Podstawy#
Parsowanie i serializacja#
Z pojęciami parsowania i serializacji nieustannie będziemy mieli do czynienia w czasie programowania. Zagadnienia te są uniwersalne i dotyczą przetwarzania dowolnego języka (naturalnego czy komputerowego). Nie inaczej będzie w przypadku DOM. Sama specyfikacja DOM4 definiuje algorytm parsowania i algorytm serializacji jedynie dla uporządkowanego zestawu słów powiązanego z listami słów DOM.
Reszta poleceń parsowania i serializacji (skrót P&S #) udostępnianych przez przeglądarki internetowe nigdy nie została ustandaryzowana. Sytuację próbuje uporządkować grupa WHATWG, do której w późniejszym czasie dołączyło także W3C. W związku z tym mamy dostęp do dwóch specyfikacji:
Na dzień dzisiejszy tylko wersja od W3C jest stale rozwijana i niewiele brakuje by uzyskała status rekomendacji. Dokument od WHATWG był jej pierwowzorem, w którym uwzględniono pewne kontrowersyjne zmiany (np. te związane z węzłami CDATA). Okazało się to jednak zbyt ambitne i pomysł nie trafił do aktualnej specyfikacji W3C, ale z zastrzeżeniem, że w przyszłości może powrócić w kolejnych wydaniach specyfikacji.
Tak czy inaczej jest niemal pewne, że w przypadku parsowania i serializacji pojawią się różnice w obsłudze niektórych poleceń przez przeglądarki. Dostosowanie do nowych wymagań zajmie implementacjom trochę czasu, dlatego najlepiej samodzielnie zgłaszać każde odstępstwa od specyfikacji (aktualna lista błędów). Należy jednak podkreślić, że część parsujących i serializujących poleceń (np. właściwości Element.innerHTML i Element.outerHTML) na dobre upowszechniły się wśród programistów WWW, dlatego też materiał pochodzący od W3C umieszczam bezpośrednio w głównym kursie DOM.
Zanim przejdę do szczegółowych "technikaliów" całego zagadnienia, pragnę zaprezentować i pokrótce omówić kilka podstawowych pojęci, które ułatwią zrozumienie całości.
Parsowanie#
W dużym uproszczeniu można powiedzieć, że parsowanie polega na zamianie danych tekstowych (wejście) na odpowiadającą im strukturę obiektową (wyjście). Jest to przeciwieństwo (ale nie odwrotność) serializacji.
Parsowanie|analiza składniowa|analiza syntaktyczna # (parsing|syntactic analysis) (WikiEN|WikiPL) to w informatyce i lingwistyce proces analizy tekstu, w celu ustalenia jego struktury gramatycznej i zgodności z gramatyką języka. Słowo "parsing" pochodzi od łacińskiego "pars" (ōrātiōnis), które oznacza część mowy. Termin ma nieco inne znaczenie w różnych gałęziach językoznawstwa i informatyki, dlatego od razu przejdziemy do aspektów informatycznych.
W informatyce pojęcie parsowania najczęściej używane jest do analizy języków programowania i odnosi się do analizy składniowej (syntaktycznej) kodu wejściowego dla jego części składowych, w celu ułatwienia pisania kompilatorów i interpreterów.
Za proces parsowania odpowiedzialny jest specjalny moduł zwany parserem # (parser) [WikiEN|WikiPL], który zazwyczaj jest częścią kompilatora lub interpretera. Parser pobiera tekst wejściowy i na jego podstawie buduje strukturę danych # (data structure) [WikiEN|WikiPL], która najczęściej jest drzewem składni # (parse tree) [WikiEN|WikiPL], drzewem składni abstrakcyjnej # (abstract syntax tree) [WikiEN|WikiPL] lub inną hierarchiczną strukturą odzwierciedlającą dane wejściowe, z jednoczesnym sprawdzeniem poprawności składniowej. Parsowanie może być wykonane przed lub po określonych etapach, lub może być wykonywane w jednym kompleksowym etapie. Parser najczęściej jest poprzedzany oddzielnym analizatorem leksykalnym|lekserem # (lexical analyser|lexer) [WikiEN|WikiPL], który wyodrębnia słowa # (tokens) [WikiEN, WikiPL] z sekwencji danych wejściowych; alternatywnie, może być to połączone w jednym kroku zwanym scannerless parsing. Parser może być programowany ręcznie lub może być wygenerowany automatycznie lub półautomatycznie (w niektórych językach programowania) za pomocą generatora parsera # (parser generator) [WikiEN|WikiPL].
Proces przetworzenia tekstowych danych wejściowych na hierarchiczną strukturę danych można wyrazić za pomocą poniższej grafiki:
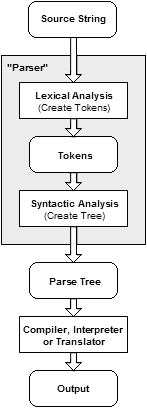
Rysunek. Zamiana danych tekstowych na hierarchiczną strukturę danych w procesie parsowania
Zastosowanie parserów jest silnie uzależnione od samego wejścia (danych wejściowych). W przypadku języków danych (np. znacznikowego HTML lub XML) parser najczęściej występuje jako program ułatwiający czytanie plików. W przypadku języków programowania parser występuje jako komponent dla kompilatora lub interpretera. Analizuje on kod źródłowy w postaci jakiegoś języka programowania w celu utworzenia wewnętrznej reprezentacji, i w tym przypadku parser jest kluczowym etapem na wierzchu kompilatora (compiler frontend) [WikiEN]. Języki programowania zazwyczaj są określane w kategoriach deterministycznej gramatyki bezkontekstowej # (deterministic context-free grammar) [WikiEN|WikiPL] ponieważ można dla nich napisać szybkie i efektywne parsery. Ze względu na to, że ogólne metody analizy języków bezkontekstowych # (context-free language) [WikiEN|WikiPL] mają złożoność O(n^3), często są to pewne podklasy gramatyk bezkontekstowych, np. LALR # (Look-Ahead LR parser) [WikiEN|WikiPL].
Przeważnie gramatyką bezkontekstową nie da się wyrazić wszystkich reguł projektowanego języka. Nieformalnie mówiąc, powodem jest to że pamięć takiego języka jest ograniczona. Gramatyka nie może pamiętać obecności konstrukcji dla bardzo długiego wyrażenia wejściowego; jest to niezbędne dla języków, w których np. nazwa (nazwa zmiennej) musi być zadeklarowana zanim się do niej odwoła. Bardziej złożone gramatyki potrafią sprawdzać takie zasady, jednak wtedy analiza składni nie jest już tak efektywna. Powszechną strategią jest tworzenie mniej restrykcyjnych parserów dla gramatyk bezkontekstowych, dopuszczających pewne nieprawidłowe konstrukcje, które są filtrowane w późniejszym etapie analizy semantycznej # (semantic analysis) [WikiEN|WikiPL].
Przykład teoretyczny#
Następujący przykład prezentuje typowy przypadek przeprowadzania analizy składniowej prostego języka wyrażeń arytmetycznych, z dwoma poziomami gramatyki: leksykalnym i składniowym.
Faza pierwsza jest generacją tokenów (analizą leksykalną), w trakcie której strumień wejściowy jest dzielony na znaczące tokeny, określone przez gramatykę wyrażeń regularnych. Przykładowo program kalkulatora mógłby przetwarzać ciąg znaków taki jak "12*(3+4)^2" i dzielić go na tokeny 12, *, (, 3, +, 4, ), ^, 2, gdzie każdy coś oznacza w kontekście wyrażenia arytmetycznego. Lekser mógłby zawierać reguły, które mówiłyby, że znaki *, +, ^, (, ) zaznaczają początek nowego tokenu, tak że ciągi bez znaczenia jak "12*" albo "(3" nie byłyby brane pod uwagę.
Następna faza to analiza składni (analiza syntaktyczna), która sprawdza czy tokeny tworzą dopuszczalne wyrażenie. To zazwyczaj jest robione w oparciu o gramatykę bezkontekstową, która rekurencyjnie definiuje komponenty tworzące wyrażenie oraz ich kolejność. Jednakże nie wszystkie zasady definiujące języki programowania mogą zostać wyrażone przy pomocy czystej gramatyki bezkontekstowej, na przykład zgodność typów oraz właściwa deklaracja identyfikatorów. Te zasady mogą zostać formalnie wyrażone za pomocą gramatyki atrybutywnej # (attribute grammar) (WikiEN).
Faza końcowa to analiza semantyczna, która opracowuje znaczenie dopiero co zweryfikowanego wyrażenia i podejmuje odpowiednie działania. W przypadku kalkulatora zadaniem jest obliczenie wyrażenia. Kompilator mógłby w tym miejscu generować kod wynikowy. Do definiowana tych akcji może być również użyta gramatyka atrybutywna.
W kolejnym przykładzie wykonujemy analizę leksykalną i syntaktyczną dla następującego fragmentu kodu if(net>0.0)total+=net*(1.0+tax/100.0); zgodnego z językiem C. Proces ten można wyrazić poniższą grafiką:
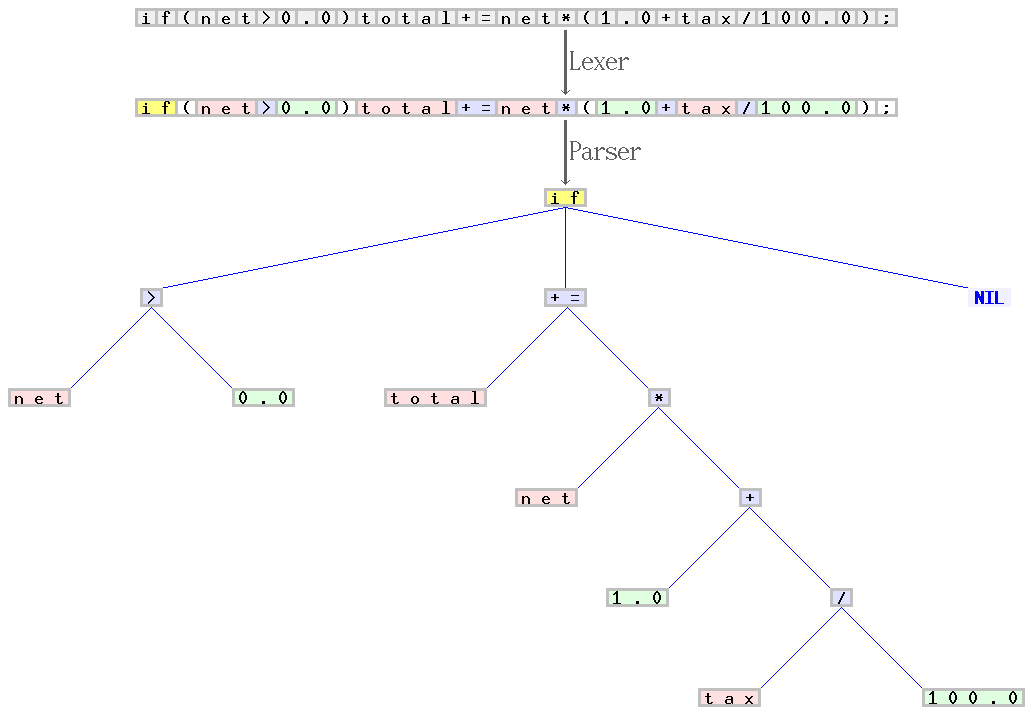
Rysunek. Przykładowa analiza leksykalna i syntaktyczna dla fragmentu w języku C
Lekser (zaczynając od początku fragmentu kodu) tworzy sekwencję tokenów, po czym przypisuje im określone kategorie, dla przykładu identyfikator, słowo zastrzeżone, literał liczbowy czy w końcu operator. W następnym etapie parser przetwarza taką sekwencję tokenów i generuje z niej drzewo składni, które można wykorzystać w dalszej fazie kompilacji. W tym wypadku lekser i parser operują na regularnych i bezkontekstowych częściach gramatyki języka C.
Przeglądarki internetowe#
Z punktu widzenia przeglądarek internetowych mechanizm parsowania wygląda podobnie. Przy wczytywaniu strony WWW program uruchamia odpowiedni parser (np. parser HTML) i generuje obiektową reprezentację dokumentu, czyli drzewo węzłów. Specyfikacja HTML5 dokładnie opisuje proces parsowania dokumentu HTML (w tym również dokumentów XHTML), dzięki czemu każdy program zgodny z najnowszym standardem powinien robić to w jednakowy sposób.
Trzeba pamiętać również o tym, że istnieją pewne polecenia, które pozwalają wykonać parsowanie wprost z kodu JavaScript. Będą to chociażby wymienione już właściwości Element.innerHTML i Element.outerHTML, metoda DOMParser.parseFromString(), Document.write() i wiele innych. Każde z tych poleceń ma ściśle określony przez daną specyfikację algorytm działania i powinno zwracać zgodną z nim obiektową strukturę danych wyjściowych.
Napisanie własnego parsera może być trudnym zadaniem, ale stosowanie gotowych poleceń udostępnianych przez przeglądarki internetowe nie powinno stanowić kłopotu. Z praktycznego punktu widzenia nie ma się co przejmować całą przytoczoną tutaj terminologią dotyczącą parsowania.
Wynikiem parsowania może być kod wykonywalny, dlatego też należy zachować szczególną ostrożność w sytuacji, kiedy dane wejściowe dla parsera pochodzą z niezaufanego źródła.
Serializacja#
W dużym uproszczeniu można powiedzieć, że serializacja polega na zamianie struktury obiektowej (wejście) na odpowiadające im dane tekstowe (wyjście). Jest to przeciwieństwo (ale nie odwrotność) parsowania.
Serializacja # (serialization) [WikiEN|WikiPL] to w informatyce proces przekształcania hierarchicznej struktury danych lub obiektów do postaci szeregowej, czyli formatu, który może być przechowywany, z zachowaniem aktualnego stanu obiektów. W przypadku webu najpopularniejszym formatem dla serializacji jest JSON (dawniej prym wiódł XML).
Taka zserializowana postać obiektu może być przechowywana, np. w buforze pliku lub pamięci, przesyłana do innego procesu lub innego komputera poprzez Sieć, i w późniejszym czasie odtwarzana w tym samym lub innym środowisku komputerowym. Kiedy otrzymany szereg bitów jest odczytywany zgodnie z formatem serializacji, to może być wykorzystywany do utworzenia semantycznie identycznych klonów dla oryginalnych obiektów. Dla wielu złożonych obiektów, np. takich które w szerokim zakresie używają referencji, proces ten nie należy do najłatwiejszych. Serializacja obiektów zorientowanych obiektowo nie zawiera żadnych związanych z nimi metod, z którymi wcześniej były ze sobą nierozerwalnie powiązane.
Procesem stricte odwrotnym do serializacji jest deserializacja # (deserialization). Polega ona na odczytaniu wcześniej zapisanego strumienia danych i odtworzeniu na tej podstawie obiektu wraz z jego stanem bezpośrednio sprzed serializacji.
Innymi potocznie stosowanymi synonimami dla serializacji są deflating oraz marshalling (WikiEN|WikiPL) a dla deseralizacj deflating oraz unmarshalling. Warto jednak zaznaczyć, że wymienność serializacj i marshallingu zależy od samego języka programowania (np. zachodzi w przypadku Pythona, ale nie w Javie).
W środowisku webowym (np. w odniesieniu do HTML-a) parsowanie najczęściej utożsamiane jest z deserializacją, chociaż dla bardziej złożonych systemów istnieje szerszy podział. Warto jedynie zaznaczyć, że dane wejściowe dla parsera nie muszą być identyczne z tymi, które zwraca serializer:
wejście(text) >> parser >> serializer >> wyjście(text) wejście(text) != wyjście(text)
Parsery zazwyczaj usuwają nadmiarowe białe znaki i dodatkowo mogą korygować błędy składniowe (jak w HTML-u), co uniemożliwia odtworzenie oryginalnych danych wejściowych w procesie parsowanie-serializacja.
Przeglądarki internetowe#
Z punktu widzenia przeglądarek internetowych mechanizm serializacji wygląda podobnie. Każdy obiekt (np. węzeł) jest zamieniany na odpowiadającą postać tekstową za pomocą dedykowanych poleceń, np. właściwości Element.innerHTML i Element.outerHTML, metod XMLSerializer.serializeToString() i wielu innych. Każde z tych poleceń ma ściśle określony przez daną specyfikację algorytm działania i powinno zwracać zgodne z nim wyjściowe dane tekstowe.
Przegląd dostępnych poleceń#
Rozszerzenie interfejsu Element#
Idea umożliwiająca tworzenie pewnej części dokumentu na bazie przekazanego tekstu (lub jego odczyt z postaci obiektowej do tekstu) po raz pierwszy pojawiła się wraz z premierą przeglądarki Internet Explorer 4 (wrzesień 1997). Program ten udostępniał kilka dedykowanych właściwości dla interfejsu Element, które pozwalały na odwoływanie się do wewnętrznej i zewnętrznej struktury znacznikowej, jak i samego tekstu. Uproszczoną zasadę działania tych właściwości prezentują poniższe grafiki:
- wszystkie razem

innerHTML
outerHTML
innerText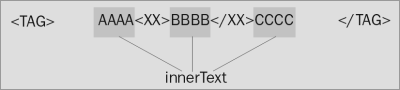
outerText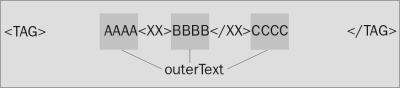
Do tego grona dołączyły także dwie przydatne metody:
insertAdjacentHTML()iinsertAdjacentText()
Dwie pierwsze właściwości są ustandaryzowane i omówię je szczegółowo nieco później. Polecenia Element.innerText i Element.outerText działają w większości przypadków (przy odczycie) identycznie; zwracają połączone dane tekstowe ze wszystkich potomków danego elementu, bez uwzględniania jakichkolwiek znaczników HTML. Różnica staje się widoczna przy zapisywaniu; Element.innerText zastępuje zawartość znajdującą się pomiędzy znacznikami danego elementu nowym tekstem, kiedy Element.outerText zamienia także znaczniki danego elementu. Właściwości Element.innerText i Element.outerText nigdy nie zostały częścią żadnego standardu (dyskusja wciąż trwa) dlatego też ich opis zakańczam właśnie w tym miejscu i odradzam stosowania w swoich projektach.
Metody Element.insertAdjacentHTML() i Element.insertAdjacentText() pozwalają wstawić przekazany tekst w konkretne miejsce względem danego elementu, z tą jednak różnicą, że pierwsza wykonuje dodatkowo parsowanie tekstu. Druga metoda nigdy nie została częścią żadnego standardu (dyskusja wciąż trwa) dlatego też jej opis zakańczam właśnie w tym miejscu i odradzam stosowania w swoich projektach.
Nowe polecenia bardzo szybko przypadły do gustu programistom i do dnia dzisiejszego są bardzo często wykorzystywane w tworzonym przez nich kodzie. Biorąc to pod uwagę, większość konkurencyjnych przeglądarek zaimplementowała je u siebie w całości, włącznie z późniejszym Chrome. Wyjątkiem był Firefox, który wprowadził jedynie Element.innerHTML, Element.outerHTML i Element.insertAdjacentHTML(). Co istotne, gdzieniegdzie występowały drobne różnice między oryginalnym działaniem poleceń z IE, a alternatywnymi wdrożeniami u konkurencji. Nie powinno to nikogo dziwić, w owym czasie nie istniały jeszcze żadne oficjalne standardy DOM.
W3C udostępniło pierwszą specyfikację modelu DOM dopiero w październiku 1998 roku. Niestety, nie standaryzowała ona wyżej wymienionych poleceń. Wiąże się to z tym, że bezpośredni dostęp i manipulacja strukturą znacznikową za pomocą tekstu jest nieco sprzeczne z ideą DOM, zgodnie z którą dokument powinien być traktowany jak drzewo z węzłami (reprezentacja obiektowa), a nie jak łańcuch znakowy zawierający znaczniki. Dopiero trzecie wydanie modelu DOM z kwietnia 2004 roku wprowadziło właściwość Node.textContent, która jest najbardziej zbliżona do właściwości Element.innerText (różnice1, różnice2, różnice3). Technicznie rzecz ujmują właściwość Node.textContent nie zaburza idei DOM, operuje jedynie na wartościach węzłów tekstowych, bez parsowania przekazanego tekstu.
Prace nad nowym standardem HTML5 doprowadziły do stopniowego uporządkowania tej kwestii. Właściwość Element.innerHTML została zdefiniowana w pierwszych wydaniach specyfikacji HTML5 (czerwiec 2008). W późniejszym czasie (luty 2009) do specyfikacji dołączono właściwość Element.outerHTML oraz metodę Element.insertAdjacentHTML(). Ostatecznie grupy W3C i WHATWG utworzyły osobną specyfikację P&S, do której trafiają wszystkie polecenia związane z parsowaniem i serializacją DOM. Całkowita zgodność przeglądarek internetowych z wymaganiami stawianymi przez nowe dokumenty zajmie zapewne sporo czasu. Na dzień dzisiejszy należy liczyć się z mniejszymi lub większymi różnicami w interpretowaniu poszczególnych poleceń przez każdy program, widać to wyraźnie chociażby po właściwości Element.innerHTML (szczególnie przy odczycie).
Rozszerzenie interfejsu Range#
Metoda Range.createContextualFragment() wprowadzona została wraz z premierą pierwszej wersji przeglądarki Firefox (9 listopada 2004) i przez bardzo długi okres czasu nie podlegała żadnej standaryzacji. Następnie większość konkurencyjnych przeglądarek zaimplementowały ją u siebie, włącznie z późniejszym Chrome i IE10.
Ostatecznie metoda znalazła swoje miejsce w początkowej specyfikacji P&S utworzonej przez WHATWG. Z praktycznego punktu widzenia metoda dołączona została do nowego standardu nie bez powodu. Polecenia parsujące, takie jak Element.innerHTML, Element.outerHTML i Element.insertAdjacentHTML() występują tylko i wyłącznie w interfejsie Element. W pewnych sytuacjach ich stosowanie jest uzasadnione i bardzo wygodne, z drugiej jednak strony polecenia te nie mogą być użyte na innych węzłach, np. obiektach typu DocumentFragment, które także są bardzo przydatne. Jedynym sposobem, który pozwala utworzyć i od razu ustawić zawartość fragmentu dokumentu przy użyciu sparsowanego tekstu jest metoda Range.createContextualFragment(). Niestety, zmiana aktualnej zawartości już utworzonego fragmentu dokumentu nowym sparsowanym tekstem wciąż pozostaje niedostępna za pomocą jednego polecenia. Istnieje pewne obejście tego problemu z użyciem właściwości Element.outerHTML, ale sprawdzi się tylko w sytuacji, kiedy jedynym dzieckiem we fragmencie dokumentu będzie obiekt typu Element (nadmiarowe węzły należałoby wcześniej usunąć).
Interfejs Range posiadał już metody Range.cloneContents() i Range.extractContents(), których wynikiem było zwrócenie nowego fragmentu dokumentu, to też pierwotne rozwiązanie Firefoksa trafiło do oficjalnego standardu.
Rozszerzenie interfejsu Text#
Sekcje CDATA wywodzą się z XML-a i mogą występować jedynie w plikach XML (lub jego odmianach). Przeznaczenie oraz szczegóły ich stosowania omówiłem w kursie HTML5 (dział "Szkielet dokumentu - Składnia").
W ujęciu DOM sekcje CDATA stanowią osobny rodzaj węzłów, które definiowane są przez interfejs CDATASection (DOM2, DOM3). Interfejs ten nie posiada żadnych specyficznych poleceń, tak naprawdę dziedziczy jedynie po interfejsie Text.
Prosty przykład:
<script>
var new_XML = new DOMParser().parseFromString("<xml></xml>", "application/xml");
var cdata = new_XML.createCDATASection("Jakieś dane <CDATA> & kolejne dane.");
var serializer = new XMLSerializer();
document.write(cdata); // [object CDATASection]
document.write("<br>");
document.write(cdata.nodeType); // 4
document.write("<br>");
document.write(cdata.length); // 35
alert(cdata.nodeValue); // Jakieś dane <CDATA> & kolejne dane.
alert(serializer.serializeToString(cdata)); // <![CDATA[Jakieś dane <CDATA> & kolejne dane.]]>
</script>Powyższy kod powinien działać we wszystkich aktualnych przeglądarkach, które prawidłowo obsługują standard XML.
Nowy DOM4 jeszcze bardziej próbuje wszystko uprościć. Skoro interfejs CDATASection dziedziczy po interfejsie Text bez wprowadzania własnych poleceń, to nie ma sensu tworzyć dla niego osobnych definicji. DOM4 całkowicie usuwa węzły typu CDATASection, a w ich zastępstwie specyfikacja P&S, pamiętając o kompatybilności wstecznej, dodaje do węzłów tekstowych właściwość Text.serializeAsCDATA, która w razie konieczności pozwala traktować węzły tekstowe jak sekcje CDATA, co z perspektywy DOM będzie istotne jedynie w przypadku serializcji.
Z początku zmiana może wyglądać irracjonalnie, głównie ze względu na fakt, że sekcje CDATA są integralną częścią XML-a. Jednak w praktyce dalej można stosować sekcje CDATA w znacznikowej strukturze plików XML (także XHTML), parser przeglądarki rozpozna takie konstrukcje i odpowiednio je przetworzy. Zamiast osobnego rodzaju węzła otrzymamy po prostu węzeł tekstowy z właściwością Text.serializeAsCDATA ustawianą na boolowską wartość true w przypadku sekcji CDATA, lub wartość false dla standardowego węzła tekstowego. Przy serializacji węzła oznaczonego jako CDATA otrzymamy dane tekstowe tego węzła otoczone ramiami CDATA, coś w rodzaju <![CDATA[dane tekstowe]]>.
Na dzień dzisiejszy wszystkie aktualne przeglądarki działają jeszcze według starszego podejścia. Tak naprawdę nie wiadomo kiedy, i czy w ogóle, nowe zmiany się przyjmą. Istnieje sporo wątpliwości (W3C - Bug 27386, Mozilla - Bug 660660), głównie po stronie programistów chcących zachować kompatybilność z już utworzonym kodem, bez dodatkowego wysiłku z ich strony, chociaż drobne poprawki nie powinny stanowić dla nikogo problemu. Twórcy DOM4 bronią nowego rozwiązania i trudno się z nimi nie zgadzać. Ponowne zdefiniowanie interfejsu CDATASection wymagałoby wprowadzenia wielu poprawek w już istniejącej dokumentacji, jeszcze bardziej ją rozwlekając. Sytuacja jest patowa, a oliwy do ognia dodaje jeszcze silnik Servo, dla którego autorzy nie zamierzają definiować węzłów typu CDATASection.
Przestrzeganie poprawności składniowej (dobrego sformułowania)#
Ścisła kontrola danych wejściowych dla parsowania i serializacji będzie dotyczyła jedynie dokumentów XML, dla których wystąpienie najmniejszego błędu należałoby w jakiś sposób zasygnalizować (np. poprzez zrzucenie błędu). Wstępne nakreślenie tego zagadnienia opisałem już w następujących miejscach:
- "Podstawy - Rodzaje dokumentów - Poprawność dokumentu" (kurs DOM)
- "Szkielet dokumentu - Składnia - Zgodność ze standardami" (kurs HTML5)
- "Podstawy - Poprawność dokumentu" (kurs HTML)
W przypadku parsowania aktualne implementacje są zgodne z wymogami poszczególnych specyfikacji, dotyczy to standardowego sposobu wczytywania dokumentu (np. poprzez otworzenie nowej karty), jak i wszystkich dodatkowych API dostępnych z poziomu skryptu, np. DOMParser.parseFromString() czy Element.insertAdjacentHTML(). Żaden błąd się nie prześlizgnie i parser zakończy pracę na pierwszej napotkanej nieścisłości:
<script>
var newDoc = document.implementation.createDocument(null, "root", null);
try{
newDoc.firstChild.innerHTML = "<p>fsfa"; // brak znacznika zamykającego
}
catch(e){
document.write("Niepoprawne dane wejściowe dla innerHTML:" + "<br>");
document.write(e);
}
try{
newDoc.firstChild.insertAdjacentHTML("afterbegin", "<p>fsfa"); // brak znacznika zamykającego
}
catch(e){
document.write("<br><br>" + "Niepoprawne dane wejściowe dla insertAdjacentHTML():" + "<br>");
document.write(e);
}
</script>Serializacja wymaga osobnego omówienia. Wejściem dla serializacji jest sparsowana struktura znacznikowa, czyli, przynajmniej teoretycznie, błędy nie powinny występować. Istnieją jednak takie polecenia DOM, które nie sprawdzają wszystkich wymogów XML-a. Dotyczy to poleceń tworzących węzły, np. Document.createComment() czy Document.createElement(), które po utworzeniu bezproblemowo wstawimy do aktualnego drzewa węzłów XML. Zgodnie z wytycznymi specyfikacji P&S serializacja takiego drzewa węzłów dla poszczególnych poleceń wygląda następująco:
Element.innerHTMLiElement.outerHTML(przy odczycie) - dobre sformułowanie jest wymaganeXMLSerializer.serializeToString()- dobre sformułowanie nie jest wymagane
Na dzień dzisiejszy wszystkie przeglądarki internetowe nie wymagają poprawności składniowej przy serializacji XML-a. Wciąż trwa dyskusja (W3C - Bug 23460), czy nie należałoby zmienić wymagań samej specyfikacji. Jeśli sytuacja się utrzyma, to prawdopodobnie jedynym sposobem na bezpośrednie sprawdzenie poprawności drzewa węzłów XML wprost z kodu będzie jego serializacja (nieczuła na błędy) i ponowne sparsowanie (czułe na błędy).
Prosty przykład:
<script>
var serializer = new XMLSerializer();
var newDoc = document.implementation.createDocument(null, null, null);
var newEl = newDoc.createElement("div:"); // niedozwolony ":" w nazwie lokalnej
newEl.appendChild(newDoc.createComment("--")); // niedozwolone "--" w danych tekstowych
// Te serializacje powinny zrzucać błąd
alert(newEl.innerHTML);
alert(newEl.outerHTML);
// Te serializacje nie powinny zrzucać błędu
alert(serializer.serializeToString(newDoc));
alert(serializer.serializeToString(newEl));
// Najpierw serializacja (nie zrzuca błędu) a potem parsowanie (zrzuca błąd)
newEl.innerHTML = newEl.outerHTML;
</script>Warto przypomnieć, że atrybuty nie są już węzłami, dlatego próba bezpośredniej serializacji obiektu atrybutu metodą XMLSerializer.serializeToString() również powinna zrzucać błąd. Dotyczy to każdego innego typu danych, który nie jest węzłem, a który został przekazany do serializującej metody:
<script>
var serializer = new XMLSerializer();
var newAttr = document.createAttribute("id");
newAttr.value = "identyfikator";
try{
var returnValue = serializer.serializeToString(newAttr);
document.write("Błąd nie został zrzucony:" + "<br>");
document.write(typeof returnValue + "<br>");
document.write(returnValue + "<br>");
document.write(returnValue.length + "<br>");
}
catch(e){
document.write("<br><br>" + "Niepoprawne dane wejściowe (atrybut) dla serializeToString():" + "<br>");
document.write(e);
}
try{
serializer.serializeToString("");
}
catch(e){
document.write("<br><br>" + "Niepoprawne dane wejściowe (pusty łańcuch) dla serializeToString():" + "<br>");
document.write(e);
}
</script>Także i w tym przypadku aktualne przeglądarki internetowe działają niezgodnie z wymaganiami, wszystkie zezwalają na bezpośrednie przekazywanie atrybutów, z tym że Firefox i Chrome zawsze zwraca dla nich pusty łańcuch znakowy, kiedy IE11 zwraca wartość atrybutu.
Względy bezpieczeństwa#
Należy zwracać szczególną uwagę w przypadku parsowania danych tekstowych pochodzących z niezaufanych źródeł, gdyż wiąże się to z potencjalnym ryzykiem wstrzyknięcie niebezpiecznego kodu do naszej strony lub aplikacji. Uwaga będzie dotyczyła głównie właściwości Element.innerHTML, która przez wielu początkujących programistów jest wykorzystywana jedynie do zmiany danych tekstowych.
Przeanalizujmy najpierw nieszkodliwy przykład:
<script>
var source1 = "Marian";
document.documentElement.innerHTML = source1; // bez zagrożenia w tym przypadku
var source2 = "<script>alert('Jestem nieznośnym komunikatem alertowym!')<\/script>";
document.documentElement.innerHTML = source2; // bez zagrożenia w tym przypadku
</script>W pierwszym przypadku zmienna source1 nie zawiera żadnych wykonywalnych danych, dlatego polecenie było nieszkodliwe. W drugim przypadku zmienna source2 posiada już kod wykonywalny (w postaci znacznika skryptu) i może wyglądać jak atak typu XSS # (cross-site scripting) [WikiEN|WikiPL]. Na szczęście specyfikacja HTML5 nie zezwala na tego typu zachowanie. Elementy <script> posiadają specjalny stan włączenia/wyłączenia oraz kilka innych pośredniczących flagi i stanów, od których uzależnione jest wykonywanie skryptów definiowane przez algorytm przygotowania skryptu i wykonania bloku skryptu. Istnieje także flaga skryptowania, której stan wpływa na sposób przetwarzania elementów <noscript>.
Z praktycznego punktu widzenia skrypty nigdy nie będą uruchamiane:
- W dokumentach bez kontekstu przeglądania, tj. utworzonych poleceniami
XMLHttpRequest.responseXML,DOMParser.parseFromString(),XSLTProcessor.transformToDocument,new Document(),DOMImplementation.createDocument()iDOMImplementation.createHTMLDocument()(szczegóły). - W przypadku metody
Element.insertAdjacentHTML()oraz właściwościElement.innerHTMLiElement.outerHTML(szczegóły). - Nawet w sytuacji, kiedy utworzone zostały za pomocą powyższych poleceń i wstawione do dokumentu zawierającego kontekst przeglądania.
- Przy próbie ponownego wykorzystania już wykonanych skryptów (np. usuwając je i wstawiając do dokumentu zawierającego kontekst przeglądania).
Warto jednak podkreślić, że uruchamianie skryptów domyślnie nie zostanie zablokowane dla:
- Metod
document.write()idocument.writeln(). - Metod
Document.createElement(),Document.createElementNS(),Range.createContextualFragment()iXSLTProcessor.transformToFragment(), których rezultat wstawimy do jakiegoś dokumentu zawierającego kontekst przeglądania.
Prosty przykład:
<!DOCTYPE html>
<body>
<noscript><p>test1<p>test2</noscript>
<script>
function prepareScript(script, data){
script.textContent = "document.write('" + data + "<br>" + "');";
}
function prepareCombo(data){
return "<body><script>document.write('" + data + "<br>" + "');<\/script>"
+ "<noscript><p>test1<p>test2</noscript></body>";
}
function testNosrcipt(desc, noscript){
document.write(desc + "<br>");
document.write("noscript.childNodes.length: " + noscript.childNodes.length + "<br>");
document.write("noscript.childNodes[0]: " + noscript.childNodes[0] + "<br>");
document.write("noscript.childNodes[1]: " + noscript.childNodes[1] + "<br>");
}
var script = document.createElement("script");
prepareScript(script, "Skrypt utworzony metodą Document.createElement() i dodany do elementu DIV poza aktualnym dokumentem.");
var div = document.createElement("div");
div.appendChild(script); // brak wykonania
prepareScript(script, "Skrypt utworzony metodą Document.createElement() i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(div.firstChild); // wykonanie
prepareScript(script, "Ponowne użycie już wykonanego skrypty utworzonego metodą Document.createElement().");
document.body.appendChild(script); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT w aktualnym dokumencie z kontekstem przeglądania:", document.body.firstElementChild);
document.write("<br>");
var frag = document.createRange().createContextualFragment(prepareCombo("Skrypt utworzony metodą Range.createContextualFragment().")); // brak wykonania
prepareScript(frag.firstChild, "Skrypt utworzony metodą Range.createContextualFragment() i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(frag.firstChild); // wykonanie
prepareScript(document.body.lastChild, "Ponowne użycie już wykonanego skrypty utworzonego metodą Range.createContextualFragment().");
document.body.appendChild(document.body.lastChild); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT utworzonego metodą Range.createContextualFragment():", frag.firstChild);
document.write("<br>");
div.innerHTML = prepareCombo("Skrypt utworzony właściwością Element.innerHTML."); // brak wykonania
prepareScript(div.firstChild, "Skrypt utworzony właściwością Element.innerHTML i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(div.firstChild); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT utworzonego właściwością Element.innerHTML:", div.firstChild);
document.write("<br>");
div.innerHTML = "<p>";
div.firstChild.outerHTML = prepareCombo("Skrypt utworzony właściwością Element.outerHTML."); // brak wykonania
prepareScript(div.firstChild, "Skrypt utworzony właściwością Element.outerHTML i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(div.firstChild); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT utworzonego właściwością Element.outerHTML:", div.firstChild);
document.write("<br>");
div.innerHTML = "";
div.insertAdjacentHTML("afterbegin", prepareCombo("Skrypt utworzony metodą Element.insertAdjacentHTML().")); // brak wykonania
prepareScript(div.firstChild, "Skrypt utworzony metodą Element.insertAdjacentHTML() i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(div.firstChild); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT utworzonego metodą Element.insertAdjacentHTML():", div.firstChild);
document.write("<br>");
var doc = new DOMParser().parseFromString(prepareCombo("Skrypt utworzony metodą DOMParser.parseFromString()."), "text/html"); // brak wykonania
prepareScript(doc.body.firstChild, "Skrypt utworzony metodą DOMParser.parseFromString() i dodany do aktualnego dokumentu z kontekstem przeglądania.");
document.body.appendChild(doc.body.firstChild); // brak wykonania
testNosrcipt("Sprawdzenie przetworzenia elementu NOSCRIPT utworzonego metodą DOMParser.parseFromString():", doc.body.firstChild);
</script>
</body>Istnieją jednak sposoby pozwalające na wstrzyknięcie wykonywalnego kodu bez użycia elementów skryptu, więc ciągle istnieje zagrożenie w przypadku danych tekstowych, nad którymi nie mamy żadnej kontroli:
<script>
var source = "<img src='fake' onerror='alert(1)'>";
document.documentElement.innerHTML = source; // kod zostanie automatycznie wykonany
</script>Z tego powodu odradza się używania właściwości Element.innerHTML w przypadku wstawiania lub modyfikacji zwykłego tekstu, w zamian należy używać polecenia Node.textContent (ewentualnie jego odpowiedników), które przekazaną zawartość traktują jak surowy tekst (raw text), bez parsowania.
Oczywiście prezentowane uwagi będą dotyczyły każdego innego polecenia parsującego udostępnianego przez przeglądarki internetowe, chociaż w ich przypadku mogą występować inne reguły i zachowania odnośnie bezpieczeństwa, dlatego należy samodzielnie przeanalizować poszczególne specyfikacje pod kątem konkretnego polecenia.