo, YUI.
Biblioteki to ciekawe narzędzia programistyczne, ale ich stosowanie wprowadza kilka wymagań. Pierwsze i najważniejsze to konieczność nauki nowych poleceń. Może wydawać się to śmieszne, ale niektóre biblioteki są bardzo rozbudowane, ich gruntowne poznanie może zająć sporo czasu. Kolejna sprawa to utrzymywanie aktualności. Biblioteki się zmieniają, z biegiem czasu wprowadzają nowe funkcjonalności, zmieniają poprzednie a także obsługują różne rodziny i wersje przeglądarek. Ostatnia i chyba najważniejsza kwestia: biblioteki nie załatwią wszystkiego za nas. Zawsze pojawi się jakieś zadanie, które będzie trzeba implementować przy użyciu natywnych rozwiązań, lub poprzez samodzielne poszerzenie funkcjonalności biblioteki. Notka wpisana w CV ("ekspert od jQuery") na nic się zda, jeśli osoba nie będzie też ekspertem od JS.
Podsumowując, biblioteki są jak najbardziej wskazane, ale pod warunkiem uprzedniego przyswojenia pierwotnych technologii. Tyczy się to w szczególności osób początkujących, które próbują iść na skróty i szerokim łukiem omijają to, co w zasadzie będzie najważniejsze, czyli gruntowna znajomość ECMAScript.